
影象語義分割:從頭開始訓練deeplab v2系列之四【nyu v2資料集】
txt檔案:檔案中有資料集的名字列表的txt檔案,此處不同於原始碼,在pascal-context資料集上自己製作,訓練測試集列表
網路結構prototxt檔案: train.prototxt和solver.prototxt,分別在:DeepLabv2_VGG16 和 DeepLabv2_ResNet101
- 官網指令碼檔案: 三個sh檔案,建議使用指令碼檔案,初看雖不懂,但是比python版本的執行簡單很多
**注:本部落格只涉及指令碼版本的訓練,pascal-context的list檔案要自己根據資料集製作,或者使用此部落格的list
準備工作
1.必要工具
下載安裝matio,
2.資料集準備
本部落格採用的資料集為nyu v2,由其RGB影象及label組成,並沒有使用深度影象,資料大致為下圖:

原始資料集為voc2010,label即為上圖中所說的the annotations for training/validation set為ma,需要把mat檔案轉為png檔案
資料下載
# original PASCAL VOC 2010
cd ~/DL_dataset #save datasets 為$DATASETS
wget http://horatio.cs.nyu.edu/mit/silberman/nyu_depth_v2/nyu_depth_v2_labeled.mat 資料轉換
注:相關python指令碼檔案由以下模型訓練第一步的github下載得到
修改其中的資料路徑為你的trainval所在路徑,並在此路徑下建立labels檔案
cp ~/deeplab_v2/nyu/mat_image.py ~/DL_dataset/nyu
cp ~/deeplab_v2/nyu/mat_label.py ~/DL_dataset/nyu
cd ~/DL_dataset/nyu
python mat_image.py
python mat_label.py此時nyu資料資料夾產生兩個資料夾,分別存放RGB影象和標籤圖片
RGB三通道nyu影象
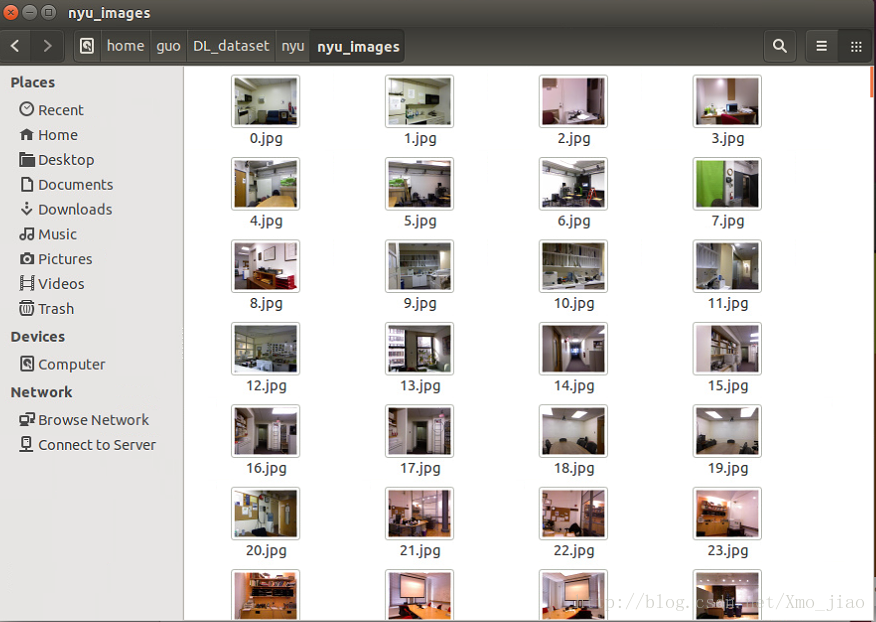
一通道nyu的標籤影象
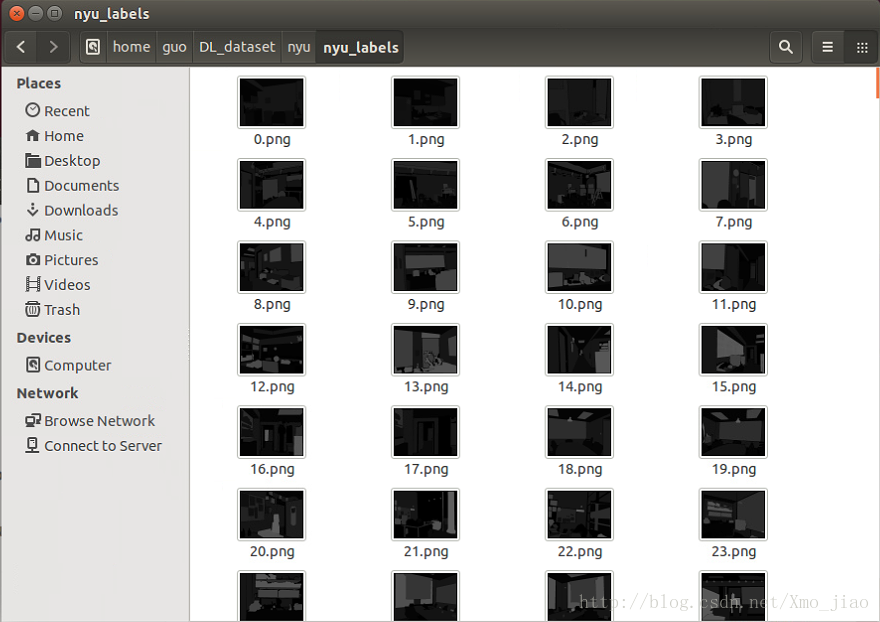
1.從github克隆train deeplab_v2資料夾
此github已經將資料夾結構建好,已儲存有原始碼的prototxt檔案,指令碼sh檔案,並已經自己製作好對應的資料集txt檔案,放置到對應資料夾下。由於官方model檔案大,不宜放GitHub,將在第3步下載。
