
實施微服務架構的關鍵技術
作者簡介:孫玄,58集團技術委員會主席,本文來自於作者在CCTC 2017上的演講整理。
大家都在提微服務架構,微服務架構到底是什麼?它有哪些特點和設計模式?我們在打造微服務架構過程中,這些設計模式在實戰當中如何應用?資料的一致性應該如何保證?今天我將針對上述疑問分享一下我的思考。
微服務架構特點
什麼是微服務架構?看下圖的這段英文,這是Martin Fowler 在2014年提出來的,微服務架構是一種架構模式,既然是架構模式,那麼,它就必然需要滿足一些特點。他提到,微服務架構是一系列小的微服務構成的組合,那麼,什麼是“小的微服務”?可能每個人的理解都不一樣,大家都應該都知道SOA架構,SOA架構的粒度是比較粗的,到底我們應該以什麼樣的粒度拆分微服務?我認為,微服務架構本質上一個業務架構,那麼對業務瞭解的越深刻,你的微服務拆分就越合理。

比如我們做二手交易平臺(轉轉),該平臺包括使用者體系、商品體系、交易體系以及搜尋推薦體系。因為各個體系比較獨立,那麼我們就可以按照各個業務模組來拆分微服務。當然,這樣做還不夠,因為你的商品裡面還有很多功能,但是大的思路是按照具體商品內部的邏輯來進一步拆分。
第二,圍繞具體業務建模。一切脫離業務場景談微服務架構都是耍流氓。
方法有二:首先將某一領域的模型作為獨立的業務單元:比如二手交易中的商品、訂單、使用者等;其次將業務的行為作為獨立的業務單元:比如傳送郵件、單點登入驗證、push服務。
