正則的應用--讀取本地檔案2--網頁版解析--豆瓣
阿新 • • 發佈:2019-02-17
第一部分
讀取本地檔案1.進入豆瓣主頁,獲取其網頁原始碼,儲存下載到本地,由於程式碼過多,這裡就不展現出來了
2.進入影評主頁,獲取原始碼,儲存下載到本地
3.在本地檔案中進行解析
test.json檔案中程式碼為:
{"body":"\n \n \n \n \n <div class=\"main-bd\">\n\n\n \n \n \n\n <div id=\"link-report\">\n <div property=\"v:description\"\n class=\"review-content clearfix\"\n data-author=\"王某某\"\n data-url=\"https:\/\/movie.douban.com\/review\/1506795\/\"\n data-original=\"0\">\n 我個人理解的故事脈絡:<br>6個星期前,黑道巨擘Keyser Soze在正常社會中的隱身身份扮演者---小混混kint因為一件很普通的案件被帶到警察局問詢,問詢的過程中結識了同樣倒黴蛋McManus、Fenster、Todd Hockney以及好久以前認識自己的前警察But Keaton,keaton和其他三人很熟,因此可以引申到他們四人只是認為kint是一個普通的小混混而已,對他的身份毫無懷疑。在監獄中,Mcmanus提出為了向不長眼的警察們報復一下,說出了一個搶劫方案:去搶劫受警察計程車護送的攜帶鑽石準備交易的黑道人物。這樣既可以報復警察,又可以得到一批價值不菲的鑽石。<br>此時的kint覺察司法部的線人Arturo Marquez知道自己過多的底細,但苦於線人受匈牙利幫的保護,殺害他的難度比較大,正好此時有這幫新認識的小兄弟,完全可以來個借刀殺人併成功脫身,kint作為如此強大的大佬,當然有能力自己解決線人的問題,但不要忘記,kint和政界有千絲萬縷的聯絡,他不能也不可能搞成一次大的火拼,這樣就會過於張揚、暴露。而此時正好有幾個“可愛”的小朋友撞到“槍口”之上,並且他們這個團隊具有相當強的水準:聰明而狡猾的狠角色McManus、Fenster,爆破專家:Todd Hockney,身手不錯、手段高明、心狠手辣並急於想走上致富道路前警察:Keaton,當然,如此聰明的大佬kint不會傻到讓團隊直接去幹掉線人去,他要先驗一下本團隊的成色,正好有此機會。他成功說服了keaton的加入,結果是明顯的,戰鬥力強勁的團隊將劫持警察計程車案件辦理的天衣無縫,並且讓警察惹上了大麻煩而無暇去尋找他們。<br>鑽石到手後,當然得銷贓,kint通過自己安排的銷贓人redfoot成功將鑽石出手,並引向這個團隊去攻克第二件搶劫案,當然,失敗是註定的,因為kint最終的目標是讓團隊去做掉線人,這一切都是kint安排好的合理的過度(redfoot這個角色是真實存在的,名字是杜撰的而已,kint向警察複述時是說Mcmanus認識的銷贓人redfoot,這肯定是假話,因為是由redfoot這條線索引申出小林律師這個角色並引伸出Keyser Soze這個角色的,因此銷贓人redfoot根本就是kint找來的),搶劫Saul失敗後,他們四個人發現自己已經深深陷入Keyser Soze安排好的道路,不得不為Keyser Soze去幹掉Keyser Soze的對手---那幫匈牙利人,其實,對於kint來說,匈牙利人只是一個合理的藉口、誘餌罷了,真正需要幹掉的是線人。他們中有人試圖逃跑,被無情的殺害,於是又計劃幹掉接線人---小林律師,結果可以預想,又是以失敗告終,因為他們當中有叛徒---kint的存在,kint成功瞭解到所有人的軟肋,並控制他們的家人,使得他們不得不順利聽從小林律師的建議,去幹掉那幫匈牙利人,同時又可得到不菲的報酬,九千一百萬的現金,小林律師說的毒品只是一個混淆視聽的錯誤的資訊,因為根本就沒有毒品的存在。<br>四人團隊出發了,進展很順利,在爆破專家的幫助下,炸掉了外圍的一些人。Kint是參加戰鬥的,他向警察複述keaton讓自己斷後肯定是撒謊,他要幹掉這次戰鬥中存活的其他同伴,因為他需要的是這次戰鬥中除他之外不能由任何生還者,當Hockney開啟車門開箱看贓款的同時,kint幹掉了他,然後kint又用刀子做掉了另一個同伴,最後是keaton,同時他親手結果了線人。我想不太明白的是他為什麼沒有逃走?可能是當時警察已經趕到抑或他覺得他自有能力成功解脫而無需逃跑。<br>在警察局,kint運用自己的社會關係讓自己很簡單就被保釋,但同時他聽說昨晚的案件有一個匈牙利人獲救,他不清楚對方究竟看到了什麼,因此,當警官kujan提出向他問案時他並沒有推辭,併成功運用自己的智慧漫天謊言的將自以為是的警官kujan引向誤區,成功利用了kujan對keaton這個角色的誤解,並根據兩人談話時得到的資訊和kujan進行有效地周旋,成功將自己脫罪,併成功“無罪”的走出警察廳。個人覺得最後kujan的覺悟和kint頭像傳真的出現有點巧合,畫蛇添足。<br><br>主要人物:<br>McManus(打家劫舍好手)<br>Fenster(McManus好友)<br>Todd Hockney(爆破專家)<br>But Keaton(前警察,力求改過自新,但又被警察以莫須有的罪名問詢,心理不可承受)<br>Edie Finneran(律師,Kenton女友,真實存在的人物)<br>Verbal kint(跛子只是他慣用的一個小角色,他和keaton好久以前見過一兩次,不過給keaton的印象是個小角色)<br>Keyser Soze(這只是一個代號,好像God一樣,你能確定它存在嗎?