cd ~
git clone [email protected].com:xmojiao/deeplab_v2.git2.將原始碼下載到此資料夾下,並編譯安裝deeplab caffe
cd deeplab_v2
git clone https://bitbucket.org/aquariusjay/deeplab-public-ver2.git
cd deeplab-public-ver2
make all
make pycaffe
make test # NOT mandatory
make runtest # NOT mandatory
3.將官方預訓練的model放置到pascal-context的model/deeplab_largeFOV
官方的初始化model為在image net上學習過的結果,train_iter_20000.caffemodel為在voc2012上訓練過的結果。此處我們可以使用init.caffemodel,train_iter_20000.caffemodel要自己生成
此處以VGG16訓練為例,model下載地址
也可在命令列下載並移動到相應資料夾,如下:
wget http://liangchiehchen.com/projects/released/deeplab_aspp_vgg16/prototxt_and_model.zip
unzip prototxt_and_model.zip
mv *caffemodel ~/deeplab_v2/nyu/model/deeplab_largeFOV
rm *prototxt4.deeplab2的script指令碼檔案run_pascal.sh 解析
目前我們已經準備好資料集和資料txt檔案,引數檔案model,網路結構檔案prototxt,和三個sh指令碼檔案,接下來只需要修改run_pascal.sh檔案,deeplabv2就可以run起來了。
注:與從頭開始訓練deeplab v2系列之三【pascal context資料集】一樣,修改了21類的label的類別數為459類
## MODIFY PATH for YOUR SETTING
ROOT_DIR=/home/guo/DL_dataset
CAFFE_DIR=../deeplab-public-ver2 #所下載編譯的deeplab原始碼目錄
CAFFE_BIN=${CAFFE_DIR}/.build_release/tools/caffe.bin
EXP=.
