
平臺搭建---Hive使用介紹
雖然資料儲存的方式與傳統資料庫不一樣,但使用的方式跟mysql是很像的,如何沒有時間學習怎麼用可以先按傳統資料的語法規則來,出了問題再去查細節。
文章來源
Hive簡介
Hive 是建立在 Hadoop 上的資料倉庫基礎構架。它提供了一系列的工具,可以用來進行資料提取轉化載入(ETL),這是一種可以儲存、查詢和分析儲存在 Hadoop 中的大規模資料的機制。Hive 定義了簡單的類 SQL 查詢語言,稱為 HQL,它允許熟悉 SQL 的使用者查詢資料。同時,這個語言也允許熟悉 MapReduce 開發者的開發自定義的 mapper 和 reducer 來處理內建的 mapper 和 reducer 無法完成的複雜的分析工作。
首先,我來說說什麼是hive(What is Hive?),請看下圖:
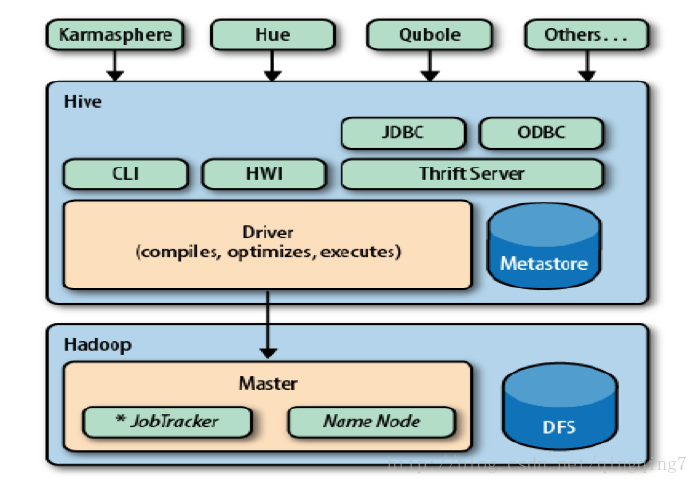
Hive構建在Hadoop的HDFS和MapReduce之上,用於管理和查詢結構化/非結構化資料的資料倉庫。
- 使用HQL作為查詢介面
- 使用HDFS作為底層儲存
- 使用MapReduce作為執行層
Hive的應用,如下圖所示
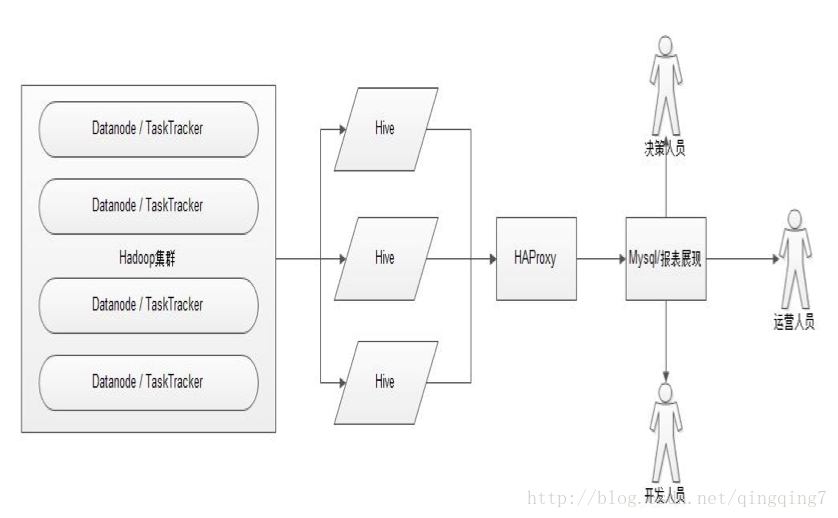
這裡叢集搭建Hive時用到了HA,最後用HAProxy來做代理。
結構描述
Hive 的結構可以分為以下幾部分:
- 使用者介面:包括 CLI, Client, WU
- 元資料儲存。通常是儲存在關係資料庫如 mysql, derby 中
- 直譯器、編譯器、優化器、執行器
- Hadoop:用 HDFS 進行儲存,利用 MapReduce 進行計算
1、 使用者介面主要有三個:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 啟動的時候,會同時啟動一個 Hive 副本。Client 是 Hive 的客戶端,使用者連線至 Hive Server。在啟動 Client 模式的時候,需要指出 Hive Server 所在節點,並且在該節點啟動 Hive Server。 WUI 是通過瀏覽器訪問 Hive。
2、 Hive 將元資料儲存在資料庫中,如 mysql、derby。Hive 中的元資料包括表的名字,表的列和分割槽及其屬性,表的屬性(是否為外部表等),表的資料所在目錄等。
3、 直譯器、編譯器、優化器完成 HQL 查詢語句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃儲存在 HDFS 中,並在隨後有 MapReduce 呼叫執行。
Hive和普通DB的異同
| Hive | RDBMS | |
|---|---|---|
| 查詢語句 | HQL | SQL |
| 資料儲存 | HDFS | Raw Device or Local FS |
| 索引 | 1.0.0版本支援 | 有 |
| 執行延遲 | 高 | 低 |
| 處理資料規模 | 大(或海量) | 小 |
| 執行 | MapReduce | Excutor |
元資料
Hive 將元資料儲存在 RDBMS 中,一般常用的有MYSQL和DERBY。由於DERBY只支援單客戶端登入,所以一般採用MySql來儲存元資料。
資料儲存
首先,Hive 沒有專門的資料儲存格式,也沒有為資料建立索引,使用者可以非常自由的組織 Hive 中的表,只需要在建立表的時候告訴 Hive 資料中的列分隔符和行分隔符,Hive 就可以解析資料。
其次,Hive 中所有的資料都儲存在 HDFS 中,Hive 中包含以下資料模型:Table,External Table,Partition,Bucket。
- Hive 中的 Table 和資料庫中的 Table 在概念上是類似的,每一個 Table 在 Hive 中都有一個相應的目錄儲存資料。例如,一個表 app,它在 HDFS 中的路徑為:/ warehouse /app,其中,wh是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的資料倉庫的目錄,所有的 Table 資料(不包括 External Table)都儲存在這個目錄中。
安裝hive後,會在hdfs上建立如/user/hive/warehouse/這樣的的屬於hive的資料夾;如果我們在hive中建立資料庫,則會在warehouse下產生一個子目錄,形如/user/hive/warehouse/xxx.db;如果接著在該資料庫中建立一個表,則會繼續產生子目錄,形如/user/hive/warehouse/xxx.db/yyyyyy; - Partition 對應於資料庫中的 Partition 列的密集索引,但是 Hive 中 Partition 的組織方式和資料庫中的很不相同。在 Hive 中,表中的一個 Partition 對應於表下的一個目錄,所有的 Partition 的資料都儲存在對應的目錄中。例如:xiaojun 表中包含 dt 和 city 兩個 Partition,則對應於 dt = 20100801, ctry = US 的 HDFS 子目錄為:/ warehouse /app/dt=20100801/ctry=US;對應於 dt = 20100801, ctry = CA 的 HDFS 子目錄為;/ warehouse /app/dt=20100801/ctry=CA