但你又能確定他不存在嗎?kint 只是soze慣用的一個角色)<br>小林(律師,kint的得力手下之一,小林不過是他的一個符號罷了)<br><br>主要疑問之見解:<br>1、首先要肯定的是影片開始的那段the last night 是真實的發生<br>2、五個人確實是因為莫須有的罪名被問詢罷了,也可能是另外完全不相干的五個人,但關鍵是這次是和kint 相關而已,kint 作為一個遊離在社會邊緣的“小角色”,當然有可能因為某一案件被警察問訊,這也更符合kint的角色,小混混嗎。所以懷疑這是kint事先安排好五個人相識並不成立,只不過湊巧這次是他們五人罷了。<br>3、倖存的匈牙利人完全是個以外,kint 在船上解決完所有人之後並沒有意識到還有幸存者,所以他認為所有的謊言他可以任意編造。但當他當天被帶進監獄後應該知道還有幸存者,作為能量無邊的Keyser Soze,不會沒有他的手下想辦法通知他這一切的。作為Boss,當然在黑、白兩道都有自己的兄弟協助自己。所以當地方檢察官提審他之前,只和他律師談了五分鐘然後就like the bogeyman,市長親自上門過問,州長打來電話關心,老警官說具有政治色彩,這時,你還能相信kint 只是一個遊離在社會邊緣的小混混嗎,他絕對具有很強的社會背景,所以這時可以看出kint 這個人很複雜。<br>4、為什麼kint 在即將兩個小時後被保釋,還會接受Dave Kujan警官的詢問,我認為有以下三個原因:1、kint 只知道現場有幸存者,但並不知道是怎樣的角色,在昨晚事件中扮演怎樣的地位。2、既然是倖存者,就有可能在隱蔽的地點看到了一些真實的情況,而kint 急需想要了解倖存者的真實情況。3、接受詢問時,kint剛開始也許是想通過自己的智商和kujan警官周旋,因為kujan畢竟也沒有掌握kint犯罪的事實,而當kujan警官一直引導kint將一切的幕後真正黑手指向keaton時,kint當然對此是“責無旁貸”,既可以成功的栽贓於死人keaton,作為死無對證,又可以引導kujan警官去尋找他認為還活著其實早已死去的keaton,完全把自以為聰明的kujan警官徹底引入死衚衕。<br>5、關於kint 向kujan複述傳說中的Soze的軼事應該是真實發生的,因為在船上時老線人當意識到Keyser Soze到來時恐懼的表情就能看出Soze是多麼令人可怕的一個人,kint 就是信口開河也不能也沒有必要編出自己作為Soze時所具備的心狠手辣。<br>6、Kenton女朋友的身份不用懷疑,第一,她和keaton肯定是男女朋友;第二,關於線人的案子絕對是kint 有意安排的,這樣的好處是即穩住了線人,也成功掌握了keaton的軟肋。最後正好殺人滅口,來個死無對證。第三,kenton在監獄中和其他四人的對話可以看出keaton確實想改邪歸正,雖然這都是由kint向警察複述的,但基本可以肯定是真實的情景再現,因為此時kint還並不清楚keaton在kujan警官心目中的“形象”,也並沒有從kujan警官口中套出任何有價值的資訊,因此此時的資訊應該是真實的,其他四個人的資訊完全杜撰不得,因為船上有三個人的屍體,身份很好確定,所以kint複述五個人被警察以莫須有的罪名問詢的情形基本應該是真實可信的。<br>7、小林作為kint的代言人,絕對是真實存在的,只不過小林只是個kint從辦公室隨處看到的一個代號而已。<br><br>本片主要看點是凱文史派西的表演,個人覺得故事結構和《洛城機密》有點差距。\n <\/div>\n\n \n \n <a rel=\"nofollow\" href=\"javascript:;\" data-rid=\"1506795\" class=\"report report_review right\">舉報<\/a>\n\n\n \n\n <script type=\"text\/html\" id=\"template-report-popup\">\n <div id='report_value'>\n <ul>\n <li>\n <label>\n <input type='radio' name='reason' value='0'\n checked\n \/> 廣告或垃圾資訊\n <\/label>\n <\/li>\n <li>\n <label>\n <input type='radio' name='reason' value='1'\n \/> 色情、淫穢或低俗內容\n <\/label>\n <\/li>\n <li>\n <label>\n <input type='radio' name='reason' value='2'\n \/> 激進時政或意識形態話題\n <\/label>\n <\/li>\n <li>\n <label>\n <input type='radio' name='reason' value='other' \/> 其他原因\n <\/label>\n <\/li>\n <\/ul>\n <\/div>\n <div class='bn-flat'>\n <input type='submit' class='btn-report' value='舉報'>\n <\/div>\n <\/script>\n\n\n <\/div>\n\n <div class=\"main-author\">\n \n\n <\/div>\n <\/div>\n\n <div class=\"main-ft\">\n <div class=\"main-panel\" name=\"1506795\">\n \n\n\n\n<div class=\"main-panel-useful\" data-rid=\"1506795\" data-is_owner=\"false\" data-can_vote=\"true\">\n <button