
2. Java中的垃圾收集
標記-清除(Mark and Sweep)是最經典的垃圾收集演算法。將理論用於生產實踐時, 會有很多需要優化調整的地點, 以適應具體環境。下面通過一個簡單的例子, 讓我們一步步記錄下來, 看看如何才能保證JVM能安全持續地分配物件。
碎片整理(Fragmenting and Compacting)
每次執行清除(sweeping), JVM 都必須保證不可達物件佔用的記憶體能被回收重用。但這(最終)有可能會產生記憶體碎片(類似於磁碟碎片), 進而引發兩個問題:
寫入操作越來越耗時, 因為尋找一塊足夠大的空閒記憶體會變得非常麻煩。
在建立新物件時, JVM在連續的塊中分配記憶體。如果碎片問題很嚴重, 直至沒有空閒片段能存放下新建立的物件,就會發生記憶體分配錯誤(allocation error)。
要避免這類問題,JVM 必須確保碎片問題不失控。因此在垃圾收集過程中, 不僅僅是標記和清除, 還需要執行 “記憶體碎片整理” 過程。這個過程讓所有可達物件(reachable objects)依次排列, 以消除(或減少)碎片。示意圖如下所示:
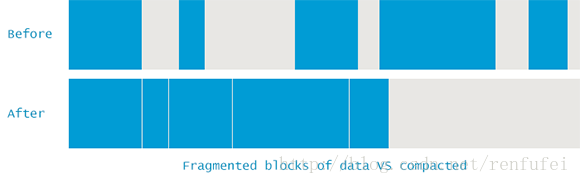
說明:
JVM中的引用是一個抽象的概念,如果GC移動某個物件, 就會修改(棧和堆中)所有指向該物件的引用。
移動/提升/壓縮 是一個 STW 的過程,所以修改物件引用是一個安全的行為。
分代假設(Generational Hypothesis)
我們前面提到過,執行垃圾收集需要停止整個應用。很明顯,物件越多則收集所有垃圾消耗的時間就越長。但可不可以只處理一個較小的記憶體區域呢? 為了探究這種可能性,研究人員發現,程式中的大多數可回收的記憶體可歸為兩類:
大部分物件很快就不再使用
還有一部分不會立即無用,但也不會持續(太)長時間
這些觀測形成了 弱代假設(Weak Generational Hypothesis)。基於這一假設, VM中的記憶體被分為年輕代(Young Generation)和老年代(Old Generation)。老年代有時候也稱為 年老區(Tenured)。

拆分為這樣兩個可清理的單獨區域,允許採用不同的演算法來大幅提高GC的效能。
這種方法也不是沒有問題。例如,在不同分代中的物件可能會互相引用, 在收集某一個分代時就會成為 “事實上的” GC root。
當然,要著重強調的是,分代假設並不適用於所有程式。因為GC演算法專門針對“要麼死得快”,“否則活得長” 這類特徵的物件來進行優化, JVM對收集那種存活時間半長不長的物件就顯得非常尷尬了。
記憶體池(Memory Pools)
堆記憶體中的記憶體池劃分也是類似的。不太容易理解的地方在於各個記憶體池中的垃圾收集是如何執行的。請注意,不同的GC演算法在實現細節上可能會有所不同,但和本章所介紹的相關概念都是一致的。

新生代(Eden,伊甸園)
Eden 是記憶體中的一個區域, 用來分配新建立的物件。通常會有多個執行緒同時建立多個物件, 所以 Eden 區被劃分為多個 執行緒本地分配緩衝區(Thread Local Allocation Buffer, 簡稱TLAB)。通過這種緩衝區劃分,大部分物件直接由JVM 在對應執行緒的TLAB中分配, 避免與其他執行緒的同步操作。
