
0005.hive的sql建立內部表語句
阿新 • • 發佈:2019-02-17
建表:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path] CREATE TABLE 建立一個指定名字的表。如果相同名字的表已經存在,則丟擲異常;使用者可以用 IF NOT EXIST 選項來忽略這個異常
EXTERNAL 關鍵字可以讓使用者建立一個外部表,在建表的同時指定一個指向實際資料的路徑(LOCATION)
LIKE 允許使用者複製現有的表結構,但是不復制資料
COMMENT可以為表與欄位增加描述 ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
使用者在建表的時候可以自定義 SerDe 或者使用自帶的 SerDe。如果沒有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,將會使用自帶的 SerDe。在建表的時候,使用者還需要為表指定列,使用者在指定表的列的同時也會指定自定義的 SerDe,Hive 通過 SerDe 確定表的具體的列的資料。 STORED AS SEQUENCEFILE | TEXTFILE | RCFILE | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname 如果檔案資料是純文字,可以使用 STORED AS TEXTFILE。如果資料需要壓縮,使用 STORED AS SEQUENCE 。 1.建立內部表
OK
Time taken: 0.079 seconds
hive> show tables;
OK
people
student
Time taken: 0.063 seconds, Fetched: 2 row(s)
hive>
2lisi
3wangwu
做資料的時候分隔符用Tab鍵進行分割,用空格不可以。 檢視hdfs上的資料通過瀏覽器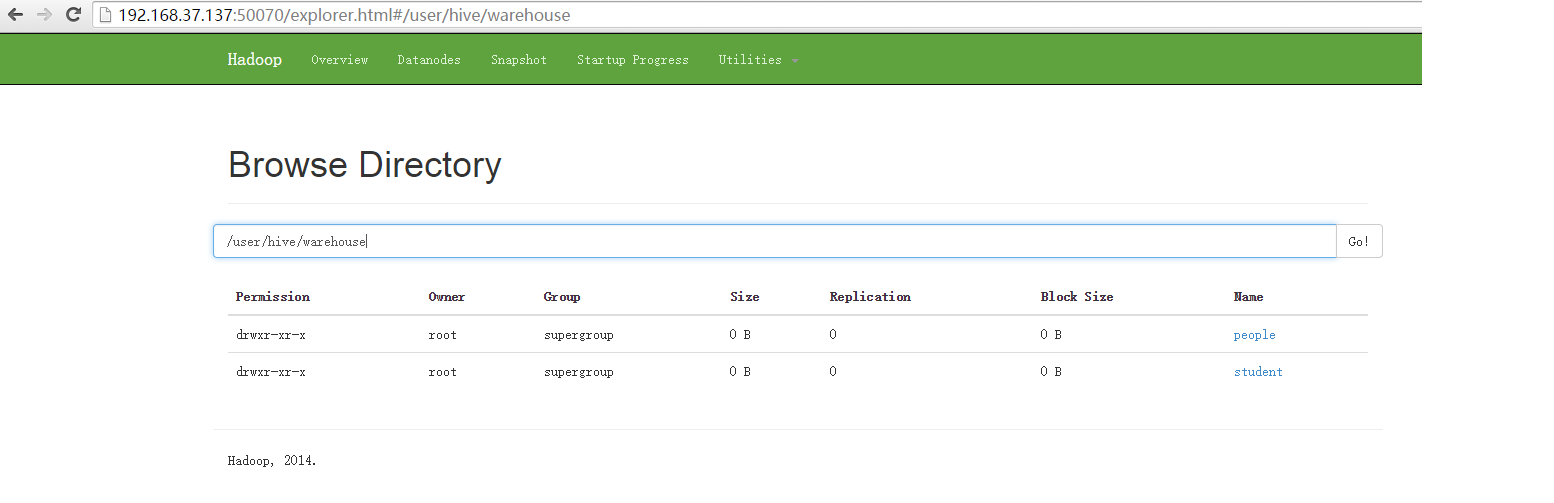
3.查詢載入的資料 hive> select * from student;
OK
1 zhangsan
2 lisi 3 wangwu 這個語句不會轉換為mapreduc 4.呼叫sum函式會轉換為mapreducer. hive> select sum(1) from student;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1431214819370_0001, Tracking URL = http://hadoop12:8088/proxy/application_1431214819370_0001/
Kill Command = /hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1431214819370_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2015-05-09 17:24:35,339 Stage-1 map = 0%, reduce = 0%
2015-05-09 17:25:08,401 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.76 sec
2015-05-09 17:25:28,906 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.49 sec
MapReduce Total cumulative CPU time: 2 seconds 490 msec
Ended Job = job_1431214819370_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.49 sec HDFS Read: 358 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 490 msec
OK
6