class=\"btn useful_count 1506795 \">\n 有用 642\n <\/button>\n <button class=\"btn useless_count 1506795 \">\n 沒用 163\n <\/button>\n <span class=\"spoiler not-reported \" data-rid=\"1506795\"> 這篇影評有劇透 <\/span>\n<\/div>\n\n <\/div>\n <\/div>\n","vote_script":"\n 'use strict';\n\n\/* global $, alert, get_cookie *\/\n\/* used in movie subject page *\/\n\n(function () {\n var CONST_REVIEW_VOTE = {\n 'useful_count': ['有用', '\/j\/review\/{REVIEW_ID}\/useful'],\n 'useless_count': ['沒用', '\/j\/review\/{REVIEW_ID}\/useless'],\n 'spoiler': ['劇透提醒已提交,謝謝', '\/j\/review\/{REVIEW_ID}\/spoiler']\n };\n\n var regDisabled = \/disabled\/,\n regVoteType = \/(\\w+_count)\/,\n regSpoiler = \/spoiler\/;\n\n var votePanels = document.querySelectorAll('.main-panel-useful'),\n votePanel = null,\n rid = '';\n\n var isAuthor = function isAuthor(votePanel) {\n return votePanel && votePanel.getAttribute('data-is_owner') === 'true';\n };\n\n var canVote = function canVote(votePanel) {\n return votePanel && votePanel.getAttribute('data-can_vote') === 'true';\n };\n\n var handleVote = function handleVote(e) {\n e.stopPropagation();\n\n var target = e.target;\n var cn = target.className,\n match = cn.match(regVoteType) || cn.match(regSpoiler),\n type = '',\n API_VOTE = '',\n voteTxt = '';\n\n if (cn.match(regDisabled)) {\n return;\n }\n\n if (match) {\n if (isAuthor(e.currentTarget)) {\n return alert('不能給自己投票噢');\n }\n\n if (!canVote(e.currentTarget)) {\n return alert('該電影還未上映,不能投票噢');\n }\n\n type = match[0]; \/\/ 'useful', 'useless', 'spoiler'\n voteTxt = CONST_REVIEW_VOTE[type][0];\n API_VOTE = CONST_REVIEW_VOTE[type][1];\n rid = e.currentTarget.getAttribute('data-rid');\n API_VOTE = API_VOTE.replace('{REVIEW_ID}', rid);\n } else if (!match || !rid) {\n return;\n }\n\n var voteReq = $.post(API_VOTE, { 'ck': get_cookie('ck') }, function (res) {\n if (res.r == 0) {\n if (type === 'spoiler') {\n return handleSpoiler();\n }\n countVote(res, type);\n }\n });\n\n voteReq.fail(function () {\n alert('網路錯誤');\n }).always(function () {\n \/\/ console.log('vote ')\n });\n };\n\n var handleSpoiler = function handleSpoiler(type) {\n var reviewElem = document.getElementById(rid);\n var spoilerElem = reviewElem.querySelector('.spoiler');\n spoilerElem.innerText = CONST_REVIEW_VOTE['spoiler'][0];\n spoilerElem.className = spoilerElem.className.replace('not-reported', 'disabled');\n };\n\n var countVote = function countVote(res, type) {\n var reviewElem = document.getElementById(rid);\n for (var i in CONST_REVIEW_VOTE) {\n if (res[i] !