這裡對應了Hive將資料分塊的方式,它是以某一個變數的取值來分枝的,一個值對應一個枝,即對應一個目錄,,然後再用下一個變數進一步分枝,即進一步分出更多目錄;
如果建立表時有分割槽,則會在目錄中產生分割槽標識來區分的檔案,形如/user/hive/warehouse/xxx.db/yyyyyy/date=20180521,檔案中即儲存著相關的內容,以一定的分隔符區分欄位; - Buckets 對指定列計算 hash,根據 hash 值切分資料,目的是為了並行,每一個 Bucket 對應一個檔案。將 user 列分散至 32 個 bucket,首先對 user 列的值計算 hash,對應 hash 值為 0 的HDFS 目錄為:/ warehouse /app/dt =20100801/ctry=US/part-00000;hash 值為 20 的 H
DFS 目錄為:/ warehouse /app/dt =20100801/ctry=US/part-00020
如果指定Buckets,則date=20180521不是檔案,而是檔名,然後再它的下級會產生以某一列值的hash 值為區分的檔案,形如/user/hive/warehouse/xxx.db/yyyyyy/date=20180521/part-00000,檔案中即儲存著相關的內容 - External Table 指向已經在 HDFS 中存在的資料,可以建立 Partition。它和 Table 在元資料的組
織上是相同的,而實際資料的儲存則有較大的差異。
Table (內部表)的建立過程和資料載入過程(這兩個過程可以在同一個語句中完成),在載入資料的過程中,實際資料會被移動到資料倉庫目錄中;之後對資料對訪問將會直接在資料倉庫目錄中完成。刪除表時,表中的資料和元資料將會被同時刪除。
External Table 只有一個過程,載入資料和建立表同時完成(CREATE EXTERNAL TABLE …LOCATION),實際資料是儲存在 LOCATION 後面指定的 HDFS 路徑中,並不會移動到資料倉庫目錄中。當刪除一個 External Table 時,僅刪除hive的元資料,不會刪除hdfs上對應的檔案。
Hive的安裝部署
下載安裝軟體
環境配置
安裝hive的前提,必需安裝好hadoop環境,可以參考我之前Hadoop社群版搭建,先搭建好hadoop環境;接下來我們開始配置hive。
環境變數
sudo vi /etc/profile
HIVE_HOME=/home/hadoop/source/hive-0.14.0
PATH=$HIVE_HOME/bin
export HIVE_HOME
hive-site.xml
<configuration>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.execute.setugi</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!-- metadata database connection configuration -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.211.55.18:3306/hive?useUnicode=true&characterEncoding=UTF-8&createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>10.211.55.18</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
<!-- configure hwi war package location -->
<!--
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-0.14.0.war</value>
<description>This is the WAR file with the jsp content for Hive Web Interface</description>
</property>
-->
</configuration>
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/home/hadoop/source/hadoop-2.5.1
啟動
[[email protected] ~]$ hive
會顯示如下的啟動過程
Logging initialized using configuration in file:/home/hadoop/source/hive-0.14.0/conf/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/source/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.