if [ "${EXP}" = "." ]; then
NUM_LABELS=459 #**本指令碼檔案與voc2012的最大區別之處,修改類別21為459類**
DATA_ROOT=${ROOT_DIR}/nyu
else
NUM_LABELS=0
echo "Wrong exp name"
fi
which model to train
########### voc12 ################
NET_ID=deeplab_largeFOV ##此處原檔名有問題應該改為deeplab_largeFOV
## Variables used for weakly or semi-supervisedly training
#TRAIN_SET_SUFFIX=
TRAIN_SET_SUFFIX=_aug #此處為選擇train_aug.txt資料集
#TRAIN_SET_STRONG=train
#TRAIN_SET_STRONG=train200
#TRAIN_SET_STRONG=train500
#TRAIN_SET_STRONG=train1000
#TRAIN_SET_STRONG=train750
#TRAIN_SET_WEAK_LEN=5000
DEV_ID=0
#####
## Create dirs
CONFIG_DIR=${EXP}/config/${NET_ID} #此處目錄為/nyu/config/deeplab_largeFOV
MODEL_DIR=${EXP}/model/${NET_ID}
mkdir -p ${MODEL_DIR}
LOG_DIR=${EXP}/log/${NET_ID}
mkdir -p ${LOG_DIR}
export GLOG_log_dir=${LOG_DIR}
## Run
RUN_TRAIN=1 #為1說明執行train
RUN_TEST=0 #為1說明執行test
RUN_TRAIN2=0
RUN_TEST2=0
## Training #1 (on train_aug)
if [ ${RUN_TRAIN} -eq 1 ]; then #r如果RUN_TRAIN為1
#
LIST_DIR=${EXP}/list
TRAIN_SET=train${TRAIN_SET_SUFFIX}
if [ -z ${TRAIN_SET_WEAK_LEN} ]; then #如果TRAIN_SET_WEAK_LEN長度為零則為真
TRAIN_SET_WEAK=${TRAIN_SET}_diff_${TRAIN_SET_STRONG}
comm -3 ${LIST_DIR}/${TRAIN_SET}.txt ${LIST_DIR}/${TRAIN_SET_STRONG}.txt > ${LIST_DIR}/${TRAIN_SET_WEAK}.txt
else
TRAIN_SET_WEAK=${TRAIN_SET}_diff_${TRAIN_SET_STRONG}_head${TRAIN_SET_WEAK_LEN}
comm -3 ${LIST_DIR}/${TRAIN_SET}.txt ${LIST_DIR}/${TRAIN_SET_STRONG}.txt | head -n ${TRAIN_SET_WEAK_LEN} > ${LIST_DIR}/${TRAIN_SET_WEAK}.txt
fi
#
MODEL=${EXP}/model/${NET_ID}/init.caffemodel #下載的vgg16或者ResNet101中的 model