== undefined) {\n var countTxt = CONST_REVIEW_VOTE[i][0] + ' ' + res[i],\n countElem = reviewElem.querySelector('.' + i),\n _cn = countElem.className;\n\n \/\/ 從沒投過票 || 已經投票過\n if (i === type || i !== type && _cn.match(regDisabled)) {\n countElem.classList.toggle('disabled');\n }\n countElem.innerHTML = countTxt;\n }\n }\n };\n\n var len = votePanels.length;\n for (var i = 0; i < len; i++) {\n votePanel = votePanels[i];\n votePanel && votePanel.addEventListener('click', handleVote, false);\n }\n})(document);\n","votes":{"useful_count":642,"is_useless":"","is_useful":"","usecount":642,"totalcount":805,"useless_count":163},"html":"我個人理解的故事脈絡:<br>6個星期前,黑道巨擘Keyser Soze在正常社會中的隱身身份扮演者---小混混kint因為一件很普通的案件被帶到警察局問詢,問詢的過程中結識了同樣倒黴蛋McManus、Fenster、Todd Hockney以及好久以前認識自己的前警察But Keaton,keaton和其他三人很熟,因此可以引申到他們四人只是認為kint是一個普通的小混混而已,對他的身份毫無懷疑。在監獄中,Mcmanus提出為了向不長眼的警察們報復一下,說出了一個搶劫方案:去搶劫受警察計程車護送的攜帶鑽石準備交易的黑道人物。這樣既可以報復警察,又可以得到一批價值不菲的鑽石。<br>此時的kint覺察司法部的線人Arturo Marquez知道自己過多的底細,但苦於線人受匈牙利幫的保護,殺害他的難度比較大,正好此時有這幫新認識的小兄弟,完全可以來個借刀殺人併成功脫身,kint作為如此強大的大佬,當然有能力自己解決線人的問題,但不要忘記,kint和政界有千絲萬縷的聯絡,他不能也不可能搞成一次大的火拼,這樣就會過於張揚、暴露。而此時正好有幾個“可愛”的小朋友撞到“槍口”之上,並且他們這個團隊具有相當強的水準:聰明而狡猾的狠角色McManus、Fenster,爆破專家:Todd Hockney,身手不錯、手段高明、心狠手辣並急於想走上致富道路前警察:Keaton,當然,如此聰明的大佬kint不會傻到讓團隊直接去幹掉線人去,他要先驗一下本團隊的成色,正好有此機會。他成功說服了keaton的加入,結果是明顯的,戰鬥力強勁的團隊將劫持警察計程車案件辦理的天衣無縫,並且讓警察惹上了大麻煩而無暇去尋找他們。<br>鑽石到手後,當然得銷贓,kint通過自己安排的銷贓人redfoot成功將鑽石出手,並引向這個團隊去攻克第二件搶劫案,當然,失敗是註定的,因為kint最終的目標是讓團隊去做掉線人,這一切都是kint安排好的合理的過度(redfoot這個角色是真實存在的,名字是杜撰的而已,kint向警察複述時是說Mcmanus認識的銷贓人redfoot,這肯定是假話,因為是由redfoot這條線索引申出小林律師這個角色並引伸出Keyser Soze這個角色的,因此銷贓人redfoot根本就是kint找來的),搶劫Saul失敗後,他們四個人發現自己已經深深陷入Keyser Soze安排好的道路,不得不為Keyser Soze去幹掉Keyser Soze的對手---那幫匈牙利人,其實,對於kint來說,匈牙利人只是一個合理的藉口、誘餌罷了,真正需要幹掉的是線人。他們中有人試圖逃跑,被無情的殺害,於是又計劃幹掉接線人---小林律師,結果可以預想,又是以失敗告終,因為他們當中有叛徒---kint的存在,kint成功瞭解到所有人的軟肋,並控制他們的家人,使得他們不得不順利聽從小林律師的建議,去幹掉那幫匈牙利人,同時又可得到不菲的報酬,九千一百萬的現金,小林律師說的毒品只是一個混淆視聽的錯誤的資訊,因為根本就沒有毒品的存在。<br>四人團隊出發了,進展很順利,在爆破專家的幫助下,炸掉了外圍的一些人。Kint是參加戰鬥的,他向警察複述keaton讓自己斷後肯定是撒謊,他要幹掉這次戰鬥中存活的其他同伴,因為他需要的是這次戰鬥中除他之外不能由任何生還者,當Hockney開啟車門開箱看贓款的同時,kint幹掉了他,然後kint又用刀子做掉了另一個同伴,最後是keaton,同時他親手結果了線人。我想不太明白的是他為什麼沒有逃走?可能是當時警察已經趕到抑或他覺得他自有能力成功解脫而無需逃跑。<br>在警察局,kint運用自己的社會關係讓自己很簡單就被保釋,但同時他聽說昨晚的案件有一個匈牙利人獲救,他不清楚對方究竟看到了什麼,因此,當警官kujan提出向他問案時他並沒有推辭,併成功運用自己的智慧漫天謊言的將自以為是的警官kujan引向誤區,成功利用了kujan對keaton這個角色的誤解,並根據兩人談話時得到的資訊和kujan進行有效地周旋,成功將自己脫罪,併成功“無罪”的走出警察廳。個人覺得最後kujan的覺悟和kint頭像傳真的出現有點巧合,畫蛇添足。