7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/source/hive-0.14.0/lib/hive-jdbc-0.14.0-standalone.jar!/org/slf4j/
impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive>
至此,hive配置完成。
注: 由於配置的是mysql驅動,所以需要把mysql的驅動包放到$HIVE_HOME/lib下
退出hive
ctrl+c無意中弄到的,不知道是不是這個
檢視hive版本 沒有好辦法,可以去hive目錄下的lib資料夾下檢視jar包的版本
檢視hbase版本 方法:直接用hbase shell命令進入shell的時候就會顯示版本號
Hive的基本操作
Create Table
介紹
-
CREATE TABLE 建立一個指定名字的表。如果相同名字的表已經存在,則丟擲異常;使用者可以用IF NOT EXIST 選項來忽略這個異常。
-
EXTERNAL 關鍵字可以讓使用者建立一個外部表,在建表的同時指定一個指向實際資料的路徑(LOCATION),Hive 建立內部表時,會將資料移動到資料倉庫指向的路徑;若建立外部表,僅記錄資料所在的路徑,不對資料的位置做任何改變。在刪除表的時候,內部表的元資料和資料會被一起刪除,而外部表只刪除元資料,不刪除資料。
-
LIKE 允許使用者複製現有的表結構,但是不復制資料。
-
使用者在建表的時候可以自定義 SerDe 或者使用自帶的 SerDe。如果沒有指定 ROW FORMAT 或者ROW FORMAT DELIMITED,將會使用自帶的 SerDe。在建表的時候,使用者還需要為表指定列,使用者在指定表的列的同時也會指定自定義的 SerDe,Hive 通過 SerDe 確定表的具體的列的資料。
-
如果檔案資料是純文字,可以使用 STORED AS TEXTFILE。如果資料需要壓縮,使用 STORED AS SEQUENCE 。
-
有分割槽的表可以在建立的時候使用 PARTITIONED BY 語句。一個表可以擁有一個或者多個分割槽,每一個分割槽單獨存在一個目錄下。而且,表和分割槽都可以對某個列進行 CLUSTERED BY 操作,將若干個列放入一個桶(bucket)中。也可以利用SORT BY 對資料進行排序。這樣可以為特定應用提高效能。
-
表名和列名不區分大小寫,SerDe 和屬性名區分大小寫。表和列的註釋是字串
-
SerDe是Serialize/Deserilize的簡稱,用於序列化和反序列化。
-
STORED AS TEXTFILE:預設格式,資料不作壓縮,磁碟開銷大,資料解析開銷大。可結合Gzip和Bzip使用(系統自動檢查,執行查詢時自動解壓),但使用這種方式,hive不會對資料進行切分,從而無法對資料進行並行操作。
-
STORED AS SEQUENCE:Hadoop API,提供一種二進位制檔案支援,其具有使用方便,可分割可壓縮的特點。SequenceFile支援三種壓縮選擇:NONE、RECORD、BLOCK,RECORD壓縮率低,一般建議使用BLOCK壓縮。
語法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[
[ROW FORMAT row_format] [STORED AS file_format]
| STORED BY 'storage.handler.class.name' [ WITH SERDEPROPERTIES (...) ]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement] CREATE [EXTERNAL] TABLE [IF NO
T EXISTS] table_name
LIKE existing_table_name
[LOCATION hdfs_path]
data_type
: primitive_type
| array_type
| map_type
| struct_type
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| STRING
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
row_format
: DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value,
...)]
file_format:
: SEQUENCEFILE
| TEXTFILE
| RCFILE (Note: only available starting with 0.6.0)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
基本示例
1、如果一個表已經存在,可以使用if not exists
2、create table user(id int,cont string) row format delimited fields terminated by ‘\005’ stored as textfile; terminated by:關於來源的文字資料的欄位間隔符
3、如果要將自定義間隔符的檔案讀入一個表,需要通過建立表的語句來指明輸入檔案間隔符,然後load data到這個表。
4、Shops資料庫常用間隔符的讀取 我們的常用間隔符一般是Ascii碼5,Ascii碼7等。在hive中Ascii碼5用’\005’表示, Ascii碼7用’\007’表示,依此類推。
5、裝載資料檢視一下:Hadoop fs -ls LOAD DATA INPATH ‘/user/admin/user/a.txt’ OVERWRITE IN TO TABLE user;
6、如果使用external建表和普通建表區別:前者存放元資料,刪除後文件系統中的資料不會刪除,後者會直接刪除檔案系統中的資料
建立分割槽
HIVE的分割槽通過在建立表時啟用partition by實現,如下面的示例所示;用來partition的維度並不是實際資料的某一列,具體分割槽的標誌是由插入內容時給定的,如insert into test partition(dt='2018-08-15') select * from df_Temp。分割槽標誌在查詢結果中也是一列,在hdfs上則對應一個資料夾;當要查詢某一分割槽的內容時可以採用where語句,形似where tablename.partition_key > a來實現。 建立含分割槽的表。 命令原型:
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
如建表:
CREATE TABLE c02_clickstat_fatdt1
(yyyymmdd string,
id INT,
ip string,
country string,
cookie_id string,
page_id string,
clickstat_url_id string,
query_string string,
refer string
)PARTITIONED BY(dt STRING)
row format delimited fields terminated by '\005' stored as textfile;
create table test(
fullcode string,
fullname string,`date` string
) partitioned by (dt string) stored as textfile
裝載資料:
LOAD DATA INPATH '/user/admin/SqlldrDat/CnClickstat/20131101/19/clickstat_gp_fatdt0/0' OVERWRITE INTO TA
BLE c02_clickstat_fatdt1
PARTITION(dt='20131101');
訪問某個分割槽:
SELECT count(*) FROM c02_clickstat_fatdt1 a
WHERE a.dt >= '20131101' AND a.dt < '20131102';
指定Location位置
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '<hdfs_location>';
複製一個空表:
CREATE TABLE empty_key_value_store
LIKE key_value_store;
hive分桶的原理
hive分桶的作用
hive分桶和分割槽的區別
hive分桶的操作
行分隔符
ASCII碼值表
Char列就是我們平時看到的分隔符比如“|”,比如“,”等,Hex就是對應的ASCII碼對應的十六進位制形式,也就是我們平時建hive表時"FIELDS TERMINATED BY ‘\054’"時by後面的。
Alter Table
使用者可以使用ALTER DATABASE命令為某個資料庫的DBPROPERTIES設定鍵-值對屬性值,來描述這個資料庫的屬性資訊;也可以使用該命令修改資料庫的使用者或許可權,但是資料庫的其他元資料資訊都是不可以更改的,包括資料庫名和資料庫所在的目錄位置。
新增分割槽
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'l
ocation2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
例子:
ALTER TABLE c02_clickstat_fatdt1 ADD
PARTITION (dt='20131202') location '/user/hive/warehouse/c02_clickstat_fatdt1/part20131202'
PARTITION (dt='20131203') location '/user/hive/warehouse/c02_clickstat_fatdt1/part20131203';
刪除分割槽
ALTER TABLE table_name DROP partition_spec, partition_spec,...