第三,整個微服務都可以獨立地部署,因為每一個維服務Process都是獨立的,所以按照每個模組進行獨立的部署也是很容易理解的。
第四,去中心化管理。打造去中心化管理意思就是微服務的每個模組和開發語言、執行平臺沒有關係,開發語言可以是C++,可以是go,也可以是世界上最好的語言,執行的平臺是Linux,Unix、Windows等都可以。
最後一點就是輕量級通訊,這點很容易理解,通訊和模組語言、平臺沒有關係。儘可能選用輕量級的通訊來做這個事情,這樣實施跨平臺、跨語言的時候就很容易。
講完這些特點,我們可以看一看一個標準DEMO級的微服務架構到底是由哪些元素組成的?如下圖,主要包括閘道器、微服務、資料儲存、註冊中心、配置中心。
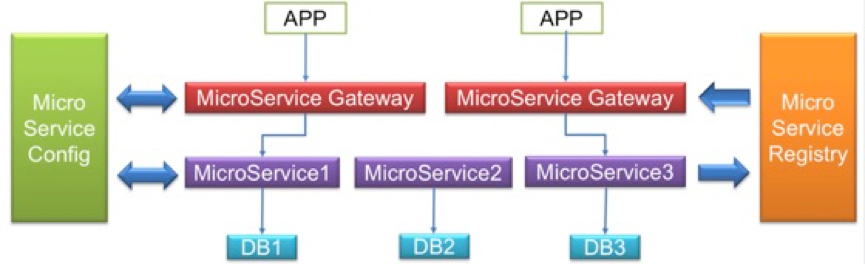
既然是DEMO級的,和實際情況下相比肯定有所差別。那麼,實際案例中,我們到底應該如何做這件事情?這個例子也是最近我在做的二手交易平臺——轉轉。這裡和DEMO有些不一樣的地方。前面的第一層還是閘道器,下面有微服務的聚合層,作用是做各種業務邏輯的處理;聚合層下面是我們的資料原子層,主要做資料訪問代理,只不過根據業務的不同垂直分開了。可以看到,閘道器、資料層,註冊中心、配置中心都有,只不過在業務處理部分分成兩層:一層是原子層,也就是整個資料訪問的代理層,提供了使用者的介面;另外一層就是上層的業務聚合層。
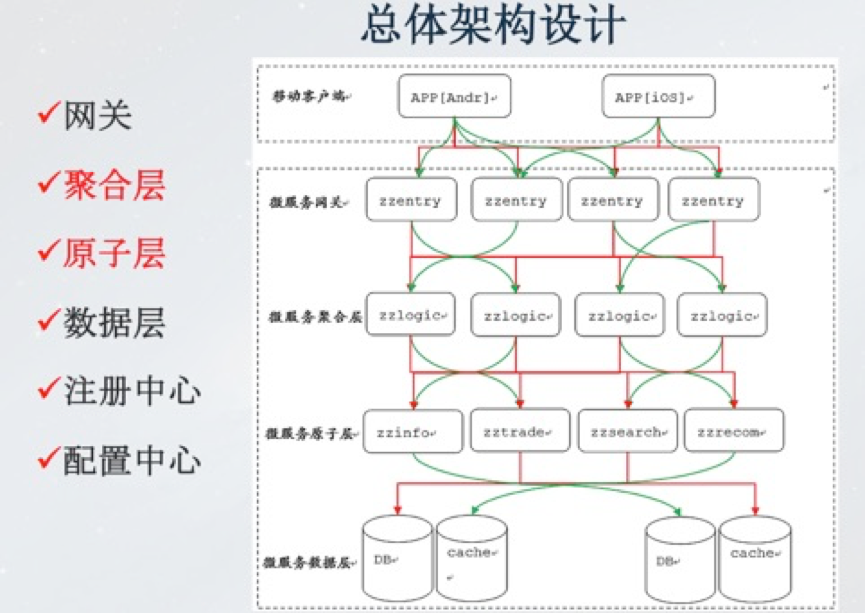