<br><br>主要人物:<br>McManus(打家劫舍好手)<br>Fenster(McManus好友)<br>Todd Hockney(爆破專家)<br>But Keaton(前警察,力求改過自新,但又被警察以莫須有的罪名問詢,心理不可承受)<br>Edie Finneran(律師,Kenton女友,真實存在的人物)<br>Verbal kint(跛子只是他慣用的一個小角色,他和keaton好久以前見過一兩次,不過給keaton的印象是個小角色)<br>Keyser Soze(這只是一個代號,好像God一樣,你能確定它存在嗎?但你又能確定他不存在嗎?kint 只是soze慣用的一個角色)<br>小林(律師,kint的得力手下之一,小林不過是他的一個符號罷了)<br><br>主要疑問之見解:<br>1、首先要肯定的是影片開始的那段the last night 是真實的發生<br>2、五個人確實是因為莫須有的罪名被問詢罷了,也可能是另外完全不相干的五個人,但關鍵是這次是和kint 相關而已,kint 作為一個遊離在社會邊緣的“小角色”,當然有可能因為某一案件被警察問訊,這也更符合kint的角色,小混混嗎。所以懷疑這是kint事先安排好五個人相識並不成立,只不過湊巧這次是他們五人罷了。<br>3、倖存的匈牙利人完全是個以外,kint 在船上解決完所有人之後並沒有意識到還有幸存者,所以他認為所有的謊言他可以任意編造。但當他當天被帶進監獄後應該知道還有幸存者,作為能量無邊的Keyser Soze,不會沒有他的手下想辦法通知他這一切的。作為Boss,當然在黑、白兩道都有自己的兄弟協助自己。所以當地方檢察官提審他之前,只和他律師談了五分鐘然後就like the bogeyman,市長親自上門過問,州長打來電話關心,老警官說具有政治色彩,這時,你還能相信kint 只是一個遊離在社會邊緣的小混混嗎,他絕對具有很強的社會背景,所以這時可以看出kint 這個人很複雜。<br>4、為什麼kint 在即將兩個小時後被保釋,還會接受Dave Kujan警官的詢問,我認為有以下三個原因:1、kint 只知道現場有幸存者,但並不知道是怎樣的角色,在昨晚事件中扮演怎樣的地位。2、既然是倖存者,就有可能在隱蔽的地點看到了一些真實的情況,而kint 急需想要了解倖存者的真實情況。3、接受詢問時,kint剛開始也許是想通過自己的智商和kujan警官周旋,因為kujan畢竟也沒有掌握kint犯罪的事實,而當kujan警官一直引導kint將一切的幕後真正黑手指向keaton時,kint當然對此是“責無旁貸”,既可以成功的栽贓於死人keaton,作為死無對證,又可以引導kujan警官去尋找他認為還活著其實早已死去的keaton,完全把自以為聰明的kujan警官徹底引入死衚衕。<br>5、關於kint 向kujan複述傳說中的Soze的軼事應該是真實發生的,因為在船上時老線人當意識到Keyser Soze到來時恐懼的表情就能看出Soze是多麼令人可怕的一個人,kint 就是信口開河也不能也沒有必要編出自己作為Soze時所具備的心狠手辣。<br>6、Kenton女朋友的身份不用懷疑,第一,她和keaton肯定是男女朋友;第二,關於線人的案子絕對是kint 有意安排的,這樣的好處是即穩住了線人,也成功掌握了keaton的軟肋。最後正好殺人滅口,來個死無對證。第三,kenton在監獄中和其他四人的對話可以看出keaton確實想改邪歸正,雖然這都是由kint向警察複述的,但基本可以肯定是真實的情景再現,因為此時kint還並不清楚keaton在kujan警官心目中的“形象”,也並沒有從kujan警官口中套出任何有價值的資訊,因此此時的資訊應該是真實的,其他四個人的資訊完全杜撰不得,因為船上有三個人的屍體,身份很好確定,所以kint複述五個人被警察以莫須有的罪名問詢的情形基本應該是真實可信的。<br>7、小林作為kint的代言人,絕對是真實存在的,只不過小林只是個kint從辦公室隨處看到的一個代號而已。<br><br>本片主要看點是凱文史派西的表演,個人覺得故事結構和《洛城機密》有點差距。"}
4.之前提到ip被封,掛了代理ip之後,也無法獲取到資料
掛載代理ip方法如下:
5.檔案中需要引入的包headers = { 'Host': "douban.com", 'User-Agent': agent.random, 'Accept': 'text/css,*/*;q=0.1', 'Cookie': '' } proxy = request.ProxyHandler({ 'http': '61.135.217.7:80' }) openner = request.build_opener(proxy) request.install_opener(openner) req = request.Request('https://movie.douban.com/top250', headers=headers) resp = openner.open(req)
# -*- coding:utf-8 -*-
from urllib import request
import codecs
import re
import json
import time
from fake_useragent import UserAgent
agent = UserAgent()6.程式碼思路:
1.在get_html 中根據url地址,獲取目標資料,判斷請求的是否為完整影評的json資料,如果是將返回的資料賦值給json屬性,如果不是就賦值html屬性
2.在parse_list函式中,根據正則解析當前頁的所有電影的連結,拼接完整的影評連結地址,傳送請求,解析影評資料, 找到下一頁的連結,傳送請求,重新呼叫parse_list函式解析下一頁資料....