例子:
ALTER TABLE c02_clickstat_fatdt1 DROP PARTITION (dt='20101202');
重命名錶
ALTER TABLE table_name RENAME TO new_table_name
這個命令可以讓使用者為表更名。資料所在的位置和分割槽名並不改變。換而言之,老的表名並未“釋放”,對老表的更改會改變新表的資料。
修改列屬性
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment]
[FIRST|AFTER column_name]
這個命令可以允許改變列名、資料型別、註釋、列位置或者它們的任意組合。
新增/替換列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
ADD是代表新增一欄位,欄位位置在所有列後面(partition列前);REPLACE則是表示替換表中所有欄位。
例子:
hive> desc xi;
OK
id
int
cont string
dw_ins_date string
Time taken: 0.061 seconds
hive> create table xibak like xi;
OK
Time taken: 0.157 seconds
hive> alter table xibak replace columns (ins_date string);
OK
Time taken: 0.109 seconds
hive> desc xibak;
OK
ins_date
string
建立檢視
CREATE VIEW [IF NOT EXISTS] view_name [ (column_name [COMMENT column_comment], ...) ]
[COMMENT view_comment]
[TBLPROPERTIES (property_name = property_value, ...)]
AS SELECT ...
注:檢視關鍵字,檢視是隻讀的,不能用LOAD/INSERT/ALTER
顯示錶
查看錶名:
SHOW TABLES;
查看錶名,部分匹配:
SHOW TABLES 'page.*';
SHOW TABLES '.*view';
檢視某表的所有Partition,如果沒有就報錯:
SHOW PARTITIONS page_view;
檢視某表結構:
DESCRIBE invites;
檢視分割槽內容:
SELECT a.foo FROM invites a WHERE a.ds=‘2012-08-15’;
檢視有限行內容,同Greenplum,用limit關鍵詞:
SELECT a.foo FROM invites a limit 3;
查看錶分割槽定義:
DESCRIBE EXTENDED page_view PARTITION (ds='2013-08-08');
Hive中資料匯入匯出
載入
HIVE裝載資料沒有做任何轉換載入到表中的資料只是進入相應的配置單元表的位置移動資料檔案。純載入操作複製/移動操作。
語法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=v
al2 ...)]
Load 操作只是單純的複製/移動操作,將資料檔案移動到 Hive 表對應的位置。如:從本地匯入資料到表格並追加原表
LOAD DATA LOCAL INPATH `/tmp/pv_2013-06-08_us.txt` INTO TABLE c02 PARTITION(date='2013-06-08', country
='US')
從本地匯入資料到表格並追加記錄:
LOAD DATA LOCAL INPATH './examples/files/kv1.txt' INTO TABLE pokes;
從hdfs匯入資料到表格並覆蓋原表:
LOAD DATA INPATH '/user/admin/SqlldrDat/CnClickstat/20131101/18/clickstat_gp_fatdt0/0' INTO table c02_click
stat_fatdt1 OVERWRITE PARTITION (dt='20131201');
關於來源的文字資料的欄位間隔符 如果要將自定義間隔符的檔案讀入一個表,需要通過建立表的語句來指明輸入檔案間隔符,然後load data到這個表就ok了。
插入
INSERT語法
Standard syntax:
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement
Hive extension (multiple inserts):
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ...] select_statement2] ...
Hive extension (dynamic partition inserts):
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement
spark中插入資料到hive表
#-*-coding:utf-8-*-
from pyspark import SparkContext
from pyspark.sql import SparkSession
import pandas as pd
if __name__=="__main__":
sc=SparkContext(appName='myApp')
spark=SparkSession.builder.enableHiveSupport().getOrCreate()
# create table test(fullcode string,fullname string,`date` string) partitioned by (dt string) stored as textfile
df=spark.createDataFrame([("002","地下","2018-08-15T13:05:00")],("fullcode","fullname","date"))
df.show()
"""
+--------+--------+-------------------+
|fullcode|fullname| date|
+--------+--------+-------------------+
| 002| 地下|2018-08-15T13:05:00|
+--------+--------+-------------------+
"""
df.registerTempTable("df_Temp")
sql = "use app"
spark.sql(sql)
sql = "insert into test partition(dt='2018-08-15') select * from df_Temp"
spark.sql(sql)
sql = "select * from app.test"
df2=spark.sql(sql)
df2.show()
"""
+--------+--------+-------------------+----------+
|fullcode|fullname| date| dt|
+--------+--------+-------------------+----------+
| 002| 地下|2018-08-15T13:05:00|2018-08-15|
| 001| 天上|2018-08-15T23:04:00|2018-08-15|
+--------+--------+-------------------+----------+
"""
spark中寫入資料到hive表
(df.write.format('parquet')
.bucketBy(100, 'year', 'month')
