
Web指紋識別之Discuz識別+粗略版本判斷
這個識別程式是本學期我的專業實訓上的一個專案,就是做一個類似於Zoomeye的東西,然後使用ES進行整合,從而做出搜尋引擎的模樣。那麼首先就要有能力去網上識別出相應的Web元件,如使用者輸入關鍵詞:Discuz X3.0,我就要顯示出相應版本的內容才OK。作為識別子程式,我這裡暫且分享一下識別Web元件的思路。
我是從淺談web指紋識別技術一文中找到的思路。對於Discuz的網站,第一時間想的就是識別footer了,但是問題在於,做的好的一些網站往往會將“Powered By”字樣修改,所以為了配合footer字樣進行識別,我使用了robots.txt和比較隱蔽的meta標籤來進行共同識別。而粗略的版本資訊,則是從robots.txt中獲取的。
指紋全部放在一起進行管理,方便日後進行指紋的新增:
discuz_feature.py:
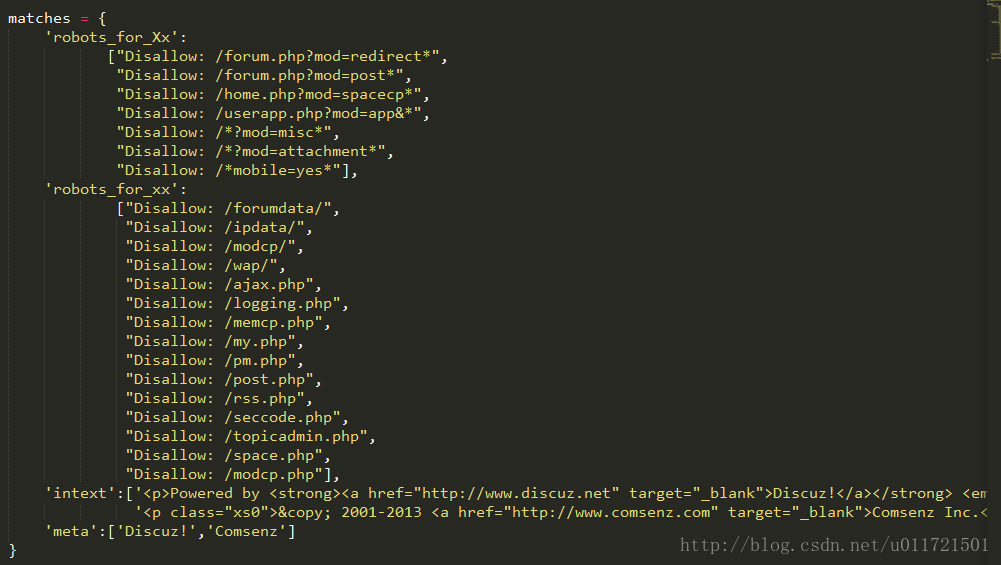
這個檔案中只有一個字典用來存放相應的指紋資訊,我不可能做得很細(時間不允許啊),所以只有footer資訊、robots資訊、meta資訊三個型別的指紋。
在主程式中直接load這個指紋庫即可,下面就是識別主程式的程式碼,程式輸入為以回車換行分割的域名列表,輸出為結果檔案,程式碼如下:
#coding=utf-8 import requests from bs4 import BeautifulSoup import re from discuz_feature import matches ''' Discuz 指紋識別 1.meta資料元識別 2.intext識別 3.robots.txt識別 ''' class DiscuzDetector(): '''構造方法''' def __init__(self,url): if url.startswith("http://"): self.url = url else: self.url = "http://%s" % url try: self.r = requests.get(self.url,timeout=8) self.page_content = self.r.content except Exception, e: print e self.r = None self.page_content = None '''識別meta標籤''' def meta_detect(self): if not self.r: return False pattern = re.compile(r'<meta name=".*?" content="(.+)" />') infos = pattern.findall(self.page_content) conditions = matches['meta'][0] or matches['meta'][1] if infos: for x in infos: if x.count(conditions) != 0: return True break else: return False '''discuz 版本識別''' def robots_dz_xx_detect(self): if not self.r: return (False,None) robots_url = "%s%s" % (self.url,"/robots.txt") robots_content = requests.get(robots_url).content if not robots_content: return (False,None) robots_feature_xx = matches['robots_for_xx'] robots_feature_Xx = matches['robots_for_Xx'] robots_list = robots_content.split("\r\n") pattern = re.compile(r'# robots\.txt for (.+)') version_info = [] for x in robots_list: #如果robots.txt中含有# robots.txt for Discuz! X3 行 則直接判斷版本 version_info = pattern.findall(x) if version_info != [] and robots_content.count("Version" and "Discuz!"): if robots_content.count("Version" and "Discuz!"): pattern = re.compile(r'# Version (.