架構設計模式及實踐案例
上面我大概講了下微服務的一些特點以及DEMO級的微服務包括哪些部分以及實際案例中我們的設架構設計模式。那麼,我們為什麼要採用這種模式去做?除了這種架構模式之外還有哪些其它的架構模式?這裡,模式還是非常多的,我會重點講這幾點:鏈式設計模式、聚合器設計模式和非同步共享模式。
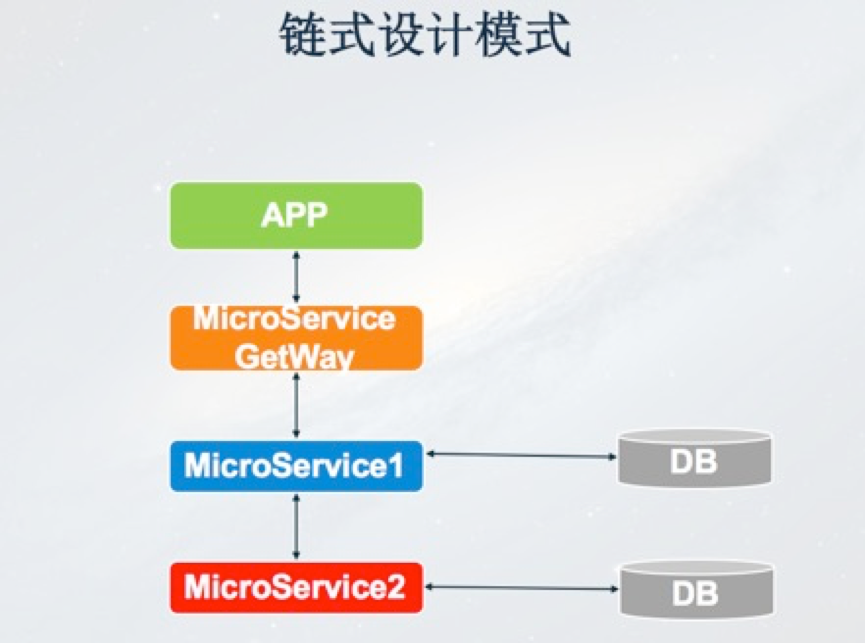
首先我們來說下鏈式設計模式,在這種模式下,APP前端請求首先要經過閘道器層,接下來連續呼叫兩個微服務,調了微服務1之後還要調微服務2。為什麼叫做鏈式呢?因為在呼叫過來以後先到微服務1,然後再同步地呼叫微服務2,微服務2會做一些處理,處理以後微服務2才會反饋給微服務1,微服務1再反饋給Gateway,最後反饋到APP。在實際業務場景中,涉及到交易和訂單的業務場景都會用到這種模式。
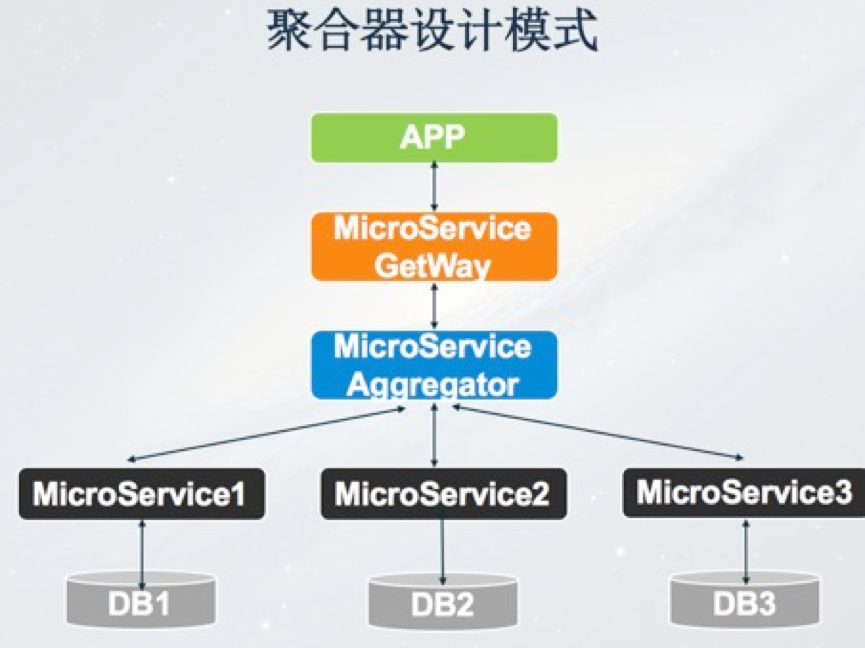
接下來是聚合器設計模式,APP前端一個呼叫請求經過Gateway,到達聚合層,需要呼叫三個微服務,聚合層將三個微服務的返回結果做一些聚合處理,比如可以進行一些排序或者去重,聚合之後再反饋到Gateway和APP前端,這是一個典型的聚合器設計模式。