.sortBy('day')
.mode("overwrite")
.saveAsTable('sorted_bucketed_table'))
hive表格按分割槽儲存的靜態分割槽和動態分割槽之分
靜態分割槽就是人為指定資料儲存到哪個分割槽,此時dataframe中不包含分割槽欄位,而是人為指定。如下
df = hiveContext.createDataFrame([("002","地下","2018-08-15T13:05:00"),("003","地下","2018-08-16T13:05:00"),("004","地下","2018-08-16T13:05:00")],("fullcode","fullname","date"))
df.registerTempTable("df_Temp")
sql ="use test"#需要先指定資料庫,好像不能在後面用test.test表示,可能是版本問題;
hiveContext.sql(sql)
sql = "insert overwrite table test partition(dt='2018-08-15') select * from df_Temp"
hiveContext.sql(sql)
利用靜態分割槽的形式,插入資料正常
動態分割槽是hive自動根據dataframe中分割槽欄位的值將資料寫到對應的分割槽中,此時dataframe中需要人為的多加一個分割槽欄位,如下
df = hiveContext.createDataFrame([("002","地下","2018-08-15T13:05:00","2018-08-10"),("003","地下","2018-08-16T13:05:00","2018-08-11"),("004","地下","2018-08-16T13:05:00","2018-08-12")],("fullcode","fullname","date","dt"))
df.registerTempTable("df_Temp")
sql ="use test"
hiveContext.sql(sql)
sql = "set hive.exec.dynamic.partition.mode=nonstrict"#要不程式中設定,好坑,應該可以在什麼地方配置。
hiveContext.sql(sql)
sql = "insert overwrite table test partition(`dt`) select * from df_Temp"
hiveContext.sql(sql)
對比insert overwrite 和insert into 的差別:
3天的資料共847500000條,在原表無資料的情況下,用insert overwrite table test插入hive表,用時23分中
在3天的資料已經存在hive表的情況下,改成insert into table test,將同樣的3天資料插入到hive中,用時25 minute,總資料條數變成1695000000。在這種情況下原資料不會被刪除,但其實用時並沒有大量增加。
直接利用dataframe儲存資料,dataframe中也需要人為的多加一個分割槽欄位
df = hiveContext.createDataFrame([("002","地下","2018-08-15T13:05:00","2018-08-10"),("003","地下","2018-08-16T13:05:00","2018-08-11"),("004","地下","2018-08-16T13:05:00","2018-08-12")],("fullcode","fullname","date","dt"))
df.write.saveAsTable("test.test",mode='append',partionBy='dt')
但是在實踐中發現在spark1.6.3版本中,用上面的方式將dataframe中的資料寫入hive分割槽表中,hive中的建表語句(create table test(fullcode string,fullname string,date string) partitioned by (dt string) stored as textfile;),資料可以寫成功hive表,但是分割槽沒了。這個好生奇怪。
後來發現是spark版本的問題,至少在spark2.2.1中是可以按照上面的方式直接儲存的。
#-*-coding:utf-8-*-
#import sys
#reload(sys)
#sys.setdefaultencoding('utf8')
from pyspark import SparkContext
from pyspark.sql import SparkSession
if __name__=="__main__":
sc=SparkContext(appName='myApp')
spark=SparkSession.builder.enableHiveSupport().getOrCreate()
# create table testDataFrame(fullcode string,fullname string,`date` string) partitioned by (dt string) stored as textfile
df=spark.createDataFrame([("002","地下","2018-08-15T13:05:00","2018-08-10"),("003","地下","2018-08-16T13:05:00","2018-08-11"),("004","地下","2018-08-16T13:05:00","2018-08-12")],("fullcode","fullname","date","dt"))
df.show()
sql = "use test"
spark.sql(sql)
df.write.saveAsTable("testDataFrame",mode='append',partionBy='dt')
插入到本地檔案
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/pv_gender_sum'
SELECT pv_gender_sum.*
FROM pv_gender_sum;
Insert時,from子句既可以放在select子句後,也可以放在insert子句前,下面兩句是等價的
hive> FROM invites a INSERT OVERWRITE TABLE events SELECT a.bar, count(*) WHERE a.foo > 0 GROUP BY a.bar;
hive> INSERT OVERWRITE TABLE events SELECT a.bar, count(*) FROM invites a WHERE a.foo > 0 GROUP BY a.bar;
需要注意的是,hive沒有直接插入一條資料的sql,不過可以通過其他方法實現: 假設有一張表B至少有一條資料,我們想向表A(int,string)中插入一條資料,可以用下面的方法實現:
from B insert table A select 1,‘abc’ limit 1;
我覺得Hive好像不能夠插入一個記錄,因為每次你寫INSERT語句的時候都是要將整個表的值OVERWRITE。我想這個應該是與Hive的storage layer是有關係的,因為它的儲存層是HDFS,插入一個數據要全表掃描,還不如用整個表的替換來的快些。
注:Hive不支援一條一條的用sert語句進行插入操作,也不支援update操作。資料是以load的方式載入到建立好的表中。資料一旦匯入則不會修改。要麼drop掉整個表,要麼建立新表,匯入新的資料。
WRITE語法
Standard syntax:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ...
