
各種機器學習分類模型的優缺點
KNN: 依賴資料,無數學模型可言。適用於可容易解釋的模型。
對異常值敏感,容易受到資料不平衡的影響。
Bayesian: 基於條件概率, 適用於不同維度之間相關性較小的時候,比較容易解釋。也適合增量訓練,不必要再重算一遍。應用:垃圾郵件處理。
Decision Tree: 此模型更容易理解不同屬性對於結果的影響程度(如在第幾層)。可以同時處理不同型別的資料。但因為追蹤結果只需要改變葉子節點的屬性,所以容易受到攻擊。應用:其他演算法的基石。
Random Forest: 隨機森林是決策樹的隨機整合,一定程度上改善了其容易被攻擊的弱點。適用於資料維度不太高(幾十)又想達到較高準確性的時候。不需要調整太多引數,適合在不知道適用什麼方法的時候先用下。
SVM: SVM儘量保持樣本間的間距,抗攻擊能力強,和RandomForest一樣是一個可以首先嚐試的方法。
對數機率迴歸:Logistic regression,不僅可以輸出結果還可以輸出其對應的概率。擬合出來的引數可以清晰地看到每一個feature對結果的影響。但是本質上是一個線性分類器,特徵之間相關度高時不適用。同時也要注意異常值的的影響。
Discriminat Analysis典型的是LDA,把高維資料投射到低維上,使資料儘可能分離。往往作為一個降維工具使用。但是注意LDA假設資料是正態分佈的(這也是與Fisher的區別)。
Neural Network. 準確來說還是一個黑箱,適用於資料量大的時候使用。
Ensemble-Boosting : 每次尋找一個可以解決當前錯誤的分類器,最後再通過權重加和。好處是自帶了特徵選擇,發現有效的特徵。也方便去理解高維資料。
Ensemble-Bagging: 訓練多個弱分類器投票解決。隨機選取訓練集,避免了過擬合。
Ensemble-Stacking: 以分類器的結果為輸入,再訓練一個分類器。一般最後一層用logistic Regression. 有可能過渡擬合,很少使用。
其他:
Maximum entropy model
最大熵模型不是一個分類器,是用來判斷預測結果好壞的。對於它來說,分類器預測是相當於是:針對樣本,給每個類一個出現概率。比如說樣本的特徵是:性別男。我的分類器可能就給出了下面這樣一個概率:高(60%),矮(40%)。
而如果這個樣本真的是高的,那我們就得了一個分數60%。最大熵模型的目標就是讓這些分數的乘積儘量大。
決策樹的數學基礎就是他。
LR其實就是使用最大熵模型作為優化目標的一個演算法
Expactation-Maximization
EM也不是分類器,而是一個思路,很多演算法基於此實現。如高斯混合模型,k-means聚類
Hidden Markov Model
馬爾科夫模型不是一個分類器,主要用於通過前面的狀態預測後面的狀態。主要作用與序列。用於語音識別效果較好。
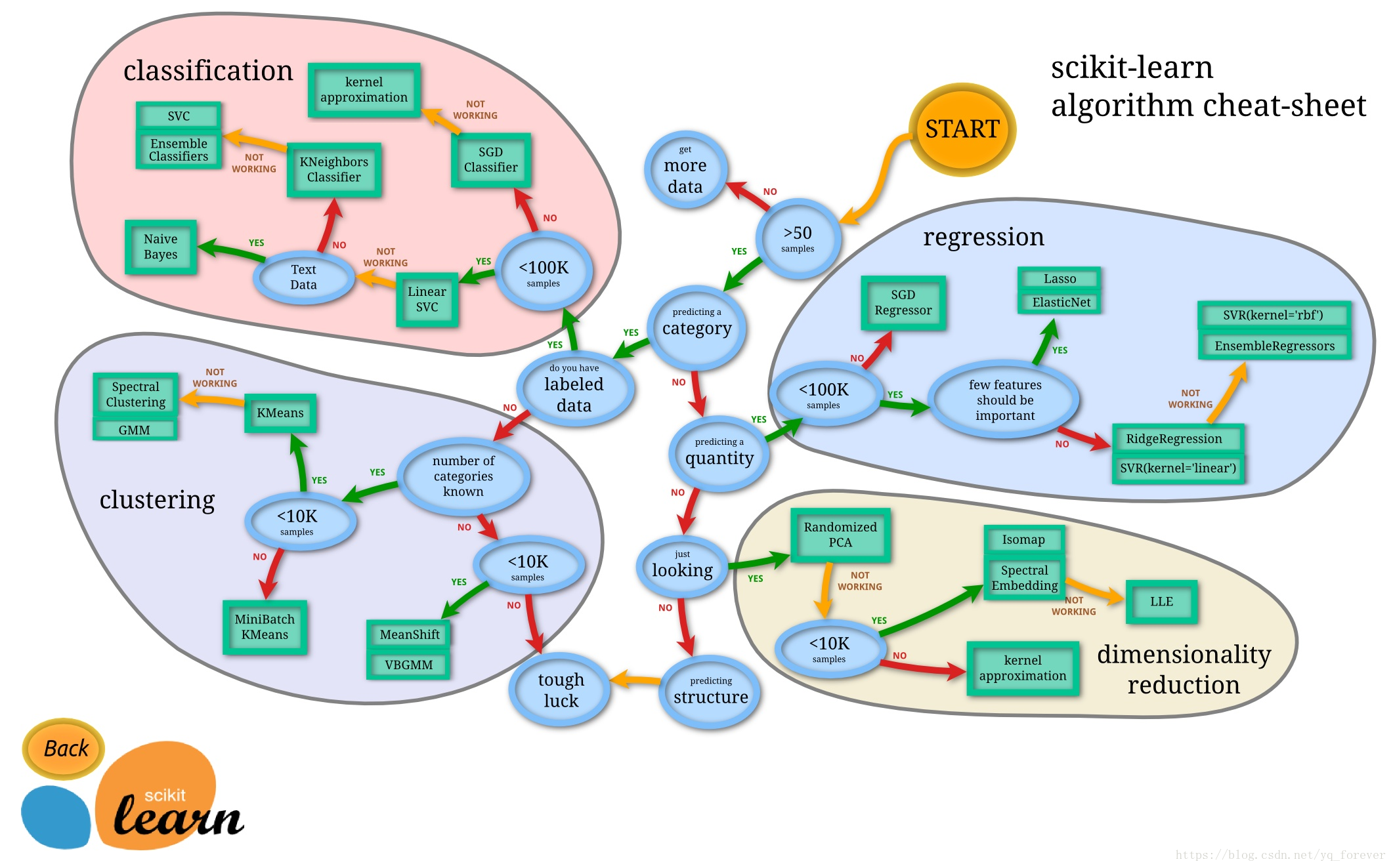
Reference:
[1]: Do we need hundreds of classifiers to solve real world classification problems.
Fernández-Delgado, Manuel, et al. J. Mach. Learn. Res 15.1 (2014)
[2]: An empirical evaluation of supervised learning in high dimensions.
Rich Caruana, Nikos Karampatziakis, and Ainur Yessenalina. ICML '08