如果 TLAB 中沒有足夠的記憶體空間, 就會在共享Eden區(shared Eden space)之中分配。如果共享Eden區也沒有足夠的空間, 就會觸發一次 年輕代GC 來釋放記憶體空間。如果GC之後 Eden 區依然沒有足夠的空閒記憶體區域, 則物件就會被分配到老年代空間(Old Generation)。
當 Eden 區進行垃圾收集時, GC將所有從 root 可達的物件過一遍, 並標記為存活物件。
我們曾指出,物件間可能會有跨代的引用, 所以需要一種方法來標記從其他分代中指向Eden的所有引用。這樣做又會遭遇各個分代之間一遍又一遍的引用。JVM在實現時採用了一些絕招: 卡片標記(card-marking)。從本質上講,JVM只需要記住Eden區中 “髒”物件的粗略位置, 可能有老年代的物件引用指向這部分割槽間。更多細節請參考: Nitsan 的部落格 。
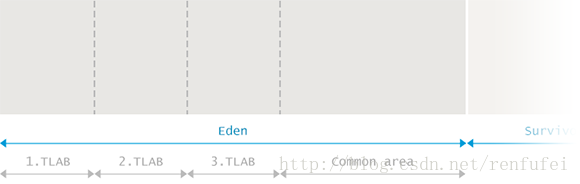
標記階段完成後, Eden中所有存活的物件都會被複制到存活區(Survivor spaces)裡面。整個Eden區就可以被認為是空的, 然後就能用來分配新物件。這種方法稱為 “標記-複製”(Mark and Copy): 存活的物件被標記, 然後複製到一個存活區(注意,是複製,而不是移動)。
存活區(Survivor Spaces)
Eden 區的旁邊是兩個存活區, 稱為 from 空間和 to 空間。需要著重強調的的是, 任意時刻總有一個存活區是空的(empty)。
空的那個存活區用於在下一次年輕代GC時存放收集的物件。年輕代中所有的存活物件(包括Edenq區和非空的那個 “from” 存活區)都會被複制到 ”to“ 存活區。GC過程完成後, ”to“ 區有物件,而 ‘from’ 區裡沒有物件。兩者的角色進行正好切換 。
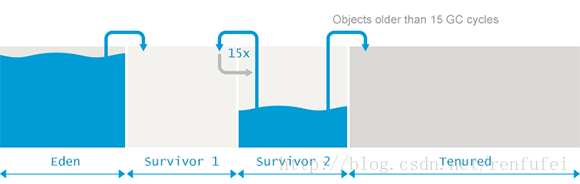
存活的物件會在兩個存活區之間複製多次, 直到某些物件的存活 時間達到一定的閥值。分代理論假設, 存活超過一定時間的物件很可能會繼續存活更長時間。
這類“ 年老” 的物件因此被提升(promoted )到老年代。提升的時候, 存活區的物件不再是複製到另一個存活區,而是遷移到老年代, 並在老年代一直駐留, 直到變為不可達物件。
為了確定一個物件是否“足夠老”, 可以被提升(Promotion)到老年代,GC模組跟蹤記錄每個存活區物件存活的次數。每次分代GC完成後,存活物件的年齡就會增長。當年齡超過提升閾值(tenuring threshold), 就會被提升到老年代區域。
具體的提升閾值由JVM動態調整,但也可以用引數 -XX:+MaxTenuringThreshold 來指定上限。如果設定 -XX:+MaxTenuringThreshold=0 , 則GC時存活物件不在存活區之間複製,直接提升到老年代。現代 JVM 中這個閾值預設設定為15個 GC週期。這也是HotSpot中的最大值。
如果存活區空間不夠存放年輕代中的存活物件,提升(Promotion)也可能更早地進行。
老年代(Old Generation)
老年代的GC實現要複雜得多。老年代記憶體空間通常會更大,裡面的物件是垃圾的概率也更小。
老年代GC發生的頻率比年輕代小很多。同時, 因為預期老年代中的物件大部分是存活的, 所以不再使用標記和複製(Mark and Copy)演算法。而是採用移動物件的方式來實現最小化記憶體碎片。老年代空間的清理演算法通常是建立在不同的基礎上的。原則上,會執行以下這些步驟:
通過標誌位(marked bit),標記所有通過 GC roots 可達的物件.