Hive extension (multiple inserts):
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
匯出檔案到本地:
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
也可以利用linux系統功能實現如
hive> insert overwrite local directory '/home/wyp/wyp'
> select * from wyp;
匯出檔案到HDFS:
INSERT OVERWRITE DIRECTORY '/user/admin/SqlldrDat/CnClickstat/20131101/19/clickstat_gp_fatdt0/0' SELECT
a.* FROM c02_clickstat_fatdt1 a WHERE dt=’20131201’;
一個源可以同時插入到多個目標表或目標檔案,多目標insert可以用一句話來完成:
FROM src
INSERT OVERWRITE TABLE dest1 SELECT src.* WHERE src.key < 100
INSERT OVERWRITE TABLE dest2 SELECT src.key, src.value WHERE src.key >= 100 and src.key < 200
INSERT OVERWRITE TABLE dest3 PARTITION(ds='2013-04-08', hr='12') SELECT src.key WHERE src.key >= 200 a
nd src.key < 300
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/dest4.out' SELECT src.value WHERE src.key >= 300;
例子:
from tbl1
insert overwrite table test2 select '1,2,3' limit 1
insert overwrite table d select '4,5,6' limit 1;
關於hive資料匯出方式更詳細的內容可參考
刪除
刪除一個內部表的同時會同時刪除表的元資料和資料。刪除一個外部表,只刪除元資料而保留資料。
語法:
DROP TABLE tbl_name
Limit/Top/REGEX
Limit 可以限制查詢的記錄數。查詢的結果是隨機選擇的。下面的查詢語句從 t1 表中隨機查詢5條記錄:
SELECT * FROM t1 LIMIT 5
下面的查詢語句查詢銷售記錄最大的 5 個銷售代表。
SET mapred.reduce.tasks = 1
SELECT * FROM sales SORT BY amount DESC LIMIT 5
SELECT 語句可以使用正則表示式做列選擇,下面的語句查詢除了 ds 和 hr 之外的所有列:
SELECT `(ds|hr)?+.+` FROM sales
查詢
語法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
GROUP BY
groupByClause: GROUP BY groupByExpression (, groupByExpression)*
groupByExpression: expression
groupByQuery: SELECT expression (, expression)* FROM src groupByClause?
Order/Sort By
Order by 語法:
colOrder: ( ASC | DESC )
orderBy: ORDER BY colName colOrder? (',' colName colOrder?)*
query: SELECT expression (',' expression)* FROM src orderBy
Sort By 語法: Sort順序將根據列型別而定。如果數字型別的列,則排序順序也以數字順序。如果
字串型別的列,則排序順序將字典順序。
colOrder: ( ASC | DESC )
sortBy: SORT BY colName colOrder? (',' colName colOrder?)*
query: SELECT expression (',' expression)* FROM src sortBy
Hive Join
語法:
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON equality_expression ( AND equality_expression )*
equality_expression:
expression = expression
Hive 只支援等值連線(equality joins)、外連線(outer joins)和(left/right joins)。Hive 不支援所有非等值的連線,因為非等值連線非常難轉化到 map/reduce 任務。另外,Hive 支援多於 2 個表的連線。
注意事項
- 只支援等值join.
例如:
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
是正確的,然而:
SELECT a.* FROM a JOIN b ON (a.id b.id)
是錯誤的。
- 可以join多於2個表
例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
如果join中多個表的 join key 是同一個,則 join 會被轉化為單個 map/reduce 任務,例如:
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c
ON (c.key = b.key1)
被轉化為單個 map/reduce 任務,因為 join 中只使用了 b.key1 作為 join key。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1)
JOIN c ON (c.key = b.key2)
而這一 join 被轉化為 2 個 map/reduce 任務。因為 b.key1 用於第一次 join 條件,而 b.key2 用於第二次 join。
- join時,map/reduce的邏輯
reducer 會快取 join 序列中除了最後一個表的所有表的記錄,再通過最後一個表將結果序列化到檔案系統。這一實現有助於在 reduce 端減少記憶體的使用量。實踐中,應該把最大的那個表寫在最後(否則會因為快取浪費大量記憶體)。例如:
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
所有表都使用同一個 join key(使用 1 次 map/reduce 任務計算)。Reduce 端會快取 a 表和 b 表的記錄,然後每次取得一個 c 表的記錄就計算一次 join 結果,類似的還有:
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
這裡用了 2 次 map/reduce 任務。第一次快取 a 表,用 b 表序列化;第二次快取第一次 map/reduce 任務的結果,然後用 c 表序列化。
HIVE內建函式
UDF
基本函式:
SHOW FUNCTIONS;
DESCRIBE FUNCTION <function_name>;
UDTF
UDTF即Built-in Table-Generating Functions 使用這些UDTF函式有一些限制:
1、SELECT裡面不能有其它欄位,如:
SELECT pageid, explode(adid_list) AS myCol...
2、不能巢狀,如:
SELECT explode(explode(adid_list)) AS myCol... # 不支援
3、不支援GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY ,如:
SELECT explode(adid_list) AS myCol ... GROUP BY myCol
EXPLODE
下面是一個示例:
場景:將資料進行轉置,如:
create table test2(mycol array<int>);
insert OVERWRITE table test2 select * from (select array(1,2,3) from a union all select array(7,8,9) from d)c;
hive> select * from test2;
OK
[1,2,3]
[7,8,9]
hive> SELECT explode(myCol) AS myNewCol FROM test2;
OK
1
2
3
7
8
9
抽樣
抽樣語句允許使用者抽取樣品資料而不是整個表的資料來進行查詢, 抽樣語句只適用於在表建立時使用bucketed on 語句進行分桶的表, 例如:
INSERT OVERWRITE TABLE pv_gender_sum_sample
SELECT pv_gender_sum.*
FROM pv_gender_sum TABLESAMPLE(BUCKET 3 OUT OF 32);
抽取總共32桶中的第三桶
抽樣語句的語法如下:
TABLESAMPLE(BUCKET x OUT OF y)
其中, x必須比y小, y必須是在建立表的時候bucket on的數量的因子或者倍數, hive會根據y的大小來決定抽樣多少, 比如原本分了32分, 當y=16時, 抽取32/16=2分, 這時TABLESAMPLE(BUCKET 3 OUT OF 16) 就意味著要抽取第3和第16+3=19分的樣品.如果y=64, 這要抽取 32/64=1/2份資料, 這時TABLESAMPLE(BUCKET 3 OUT OF 64) 意味著抽取第3份資料的一半來進行.
陣列操作
一個欄位的資料型別是陣列時, 可以通過陣列的索引來訪問該欄位的某個索引值
SELECT pv.friends[2]
FROM page_views pv;
另外還提供了一個函式 size, 可以求出陣列的大小
SELECT pv.userid, size (pv.friends)
FROM page_view pv;
Map(關聯性陣列)操作
map的訪問類似於 php中對陣列的訪問, 直接用key作為索引來訪問陣列即可.