#
echo Training net ${EXP}/${NET_ID}
for pname in train solver; do
sed "$(eval echo $(cat sub.sed))" \
${CONFIG_DIR}/${pname}.prototxt > ${CONFIG_DIR}/${pname}_${TRAIN_SET}.prototxt
done #此部分執行時如以下命令
CMD="${CAFFE_BIN} train \
--solver=${CONFIG_DIR}/solver_${TRAIN_SET}.prototxt \
--gpu=${DEV_ID}"
if [ -f ${MODEL} ]; then
CMD="${CMD} --weights=${MODEL}"
fi
echo Running ${CMD} && ${CMD}
fi
#train部分執行時,即以下執行命令 ../deeplab-public-ver2/.build_release/tools/caffe.bin train --solver=./config/deeplab_largeFOV/solver_train_aug.prototxt --gpu=0 --weights=./model/deeplab_largeFOV/init.caffemodel
#上述命令中,solver_train_aug.prototxt由solve.prototxt檔案複製而來,init.caffemodel為原始下載了的VGG16的model
## Test #1 specification (on val or test)
if [ ${RUN_TEST} -eq 1 ]; then
#
for TEST_SET in val; do
TEST_ITER=`cat ${EXP}/list/${TEST_SET}.txt | wc -l` #此處計算val.txt檔案中測試圖片個數,共1449個
MODEL=${EXP}/model/${NET_ID}/test.caffemodel
if [ ! -f ${MODEL} ]; then
MODEL=`ls -t ${EXP}/model/${NET_ID}/train_iter_*.caffemodel | head -n 1`
fi
#
echo Testing net ${EXP}/${NET_ID}
FEATURE_DIR=${EXP}/features/${NET_ID}
mkdir -p ${FEATURE_DIR}/${TEST_SET}/fc8
mkdir -p ${FEATURE_DIR}/${TEST_SET}/fc9
mkdir -p ${FEATURE_DIR}/${TEST_SET}/seg_score
sed "$(eval echo $(cat sub.sed))" \
${CONFIG_DIR}/test.prototxt > ${CONFIG_DIR}/test_${TEST_SET}.prototxt
CMD="${CAFFE_BIN} test \
--model=${CONFIG_DIR}/test_${TEST_SET}.prototxt \
--weights=${MODEL} \
--gpu=${DEV_ID} \
--iterations=${TEST_ITER}"
echo Running ${CMD} && ${CMD}
done