刪除所有不可達物件
整理老年代空間中的內容,方法是將所有的存活物件複製,從老年代空間開始的地方,依次存放。
通過上面的描述可知, 老年代GC必須明確地進行整理,以避免記憶體碎片過多。
永久代(PermGen)
在Java 8 之前有一個特殊的空間,稱為“永久代”(Permanent Generation)。這是儲存元資料(metadata)的地方,比如 class 資訊等。此外,這個區域中也儲存有其他的資料和資訊, 包括 內部化的字串(internalized strings)等等。實際上這給Java開發者造成了很多麻煩,因為很難去計算這塊區域到底需要佔用多少記憶體空間。預測失敗導致的結果就是產生 java.lang.OutOfMemoryError: Permgen space 這種形式的錯誤。除非 ·OutOfMemoryError· 確實是記憶體洩漏導致的,否則就只能增加 permgen 的大小,例如下面的示例,就是設定 permgen 最大空間為 256 MB:
java -XX:MaxPermSize=256m com.mycompany.MyApplication
元資料區(Metaspace)
既然估算元資料所需空間那麼複雜, Java 8直接刪除了永久代(Permanent Generation),改用 Metaspace。從此以後, Java 中很多雜七雜八的東西都放置到普通的堆記憶體裡。
當然,像類定義(class definitions)之類的資訊會被載入到 Metaspace 中。元資料區位於本地記憶體(native memory),不再影響到普通的Java物件。預設情況下, Metaspace的大小隻受限於 Java程序可用的本地記憶體。這樣程式就不再因為多載入了幾個類/JAR包就導致 java.lang.OutOfMemoryError: Permgen space. 。注意, 這種不受限制的空間也不是沒有代價的 —— 如果 Metaspace 失控, 則可能會導致很嚴重的記憶體交換(swapping), 或者導致本地記憶體分配失敗。
如果需要避免這種最壞情況,那麼可以通過下面這樣的方式來限制 Metaspace 的大小, 如 256 MB:
java -XX:MaxMetaspaceSize=256m com.mycompany.MyApplication
Minor GC vs Major GC vs Full GC
垃圾收集事件(Garbage Collection events)通常分為: 小型GC(Minor GC) - 大型GC(Major GC) - 和完全GC(Full GC) 。本節介紹這些事件及其區別。然後你會發現這些區別也不是特別清晰。
最重要的是,應用程式是否滿足 服務級別協議(Service Level Agreement, SLA), 並通過監控程式檢視響應延遲和吞吐量。也只有那時候才能看到GC事件相關的結果。重要的是這些事件是否停止整個程式,以及持續多長時間。
雖然 Minor, Major 和 Full GC 這些術語被廣泛應用, 但並沒有標準的定義, 我們還是來深入瞭解一下具體的細節吧。
小型GC(Minor GC)
年輕代記憶體的垃圾收集事件稱為小型GC。這個定義既清晰又得到廣泛共識。對於小型GC事件,有一些有趣的事情你應該瞭解一下:
- 當JVM無法為新物件分配記憶體空間時總會觸發 Minor GC,比如 Eden 區佔滿時。所以(新物件)分配頻率越高, Minor GC 的頻率就越高。
- Minor GC 事件實際上忽略了老年代。從老年代指向年輕代的引用都被認為是GC Root。而從年輕代指向老年代的引用在標記階段全部被忽略。
- 與一般的認識相反, Minor GC 每次都會引起全線停頓(stop-the-world ), 暫停所有的應用執行緒。對大多數程式而言,暫停時長基本上是可以忽略不計的, 因為 Eden 區的物件基本上都是垃圾, 也不怎麼複製到存活區/老年代。如果情況不是這樣, 大部分新建立的物件不能被垃圾回收清理掉, 則 Minor GC的停頓就會持續更長的時間。
所以 Minor GC 的定義很簡單 —— Minor GC 清理的就是年輕代。
Major GC vs Full GC
值得一提的是, 這些術語並沒有正式的定義 —— 無論是在JVM規範還是在GC相關論文中。
我們知道, Minor GC 清理的是年輕代空間(Young space),相應的,其他定義也很簡單:
- Major GC(大型GC) 清理的是老年代空間(Old space)。
- Full GC(完全GC)清理的是整個堆, 包括年輕代和老年代空間。
杯具的是更復雜的情況出現了。很多 Major GC 是由 Minor GC 觸發的, 所以很多情況下這兩者是不可分離的。另一方面, 像G1這樣的垃圾收集演算法執行的是部分割槽域垃圾回收, 所以,額,使用術語“cleaning”並不是非常準確。
這也讓我們認識到,不應該去操心是叫 Major GC 呢還是叫 Full GC, 我們應該關注的是: 某次GC事件 是否停止所有執行緒,或者是與其他執行緒併發執行。
這些混淆甚至根植於標準的JVM工具中。我的意思可以通過例項來說明。讓我們來對比同一JVM中兩款工具的GC資訊輸出吧。這個JVM使用的是 併發標記和清除收集器(Concurrent Mark and Sweep collector,-XX:+UseConcMarkSweepGC).