INSERT OVERWRITE page_views_map
SELECT pv.userid, pv.properties['page type']
FROM page_views pv;
與陣列類似, 也提供了一個求大小的函式 size
SELECT size (pv.properties)(/Column/Column?Channel=cloud&Type=hot)
Hive效能優化
首先,我們來看看Hadoop的計算框架特性,在此特性下會衍生哪些問題?
- 資料量大不是問題,資料傾斜是個問題。
- jobs數比較多的作業執行效率相對比較低,比如即使有幾百行的表,如果多次關聯多次彙總,產生十幾個jobs,耗時很⻓。原因是map reduce作業初始化的時間是比較⻓的。
- sum,count,max,min等UDAF,不怕資料傾斜問題,hadoop在map端的彙總合併優化,使資料傾斜不成問題。
- count(distinct ),在資料量大的情況下,效率較低,如果是多count(distinct )效率更低,因為count(distinct)是按group by 欄位分組,按distinct欄位排序,一般這種分佈方式是很傾斜的。舉個例子:比如男uv,女uv,像淘寶一天30億的pv,如果按性別分組,分配2個reduce,每個reduce處理15億資料。
面對這些問題,我們能有哪些有效的優化手段呢?下面列出一些在工作有效可行的優化手段:
- 好的模型設計事半功倍。
- 解決資料傾斜問題。
- 減少job數。
- 置合理的map reduce的task數,能有效提升效能。(比如,10w+級別的計算,用160個reduce,那是相當的浪費,1個足夠)。
- 瞭解資料分佈,自己動手解決資料傾斜問題是個不錯的選擇。set hive.groupby.skewindata=true;這是通用的演算法優化,但演算法優化有時不能適應特定業務背景,開發人員瞭解業務,瞭解資料,可以通過業務邏輯精確有效的解決資料傾斜問題。
- 資料量較大的情況下,慎用count(distinct),count(distinct)容易產生傾斜問題。
- 對小檔案進行合併,是行至有效的提高排程效率的方法,假如所有的作業設定合理的檔案數,對雲梯的整體排程效率也會產生積極的正向影響。
- 優化時把握整體,單個作業最優不如整體最優。
效能低下的根源
hive效能優化時,把HiveQL當做M/R程式來讀,即從M/R的執行⻆度來考慮優化效能,從更底層思考如何優化運算效能,而不僅僅侷限於邏輯程式碼的替換層面。
RAC(Real Application Cluster)真正應用叢集就像一輛機動靈活的小貨車,響應快;Hadoop就像吞吐量巨大的輪船,啟動開銷大,如果每次只做小數量的輸入輸出,利用率將會很低。所以用好Hadoop的首要任務是增大每次任務所搭載的資料量。
Hadoop的核心能力是parition和sort,因而這也是優化的根本。
觀察Hadoop處理資料的過程,有幾個顯著的特徵:
- 資料的大規模並不是負載重點,造成執行壓力過大是因為執行資料的傾斜。
- jobs數比較多的作業執行效率相對比較低,比如即使有幾百行的表,如果多次關聯對此彙總,產生幾十個jobs,將會需要30分鐘以上的時間且大部分時間被用於作業分配,初始化和資料輸出。M/R作業初始化的時間是比較耗時間資源的一個部分。
- 在使用SUM,COUNT,MAX,MIN等UDAF函式時,不怕資料傾斜問題,Hadoop在Map端的彙總合併優化過,使資料傾斜不成問題。
- COUNT(DISTINCT)在資料量大的情況下,效率較低,如果多COUNT(DISTINCT)效率更低,因為COUNT(DISTINCT)是按GROUP BY欄位分組,按DISTINCT欄位排序,一般這種分散式方式是很傾斜的;比如:男UV,女UV,淘寶一天30億的PV,如果按性別分組,分配2個reduce,每個reduce處理15億資料。
- 資料傾斜是導致效率大幅降低的主要原因,可以採用多一次 Map/Reduce 的方法, 避免傾斜。
最後得出的結論是:避實就虛,用 job 數的增加,輸入量的增加,佔用更多儲存空間,充分利用空
閒 CPU 等各種方法,分解資料傾斜造成的負擔。
配置角度優化
我們知道了效能低下的根源,同樣,我們也可以從Hive的配置角度去優化。Hive系統內部已針對不同的查詢預設定了優化方法,使用者可以通過調整配置進行控制, 以下舉例介紹部分優化的策略以及優化控制選項。
列裁剪
Hive 在讀資料的時候,可以只讀取查詢中所需要用到的列,而忽略其它列。 例如,若有以下查詢:
SELECT a,b FROM q WHERE e<10;
在實施此項查詢中,Q 表有 5 列(a,b,c,d,e),Hive 只讀取查詢邏輯中真實需要 的 3 列 a、b、e,而忽略列 c,d;這樣做節省了讀取開銷,中間表儲存開銷和資料整合開銷。
裁剪所對應的引數項為:hive.optimize.cp=true(預設值為真)
分割槽裁剪
可以在查詢的過程中減少不必要的分割槽。 例如,若有以下查詢:
SELECT * FROM (SELECTT a1,COUNT(1) FROM T GROUP BY a1) subq WHERE subq.prtn=100; #(多餘分割槽)
SELECT * FROM T1 JOIN (SELECT * FROM T2) subq ON (T1.a1=subq.a2) WHERE subq.prtn=100;
查詢語句若將“subq.prtn=100”條件放入子查詢中更為高效,可以減少讀入的分割槽 數目,傳統資料庫也是一樣的。 Hive 自動執行這種裁剪優化。
分割槽引數為:hive.optimize.pruner=true(預設值為真)
join操作
在編寫帶有 join 操作的程式碼語句時,應該將條目少的表/子查詢放在 Join 操作符的左邊。 因為在 Reduce 階段,位於 Join 操作符左邊的表的內容會被載入進記憶體,載入條目較少的表 可以有效減少 OOM(out of memory)即記憶體溢位。所以對於同一個 key 來說,對應的 value 值小的放前,大的放後,這便是“小表放前”原則。 若一條語句中有多個 Join,依據 Join 的條件相同與否,有不同的處理方法。
join原則