fi
#test部分執行時,即以下執行命令../deeplab-public-ver2/.build_release/tools/caffe.bin test --model=./config/deeplab_largeFOV/test_val.prototxt --weights=./model/deeplab_largeFOV/train_iter_20000.caffemodel --gpu=0 --iterations=154
#上述命令中,test_val.prototxt由test.prototxt檔案複製而來,train_iter_20000.caffemode由第一部分train得到的model5.deeplab跑起來
同前兩篇部落格一樣,此處我將train和test分開操作,即是修改run_pascal.sh指令碼中的如下程式碼:
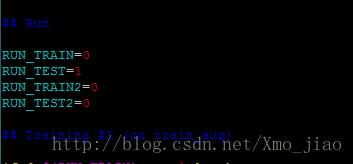
- RUN_TRAIN=1 時
cd ~/deeplab_v2/nyu
sh run_pascal.sh 2>&1|tee train.log
2>&1|tee train.log
指令的作用為在命令列展示log的同時,儲存log到當前目錄的train.log資料夾。前工作做的順利的話,你就能看到如下結果。
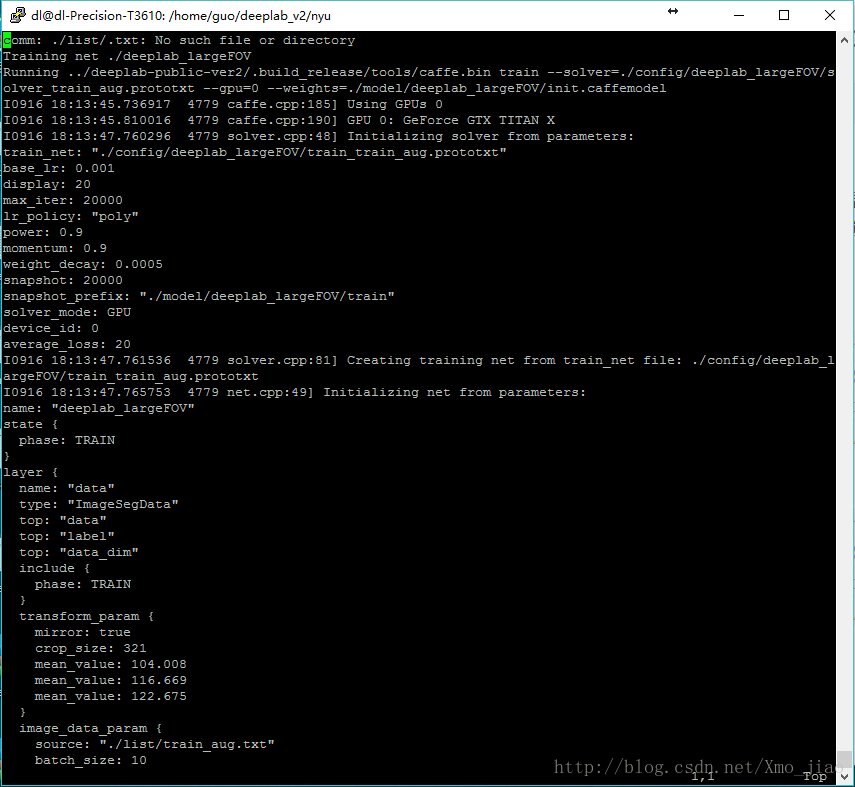
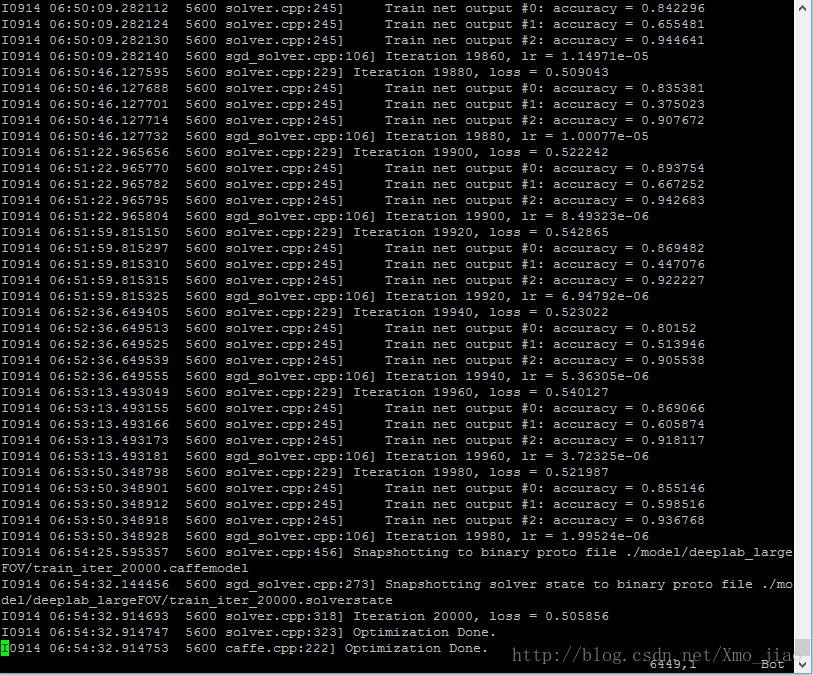
- RUN_TEST=1
目前沒發現作者有寫單張圖片測試的程式碼,但是當我們跑此部分run_test時,會得到png格式的測試結果
跑出測試結果
sh run_pascal.sh 2>&1|tee train.log
6.將test的結果mat檔案轉換為png檔案
同voc2012的測試結果一樣,test結束,你會在~/deeplab_v2/nyu/features/deeplab_largeFOV/val/fc8目錄下跑出mat格式的結果。
mat轉png圖片
-修改creat_labels.py中檔案目錄
cd ~/deeplab_v2/nyu/
vim create_labels_249.py
-在此目錄執行creat_labels_249.py
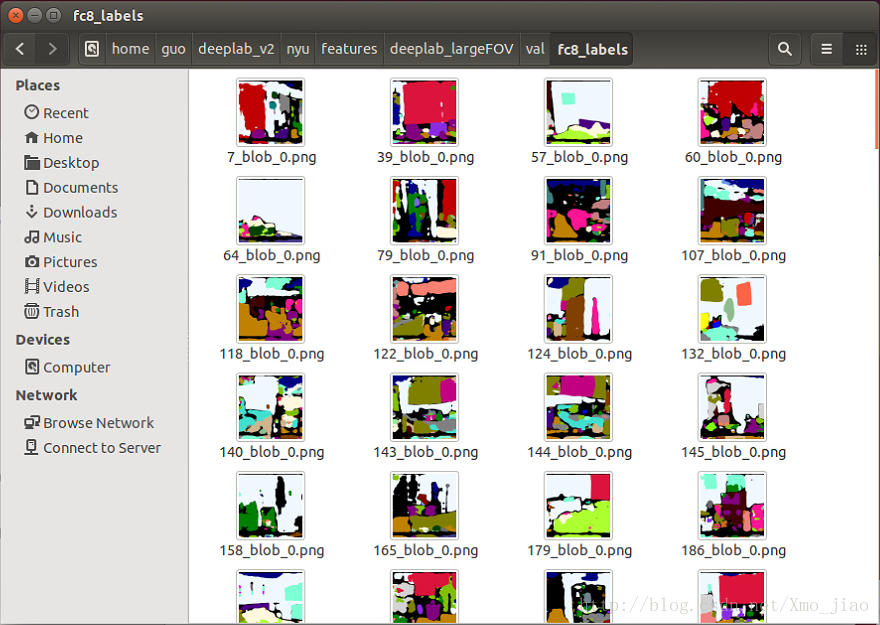
同pascal-context資料集影象採用全分割的方式一樣,本次訓練的資料集有459個類別,原來的21種顏色無法充分表達,但考慮到顏色類別有限,所以博主採用249種顏色來表達459種類物體。
python create_labels_249.py
pascal-context得到的結果如下

相關推薦
影象語義分割:從頭開始訓練deeplab v2系列之三【pascal-context資料集】
在之前的部落格已經講過deeplab v2原始碼解析與基於VOC2012資料集的訓練,本部落格基於pascal-context資料集進行fine tuning txt檔案:檔案中有資料集的名字列表的txt檔案,此處不同於原始碼,在pascal-con
影象語義分割:從頭開始訓練deeplab v2系列之一【原始碼解析】
好記性不如爛筆頭, 最近用Deeplab v2跑的影象分割,現記錄如下。 官方原始碼地址如下:https://bitbucket.org/aquariusjay/deeplab-public-ver2/overview 但是此原始碼只是為deeplab網路