3.在parse_comments()函式中,根據正則解析當前頁的所有影評資訊,for遍歷,找到每一個影評id,根據id拼接完整的影評地址,傳送請求,解析完整影評,處理資料,提取分數,輸出或儲存..... 查詢下一頁的連結,拼接地址,傳送請求,重新呼叫parse_comments()函式解析資料..
7.注意:
從執行結果可以看出 所有的評論是一樣的原因是:
在def parse_comments(self):函式中迴圈執行的是同一個json檔案中的資料,裡面只包含一條 樣本!
完整程式碼:
# -*- coding:utf-8 -*-
from urllib import request
import codecs
import re
import json
import time
from fake_useragent import UserAgent
agent = UserAgent()
class DBSpider(object):
def __init__(self):
with codecs.open('douban.html', 'r', encoding='utf-8') as f:
self.html = f.read()
def parse_list(self):
pattern = re.compile('<div class="hd.*?href="(.*?)"', re.S)
res = re.findall(pattern, self.html)
# for迴圈遍歷列表,取出每一個電影資訊
for link in res:
# 拼接完整的電影影評地址
url = link + 'reviews'
# 發起請求,拿回影評頁面
with codecs.open('detail.html', 'r', encoding='utf-8')as f:
self.html = f.read()
# 解析詳情頁的資料
self.parse_comments()
# 找下一頁
pattern = re.compile('<link rel="next" href="(.*?)"')
res = re.search(pattern, self.html)
if res:
# 拼接下一頁的url地址
next_href = 'https://movie.douban.com/top250?' + res.group(1)
# 發起請求,拿回下一頁資料
# 呼叫此函式,解析資料
else:
print('沒有下一頁')
# 解析影評頁面
def parse_comments(self):
pattern = re.compile('<div class="main review-item.*?id="(.*?)".*?v:reviewer.*?>(.*?)</a>.*?<span.*?class="(.*?)".*?title="(.*?)".*?<span.*?>(.*?)</span', re.S)
res = re.findall(pattern, self.html)
# for 迴圈遍歷資料
for ID, name, star, suggest, date in res:
# 根據url傳送請求,拿回完整的影評資訊
url = 'https://movie.douban.com/j/review/%s/full' % ID
# 迴圈執行一個json檔案中的資料,所以輸出的 評論 是一個評論
with codecs.open('test.json', 'r', encoding='utf-8')as f:
info = f.read()
com_dict = json.loads(info)
comment = com_dict.get('html')
# 處理資料
comment = re.sub(re.compile('<br>'), '\n', comment)
comment = re.sub(re.compile('<.*?>|\n| ', re.S), '', comment)
# 把影評分數分割出來
score = re.search(re.compile('\d+'), star).group()
print('作者:{}\n作者ID:{}\n分數:{}\n建議:{}\n釋出日期:{}\n評價內容:{}\n'.format(name, ID, score, suggest, date, comment))
# 找下一頁
pattern = re.compile('<link rel="next" href="(.*?)"')