在使用寫有 Join 操作的查詢語句時有一條原則:應該將條目少的表/子查詢放在 Join 操作符的左邊。原因是在 Join 操作的 Reduce 階段,位於 Join 操作符左邊的表的內容會被載入進記憶體,將條目少的表放在左邊,可以有效減少發生 OOM 錯誤的機率。對於一條語句中有多個 Join 的情況,如果 Join 的條
件相同,比如查詢:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid);
- 如果 Join 的 key 相同,不管有多少個表,都會則會合併為一個 Map-Reduce
- 一個 Map-Reduce 任務,而不是 ‘n’ 個
- 在做 OUTER JOIN 的時候也是一樣
如果 Join 的條件不相同,比如:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.age = x.age);
Map-Reduce 的任務數目和 Join 操作的數目是對應的,上述查詢和以下查詢是等價的:
INSERT OVERWRITE TABLE tmptable
SELECT * FROM page_view p JOIN user u
ON (pv.userid = u.userid);
INSERT OVERWRITE TABLE pv_users
SELECT x.pageid, x.age FROM tmptable x
JOIN newuser y ON (x.age = y.age);
MAP JOIN操作
Join 操作在 Map 階段完成,不再需要Reduce,前提條件是需要的資料在 Map 的過程中可以訪問到。比如查詢:
INSERT OVERWRITE TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv
JOIN user u ON (pv.userid = u.userid);
可以在 Map 階段完成 Join,如圖所示:
相關的引數為:
- hive.join.emit.interval = 1000
- hive.mapjoin.size.key = 10000
- hive.mapjoin.cache.numrows = 10000
GROUP BY操作
進行GROUP BY操作時需要注意一下幾點:
- Map端部分聚合
事實上並不是所有的聚合操作都需要在reduce部分進行,很多聚合操作都可以先在Map端進行部分聚合,然後reduce端得出最終結果。
這裡需要修改的引數為:
hive.map.aggr=true(用於設定是否在 map 端進行聚合,預設值為真) hive.groupby.mapaggr.checkinterval=100000(用於設定 map 端進行聚合操作的條目數)
- 有資料傾斜時進行負載均衡
此處需要設定 hive.groupby.skewindata,當選項設定為 true 是,生成的查詢計劃有兩 個 MapReduce 任務。在第一個 MapReduce 中,map 的輸出結果集合會隨機分佈到 reduce 中, 每個 reduce 做部分聚合操作,並輸出結果。這樣處理的結果是,相同的 Group By Key 有可 能分發到不同的 reduce中,從而達到負載均衡的目的;第二個 MapReduce 任務再根據預處 理的資料結果按照 Group By Key分佈到 reduce 中(這個過程可以保證相同的 Group By Key 分佈到同一個 reduce 中),最後完成最終的聚合操作。
合併小檔案
我們知道檔案數目小,容易在檔案儲存端造成瓶頸,給 HDFS 帶來壓力,影響處理效率。對此,可以通過合併Map和Reduce的結果檔案來消除這樣的影響。
用於設定合併屬性的引數有:
- 是否合併Map輸出檔案:hive.merge.mapfiles=true(預設值為真)
- 是否合併Reduce 端輸出檔案:hive.merge.mapredfiles=false(預設值為假)
- 合併檔案的大小:hive.merge.size.per.task=25610001000(預設值為 256000000)
程式角度優化
熟練使用SQL提高查詢
熟練地使用 SQL,能寫出高效率的查詢語句。
場景:有一張 user 表,為賣家每天收到表,user_id,ds(日期)為 key,屬性有主營類目,指標有交易金額,交易筆數。每天要取前10天的總收入,總筆數,和最近一天的主營類目。
解決方法1:
如下所示:常用方法
INSERT OVERWRITE TABLE t1
SELECT user_id,substr(MAX(CONCAT(ds,cat),9) AS main_cat) FROM users
WHERE ds=20120329 // 20120329 為日期列的值,實際程式碼中可以用函式表示出當天日期 GROUP BY user_id;
INSERT OVERWRITE TABLE t2
SELECT user_id,sum(qty) AS qty,SUM(amt) AS amt FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id
SELECT t1.user_id,t1.main_cat,t2.qty,t2.amt FROM t1
JOIN t2 ON t1.user_id=t2.user_id
下面給出方法1的思路,實現步驟如下:
第一步:利用分析函式,取每個 user_id 最近一天的主營類目,存入臨時表 t1。
第二步:彙總 10 天的總交易金額,交易筆數,存入臨時表 t2。
第三步:關聯 t1,t2,得到最終的結果。
解決方法2:
如下所示:優化方法
SELECT user_id,substr(MAX(CONCAT(ds,cat)),9) AS main_cat,SUM(qty),SUM(amt) FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id
在工作中我們總結出:方案 2 的開銷等於方案 1 的第二步的開銷,效能提升,由原有的 25 分鐘完成,縮短為 10 分鐘以內完成。節省了兩個臨時表的讀寫是一個關鍵原因,這種方式也適用於 Oracl