影象語義分割:從頭開始訓練deeplab v2系列之四【nyu v2資料集】
txt檔案:檔案中有資料集的名字列表的txt檔案,此處不同於原始碼,在pascal-context資料集上自己製作,訓練測試集列表 網路結構prototxt檔案: train.prototxt和solver.prototxt,分別在:DeepLa
【貓狗資料集】使用學習率衰減策略並邊訓練邊測試
資料集下載地址: 連結:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取碼:2xq4 建立資料集:https://www.cnblogs.com/xiximayou/p/12398285.html 讀取資料集:https://www.cnblogs.com/x
影象語義分割 DeepLab v3+ 訓練自己的資料集
環境:ubuntu 16.04 + TensorFlow 1.6.1 + cuda 9.0 + cudnn 7.0 +python2.7 tensorflow 專案連結 https://github.com/tensorflow/models.git下載後解壓,所需要的工程在
DeepLab:深度卷積網路,多孔卷積 和全連線條件隨機場 的影象語義分割 Semantic Image Segmentation with Deep Convolutional Nets, Atro
深度卷積網路,多孔卷積 和全連線條件隨機場 的影象語義分割 Taylor Guo, 2017年5月03日 星期三 摘要 本文的主要任務是深度學習的影象語義分割,主要有3個方面的貢獻,有重要的實踐價值。首先, 用上取樣濾波器進行卷積,或“多孔卷積”,
語義分割:使用關係圖輔助影象分割-Capsule Network、IceNet
文章:在SceneParsing上準確率暫時得到第一的IceNet https://hszhao.github.io/projects/icnet/ 文章:https://arxiv.org/pdf/1704.08545.pdf 優化方
影象語義分割標註工具labelme製作自己的資料集用於mask-rcnn訓練
labelme(標註mask資料集用的) windows python2 pip install pyqt pip install labelme python3 pip install pyqt5 pip install labelm
轉:從頭開始編寫基於隱含馬爾可夫模型HMM的中文分詞器
lan reverse single trim 地址 note str rip resources http://blog.csdn.net/guixunlong/article/details/8925990 從頭開始編寫基於隱含馬爾可夫模型HMM的中文分詞器之一 - 資
影象語義分割技術
https://www.leiphone.com/news/201705/YbRHBVIjhqVBP0X5.html 大多數人接觸 “語義” 都是在和文字相關的領域,或語音識別,期望機器能夠識別你發出去的訊息或簡短的語音,然後給予你適當的反饋和回覆。嗯,看到這裡你應該已經猜到了,影象領域也是存
基於深度學習的影象語義分割技術概述之4常用方法 5.4未來研究方向
https://blog.csdn.net/u014593748/article/details/72794459 本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmen
keras 學習筆記:從頭開始構建網路處理 mnist
全文參考 《 基於 python 的深度學習實戰》 import numpy as np from keras.datasets import mnist from keras.models import Sequential from keras.layers import Den
影象語義分割文章彙總(附論文連結和公開程式碼)
吶,我也是做影象分割的啦,最近看到有大佬整理了影象分割方面最新的論文,覺得很有幫助,就轉載過來了,感覺又有很多要學的內容了。 Semantic Segmentation Adaptive Affinity Field for Sem
【影象語義分割】Semantic Segmentation Suite in TensorFlow---GitHub_Link
Semantic Segmentation Suite in TensorFlow News What's New Added the BiSeNet model from ECCV 2018! Added the Dense Decoder Shor
ASP.NET Core 2.0和Angular 4:從頭開始構建用於車輛管理的Web應用程式
目錄 介紹 背景 使用程式碼 I)伺服器端 a)先決條件 b)設定專案 c)設定資料庫 d)使用AutoMapper e)使用Swagger f)執行API II)客戶端 a)先決條件 b)設定專案 c)實現服務 d)
基於深度學習的影象語義分割演算法綜述(截止20180715)
這篇文章講述卷積神經網路在影象語義分割(semantic image segmentation)的應用。影象分割這項計算機視覺任務需要判定一張圖片中特定區域的所屬類別。 這個影象裡有什麼?它在影象中哪個位置? 更具體地說,影象語義分割的目標是將影象的每個畫素所
影象語義分割之FCN和CRF
前言 (嘔血製作啊!)前幾天剛好做了個影象語義分割的彙報,把最近看的論文和一些想法講了一下。所以今天就把它總結成文章啦,方便大家一起討論討論。本文只是展示了一些比較經典和自己覺得比較不錯的結構,畢竟這方面還是有挺多的結構方法了。 介紹 影象語義分
如何用Keras從頭開始訓練一個在CIFAR10上準確率達到89%的模型
•https://zhuanlan.zhihu.com/p/29214791CIFAR10 是一個用於影象識別的經典資料集,包含了10個型別的圖片。該資料集有60000張尺寸為 32 x 32 的彩色圖片,其中50000張用於訓練,10000張用於測試。[CIFAR10]在幾
使用深度學習技術的影象語義分割最新綜述
http://abumaster.com/2017/07/10/%E4%BD%BF%E7%94%A8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%8A%80%E6%9C%AF%E7%9A%84%E5%9B%BE%E5%83%8F%E8%AF
當前主流的深度學習影象語義分割模型解析
轉載自【量子位】公眾號 QbitAI原文地址:http://www.sohu.com/a/155907339_610300影象語義分割就是機器自動從影象中分割出物件區域,並識別其中的內容。量子位今天推薦的這篇文章,回顧了深度學習在影象語義分割中的發展歷程。釋出這篇文章的Qur