res = re.search(pattern, self.html)
if res:
# 拼接下一頁url地址
next_href = url + res.group()
# 發起請求,拿回下一頁資料
# 呼叫此函式,解析資料
# self.parse_comments()
else:
print('沒有下一頁')
def start(self):
self.parse_list()
if __name__ == '__main__':
dbdy = DBSpider()
dbdy.start()
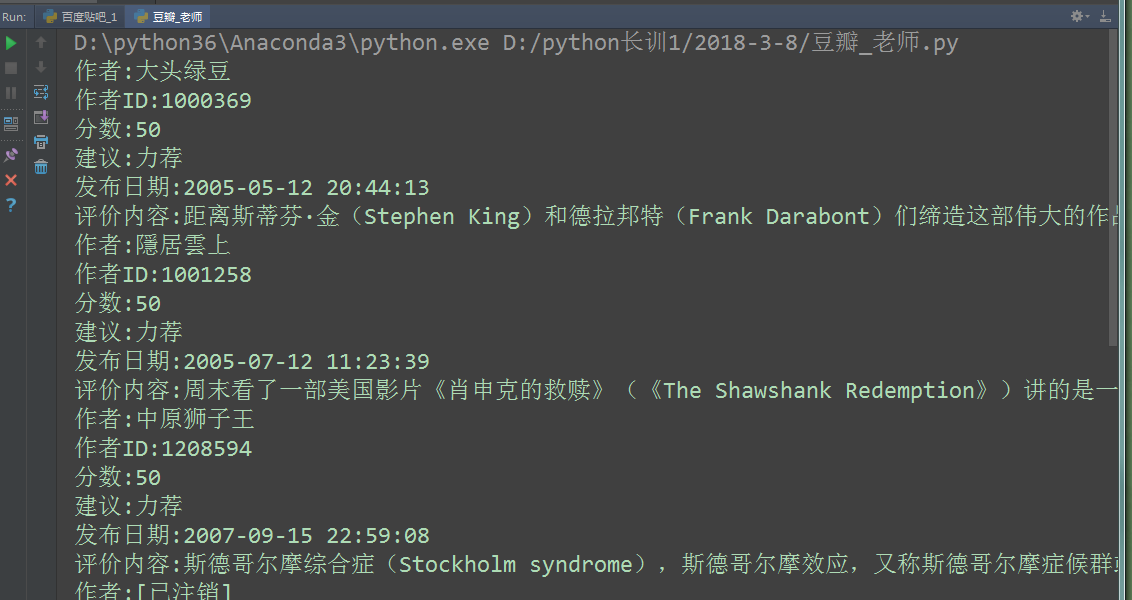
執行結果:
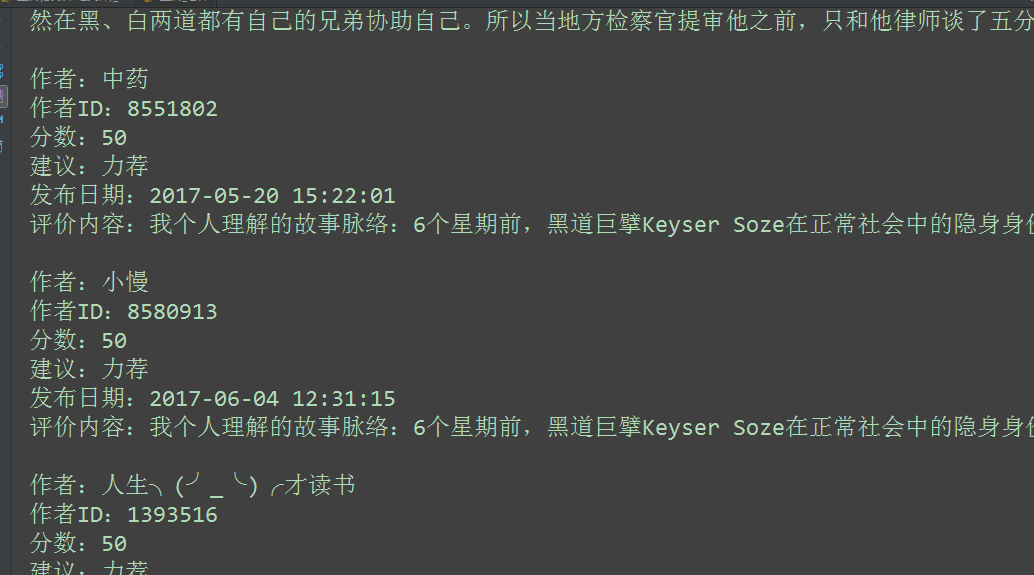
第二部分
網頁解析:
具體解析和解析本地檔案差不多,不做過多解釋
實現思路:
'''
1.在get_html 中根據url地址,獲取目標資料,判斷請求的是否為完整影評的json資料,如果是將返回的資料賦值給json屬性,如果不是就賦值html屬性
2.在parse_list函式中,根據正則解析當前頁的所有電影的連結,拼接完整的影評連結地址,傳送請求,解析影評資料, 找到下一頁的連結,傳送請求,重新呼叫parse_list函式解析下一頁資料....