首先我們來看 jstat 的輸出:
jstat -gc -t 4235 1s
Time S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
5.7 34048.0 34048.0 0.0 34048.0 272640.0 194699.7 1756416.0 181419.9 18304.0 17865.1 2688.0 2497.6 3 0.275 0 0.000 0.275
6.7 34048.0 34048.0 34048.0 0.0 272640.0 247555.4 1756416.0 263447.9 18816.0 18123.3 2688.0 2523.1 4 0.359 0 0.000 0.359
7.7 34048.0 34048.0 0.0 34048.0 272640.0 257729.3 1756416.0 345109.8 19072.0 18396.6 2688.0 2550.3 5 0.451 0 0.000 0.451
8.7 34048.0 34048.0 34048.0 34048.0 272640.0 272640.0 1756416.0 444982.5 19456.0 18681.3 2816.0 2575.8 7 0.550 0 0.000 0.550
9.7 34048.0 34048.0 34046.7 0.0 272640.0 16777.0 1756416.0 587906.3 20096.0 19235.1 2944.0 2631.8 8 0.720 0 0.000 0.720
10.7 34048.0 34048.0 0.0 34046.2 272640.0 80171.6 1756416.0 664913.4 20352.0 19495.9 2944.0 2657.4 9 0.810 0 0.000 0.810
11.7 34048.0 34048.0 34048.0 0.0 272640.0 129480.8 1756416.0 745100.2 20608.0 19704.5 2944.0 2678.4 10 0.896 0 0.000 0.896
12.7 34048.0 34048.0 0.0 34046.6 272640.0 164070.7 1756416.0 822073.7 20992.0 19937.1 3072.0 2702.8 11 0.978 0 0.000 0.978
13.7 34048.0 34048.0 34048.0 0.0 272640.0 211949.9 1756416.0 897364.4 21248.0 20179.6 3072.0 2728.1 12 1.087 1 0.004 1.091
14.7 34048.0 34048.0 0.0 34047.1 272640.0 245801.5 1756416.0 597362.6 21504.0 20390.6 3072.0 2750.3 13 1.183 2 0.050 1.233
15.7 34048.0 34048.0 0.0 34048.0 272640.0 21474.1 1756416.0 757347.0 22012.0 20792.0 3200.0 2791.0 15 1.336 2 0.050 1.386
16.7 34048.0 34048.0 34047.0 0.0 272640.0 48378.0 1756416.0 838594.4 22268.0 21003.5 3200.0 2813.2 16 1.433 2 0.050 1.484
此片段擷取自JVM啟動後的前17秒。根據這些資訊可以得知: 有2次Full GC在12次Minor GC(YGC)之後觸發執行, 總計耗時 50ms。當然,也可以通過具備圖形介面的工具得出同樣的資訊, 比如 jconsole 或者 jvisualvm (或者最新的 jmc)。
在下結論之前, 讓我們看看此JVM程序的GC日誌。顯然需要配置 -XX:+PrintGCDetails 引數,GC日誌的內容更詳細,結果也有一些不同:
java -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC eu.plumbr.demo.GarbageProducer
3.157: [GC (Allocation Failure) 3.157: [ParNew: 272640K->34048K(306688K), 0.0844702 secs] 272640K->69574K(2063104K), 0.0845560 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]
4.092: [GC (Allocation Failure) 4.092: [ParNew: 306688K->34048K(306688K), 0.1013723 secs] 342214K->136584K(2063104K), 0.1014307 secs] [Times: user=0.25 sys=0.05, real=0.10 secs]
... cut for brevity ...