Time taken: 76.429 seconds, Fetched: 1 row(s)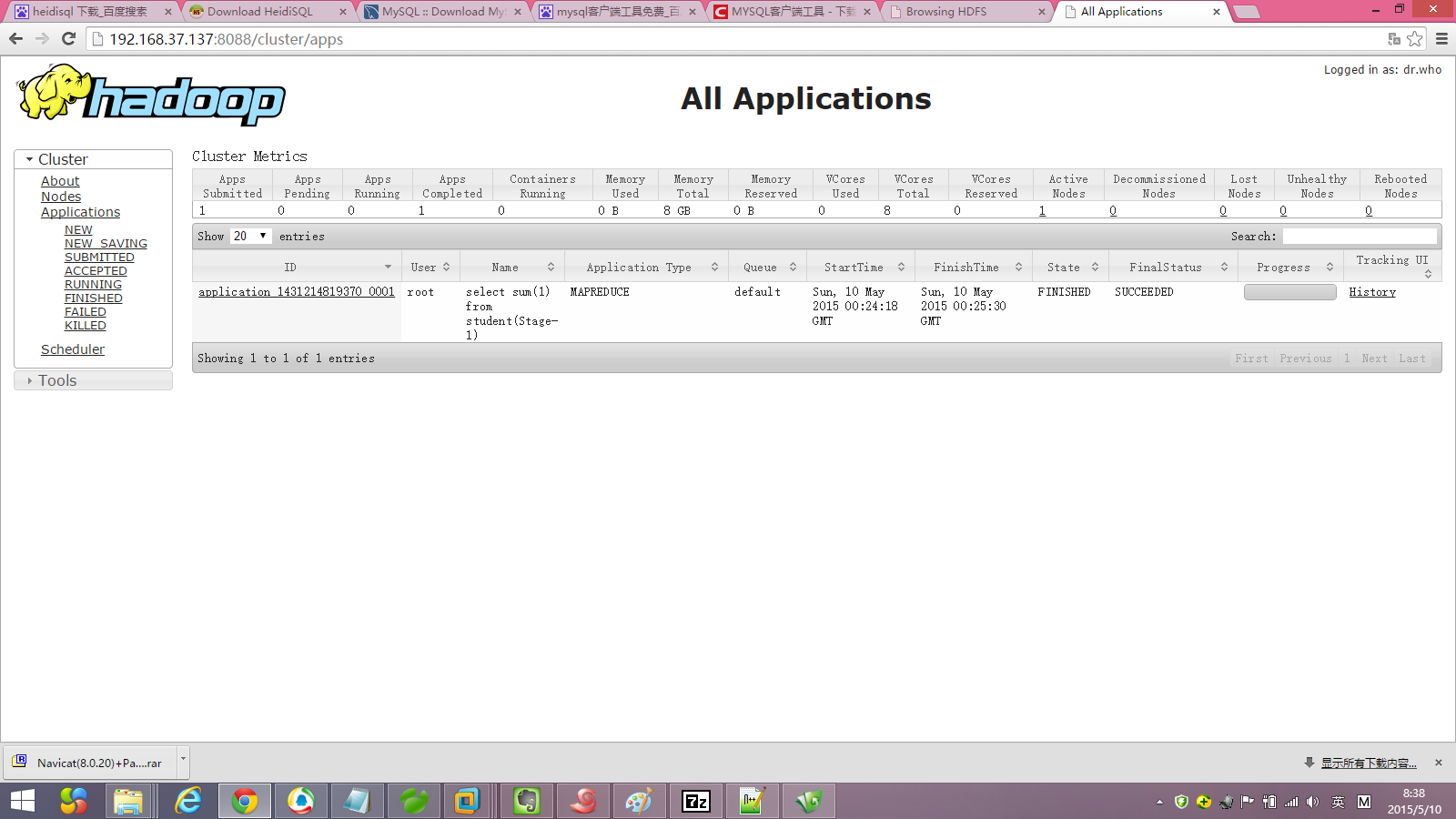
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path] CREATE TABLE 建立一個指定名字的表。如果相同名字的表已經存在,則丟擲異常;使用者可以用 IF NOT EXIST 選項來忽略這個異常
EXTERNAL 關鍵字可以讓使用者建立一個外部表,在建表的同時指定一個指向實際資料的路徑(LOCATION)
LIKE 允許使用者複製現有的表結構,但是不復制資料
COMMENT可以為表與欄位增加描述 ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
使用者在建表的時候可以自定義 SerDe 或者使用自帶的 SerDe。如果沒有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,將會使用自帶的 SerDe。在建表的時候,使用者還需要為表指定列,使用者在指定表的列的同時也會指定自定義的 SerDe,Hive 通過 SerDe 確定表的具體的列的資料。 STORED AS SEQUENCEFILE | TEXTFILE | RCFILE | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname 如果檔案資料是純文字,可以使用 STORED AS TEXTFILE。如果資料需要壓縮,使用 STORED AS SEQUENCE 。 1.建立內部表
OK
Time taken: 0.079 seconds
hive> show tables;
OK
people
student
Time taken: 0.063 seconds, Fetched: 2 row(s)
hive>
2lisi
3wangwu
做資料的時候分隔符用Tab鍵進行分割,用空格不可以。 檢視hdfs上的資料通過瀏覽器
3.查詢載入的資料 hive> select * from student;
OK
1 zhangsan
2 lisi 3 wangwu 這個語句不會轉換為mapreduc 4.呼叫sum函式會轉換為mapreducer. hive> select sum(1) from student;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1431214819370_0001, Tracking URL = http://hadoop12:8088/proxy/application_1431214819370_0001/
Kill Command = /hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1431214819370_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2015-05-09 17:24:35,339 Stage-1 map = 0%, reduce = 0%
2015-05-09 17:25:08,401 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.76 sec
2015-05-09 17:25:28,906 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.49 sec
MapReduce Total cumulative CPU time: 2 seconds 490 msec
Ended Job = job_1431214819370_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.49 sec HDFS Read: 358 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 490 msec
OK
6
Time taken: 76.429 seconds, Fetched: 1 row(s)