+)') version_number = pattern.findall(str(robots_content)) if version_number: version_info.append(version_number) return (True,version_info) else: #若版本資訊被刪除則識別出版本 is_xx = (x in robots_feature_xx) is_Xx = (x in robots_feature_Xx) if is_Xx or is_xx: #判斷為discuz #判斷版本 if is_Xx == True: version_info = 'Discuz Xx' return (True,version_info) else: version_info = 'Discuz xx' return (True,version_info) #不是discuz return (False,None) '''檢測網頁中的discuz字樣''' def detect_intext(self): if not self.r: return False text_feature = matches['intext'][0] or matches['intext'][1] if self.page_content.count(text_feature) != 0: return True else: return False '''判別方法''' def get_result(self): if not self.r: return (False,'Not Discuz!') is_meta = self.meta_detect() res = self.robots_dz_xx_detect() is_dz_robots = res[0] version_info = res[1] print version_info is_intext = self.detect_intext() if is_meta or is_dz_robots or is_intext: #print 'Find Discuz!' if version_info: # return (True,'Find! Version:%s' % (version_info[0])) return (True,'%s' % (version_info[0])) else: return (True,'Version:Unknown') else: return (False,'Not Discuz!') if __name__ == '__main__': '''讀檔案識別''' f = open('discuz.txt','r') wf = open('results.txt','a') file_content = f.read() dz_url_list = file_content.split('\n') for url in dz_url_list: print url detector = DiscuzDetector(url) ret = detector.get_result() print ret if ret[0]: wf.write("%s\t%s\n" % (url,ret[1])) else: continue wf.close() f.close()
裡面的discuz.txt就是需要識別的域名列表檔案,輸出為results.txt,程式執行如下:
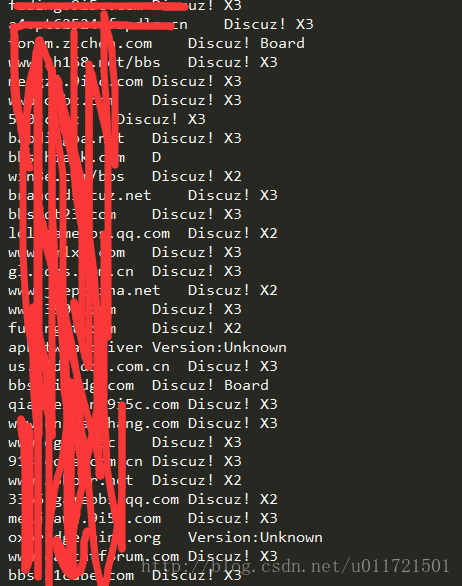
看來X3.x的版本用的挺多。
在某些情況下,需要做批量利用,對這個指令碼稍加修改就可以幫助識別出域名資料庫中的Discuz的站點。你需要做的只是把漏洞攻擊程式碼作為後續模組進行攻擊即可。
當然,關於批量利用,使用web指紋識別這種方法雖然準確性高,但是比較費時間,不適合大規模的掃描,這種情況下,一般都是Fuzzing跑字典去做。
使用Elasticsearch整合的效果如下:
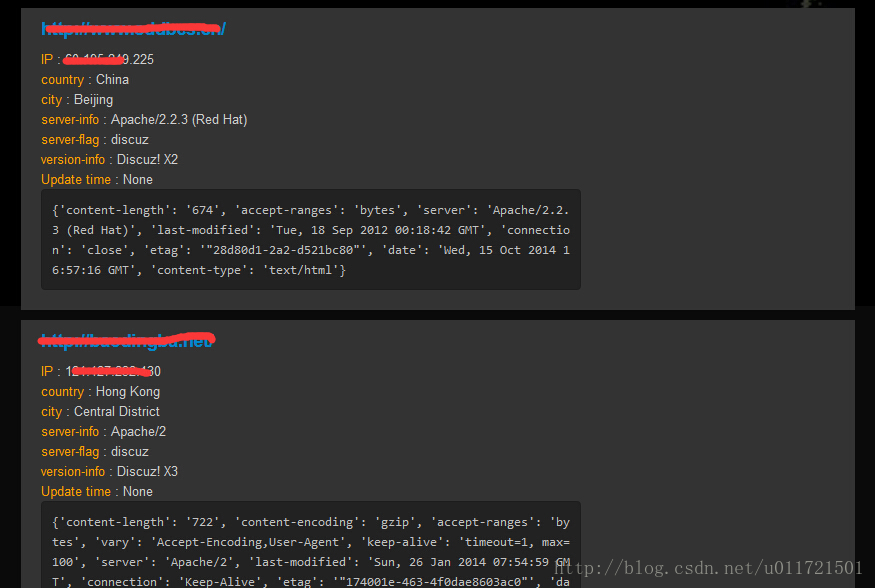
如果希望做的有模有樣的話,那麼就要新增後面的監控與漏洞攻擊模組了,使用RESTful介面做出API是最好的、最靈活的選擇,以後會逐漸完善,爭取做出zoomeye的雛形:-)
另外,轉載請註明出處啊大哥們!!