11.292: [GC (Allocation Failure) 11.292: [ParNew: 306686K->34048K(306688K), 0.0857219 secs] 971599K->779148K(2063104K), 0.0857875 secs] [Times: user=0.26 sys=0.04, real=0.09 secs]
12.140: [GC (Allocation Failure) 12.140: [ParNew: 306688K->34046K(306688K), 0.0821774 secs] 1051788K->856120K(2063104K), 0.0822400 secs] [Times: user=0.25 sys=0.03, real=0.08 secs]
12.989: [GC (Allocation Failure) 12.989: [ParNew: 306686K->34048K(306688K), 0.1086667 secs] 1128760K->931412K(2063104K), 0.1087416 secs] [Times: user=0.24 sys=0.04, real=0.11 secs]
13.098: [GC (CMS Initial Mark) [1 CMS-initial-mark: 897364K(1756416K)] 936667K(2063104K), 0.0041705 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
13.102: [CMS-concurrent-mark-start]
13.341: [CMS-concurrent-mark: 0.238/0.238 secs] [Times: user=0.36 sys=0.01, real=0.24 secs]
13.341: [CMS-concurrent-preclean-start]
13.350: [CMS-concurrent-preclean: 0.009/0.009 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
13.350: [CMS-concurrent-abortable-preclean-start]
13.878: [GC (Allocation Failure) 13.878: [ParNew: 306688K->34047K(306688K), 0.0960456 secs] 1204052K->1010638K(2063104K), 0.0961542 secs] [Times: user=0.29 sys=0.04, real=0.09 secs]
14.366: [CMS-concurrent-abortable-preclean: 0.917/1.016 secs] [Times: user=2.22 sys=0.07, real=1.01 secs]
14.366: [GC (CMS Final Remark) [YG occupancy: 182593 K (306688 K)]14.366: [Rescan (parallel) , 0.0291598 secs]14.395: [weak refs processing, 0.0000232 secs]14.395: [class unloading, 0.0117661 secs]14.407: [scrub symbol table, 0.0015323 secs]14.409: [scrub string table, 0.0003221 secs][1 CMS-remark: 976591K(1756416K)] 1159184K(2063104K), 0.0462010 secs] [Times: user=0.14 sys=0.00, real=0.05 secs]
14.412: [CMS-concurrent-sweep-start]
14.633: [CMS-concurrent-sweep: 0.221/0.221 secs] [Times: user=0.37 sys=0.00, real=0.22 secs]
14.633: [CMS-concurrent-reset-start]
14.636: [CMS-concurrent-reset: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
通過GC日誌可以看到, 在12 次 Minor GC之後發生了一些 “不同的事情”。並不是兩個 Full GC, 而是在老年代執行了一次 GC, 分為多個階段執行:
- 初始標記階段(Initial Mark phase),耗時 0.0041705秒(約4ms)。此階段是全線停頓(STW)事件,暫停所有應用執行緒,以便執行初始標記。
- 標記和預清理階段(Markup and Preclean phase)。和應用執行緒併發執行。
- 最終標記階段(Final Remark phase), 耗時 0.0462010秒(約46ms)。此階段也是全線停頓(STW)事件。
- 清除操作(Sweep)是併發執行的, 不需要暫停應用執行緒。
所以從實際的GC日誌可以看到, 並不是執行了兩次 Full GC操作, 而是隻執行了一次清理老年代空間的 Major GC 。
如果只關心延遲, 通過後面 jstat 顯示的資料, 也能得出正確的結果。它正確地列出了兩次 STW 事件,總計耗時 50 ms。這段時間影響了所有應用執行緒的延遲。如果想要優化吞吐量, 這個結果就會有誤導性 —— jstat 只列出了 stop-the-world 的初始標記階段和最終標記階段, jstat 的輸出完全隱藏了併發執行的GC階段。
翻譯時間: 2016年01月28日