3.在parse_comments()函式中,根據正則解析當前頁的所有影評資訊,for遍歷,找到每一個影評id,根據id拼接完整的影評地址,傳送請求,解析完整影評,處理資料,提取分數,輸出或儲存..... 查詢下一頁的連結,拼接地址,傳送請求,重新呼叫parse_comments()函式解析資料..
'''完整程式碼:
from urllib import request
import codecs
import re
import json
import time
class DBSpider(object):
def __init__(self):
# 讀取本地檔案,做資料的解析
# with codecs.open('douban.html','r',encoding='utf-8') as f:
# self.html = f.read()
self.html = ''
# 發請求的話,需要帶上登入之後的cookie
self.headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Cookie':'ll="128517"; bid=JWYJzKhS_Vc; __yadk_uid=t8sJyKbxnVnF3NFso9uRLV8WW0oJDKxH; _vwo_uuid_v2=D639114FFF67EC089E7D03E92504EBEC5|8ba743c5c00bd36a97c0fec4da764061; ps=y; dbcl2="175108542:665ypl9UG1Q"; ck=MI-6; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1520490928%2C%22https%3A%2F%2Fwww.douban.com%2Faccounts%2Flogin%3Fredir%3Dhttps%253A%252F%252Fmovie.douban.com%252Ftop250%253Fqq-pf-to%253Dpcqq.group%22%5D; _pk_ses.100001.4cf6=*; push_noty_num=0; push_doumail_num=0; _pk_id.100001.4cf6=b7a8892258d1a5dd.1517454912.4.1520493388.1520478251.',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
# 獲取html原始碼
def get_html(self,url):
# 發請請求
req = request.Request(url, headers=self.headers)
response = request.urlopen(req)
# 判斷是否為json資料,包含的是完整影評
if '/full' in url:
self.json = response.read().decode('utf-8')
else:
self.html = response.read().decode('utf-8')
time.sleep(2)
# 解析首頁列表
def parse_list(self):
pattern = re.compile('<div class="hd.*?href="(.*?)"',re.S)
res = re.findall(pattern,self.html)
# for迴圈遍歷列表,取出每一個電影資訊
for link in res:
# 拼接完整的電影影評地址
url = link + 'reviews'
# 發起請求,拿回影評頁面
self.get_html(url)
# 解析詳情
self.parse_comments(url)
# 讀取本地檔案,做資料解析
# with codecs.open('detail.html','r',encoding='utf-8') as f:
# # 詳情html
# self.html = f.read()
# # 解析詳情頁面的資料
# self.parse_comments(url)
# 找下一頁
pattern = re.compile('<link rel="next" href="(.*?)"')
res = re.search(pattern,self.html)
if res:
# 拼接下一頁的url地址
next_href= 'https://movie.douban.com/top250?'+res.group(1)
# 發起請求,拿回下一頁資料
self.get_html(next_href)
# 呼叫此函式,解析資料
self.parse_list()
else:
print('沒有下一頁')
# 解析影評頁面
def parse_comments(self,url):
pattern = re.compile('<div class="main review-item.*?id="(.*?)".*?v:reviewer.*?>(.*?)</a>.*?<span.*?class="(.*?)".*?title="(.*?)".*?<span.*?>(.*?)</span',re.S)
res = re.findall(pattern,self.html)
# for迴圈遍歷資料
for ID,name,star,suggest,date in res:
# 讀取本地資料,做資料解析
# with codecs.open('test.json','r',encoding='utf-8') as f:
# info = f.read()
# com_dict = json.loads(info)
# comment = com_dict.get('html')
# comment = re.sub(re.compile('<br>'),'\n',comment)
# 根據url傳送請求,拿回完整的影評資訊
url = 'https://movie.douban.com/j/review/%s/full' % ID
self.get_html(url)
com_dict = json.loads(self.json)
comment = com_dict.get('html')
# 處理資料
comment = re.sub(re.compile('<br>'),'\n',comment)
comment = re.sub(re.compile('<.*?>|\n| ',re.S),'',comment)
# 把影評分數匹配出來
sorce = re.search(re.compile('\d+'),star).group()
print('作者:{}\n作者ID:{}\n分數:{}\n建議:{}\n釋出日期:{}\n評價內容:{}'.format(name,ID,sorce,suggest,date,comment))
# 找下一頁
pattern = re.compile('<link rel="next" href="(.*?)"')
res = re.search(pattern,self.html)
if res:
# 拼接下一頁的url地址
next_href = url + res.group(1)
# 發起請求,拿回下一頁資料
self.get_html(next_href)
# 呼叫此函式,解析資料
self.parse_comments(url)
else:
print('沒有下一頁')
def start(self):
self.get_html('https://movie.douban.com/top250?qq-pf-to=pcqq.group')
self.parse_list()
if __name__ == '__main__':
db = DBSpider()
db.start()執行結果