第三種模式是資料共享模式,這種模式相對比較簡單,比如APP經過微服務閘道器,接下來呼叫微服務1和微服務2,理想情況下微服務1和微服務2都有自己獨立的DB,但是有些情況下由於微服務1和微服務2的請求量和儲存量較小,從資源利用率的角度來講,這兩個微服務的DB是共享的,因此這種就是資料的共享模式。
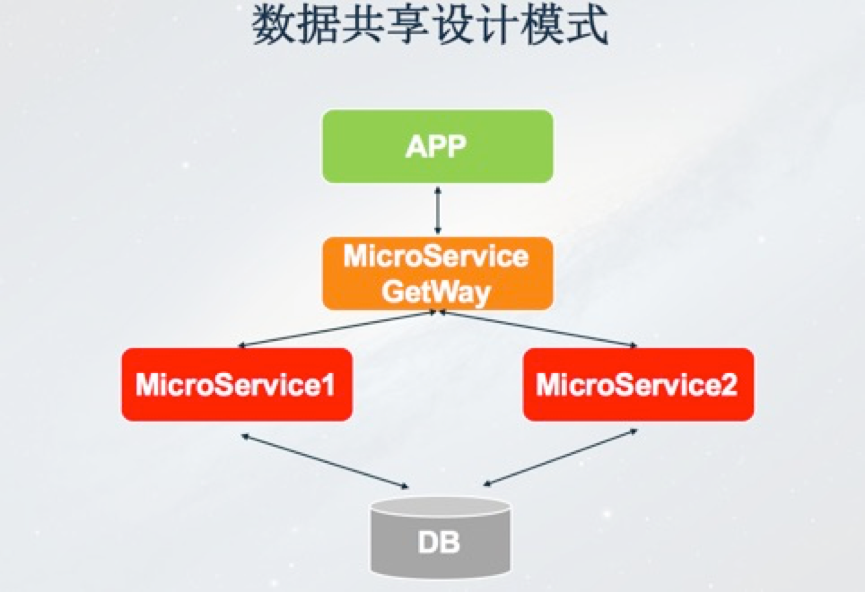
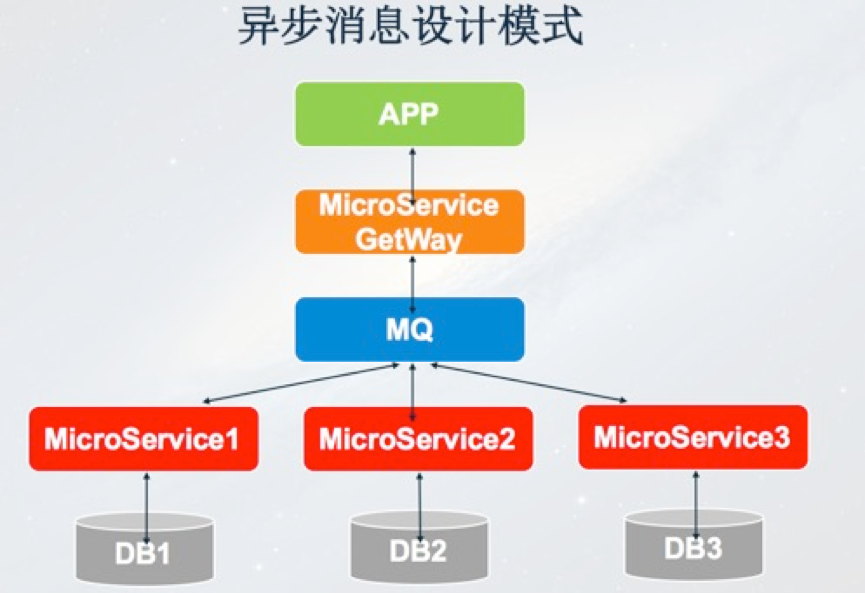
最後一種是非同步訊息設計模式,不管是鏈式設計、聚合器模式還是共享資料模式,架構模式都是同步模式。也就是說我的一個請求發出去必須等到每個環節都處理完才會給客戶端。如果請求不需要關注處理結果,這時候可以非同步來實施。APP更新請求經過微服務閘道器,持久化到MQ,寫入MQ成功後馬上Response給APP客戶端,之後微服務根據需要從MQ裡面訂閱更新訊息進行非同步處理,我們為了提高吞吐量也會採用這種模式。
我從百度到轉轉這幾年經歷了很多業務場景,使用的無非就是聚合器、非同步和資料共享的資料模式,特別是前面兩個用得特別多,下面我們來看一些例子。
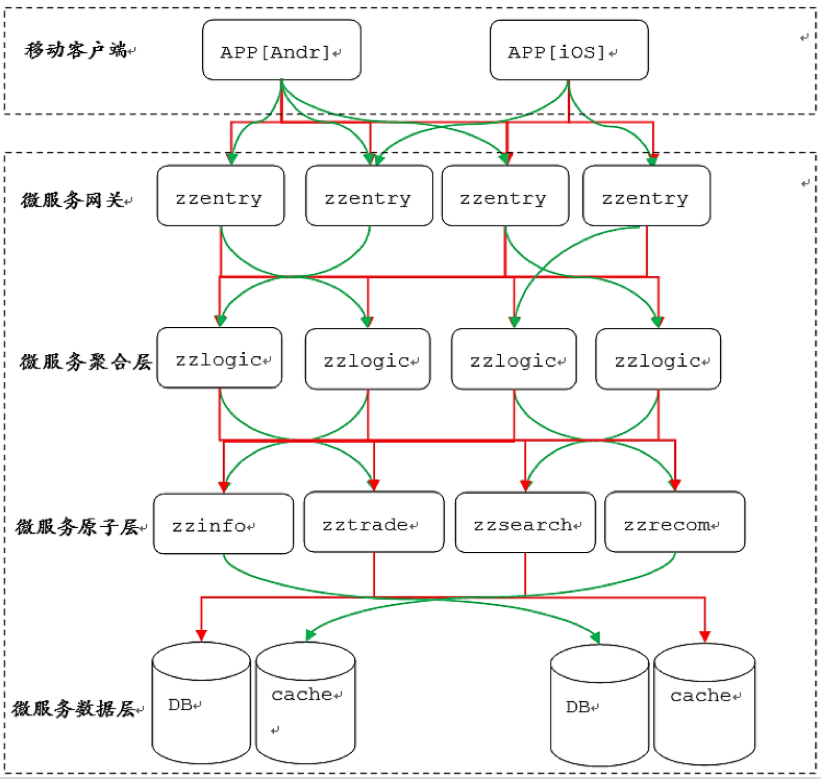
接下來我們看個例子,這是我們在2015年做的一個二手交易平臺(轉轉),這個二手交易平臺包括商品、分類搜尋、關鍵詞搜尋、商品推薦等功能。一個使用者請求過來,先經過閘道器,閘道器下面就是我們的聚合層,聚合層再去呼叫商品、交易、推薦以及搜尋相關的,最終在聚合層把各個微服務原子層的結果彙總起來Response給到客戶端。具體如下圖所示:
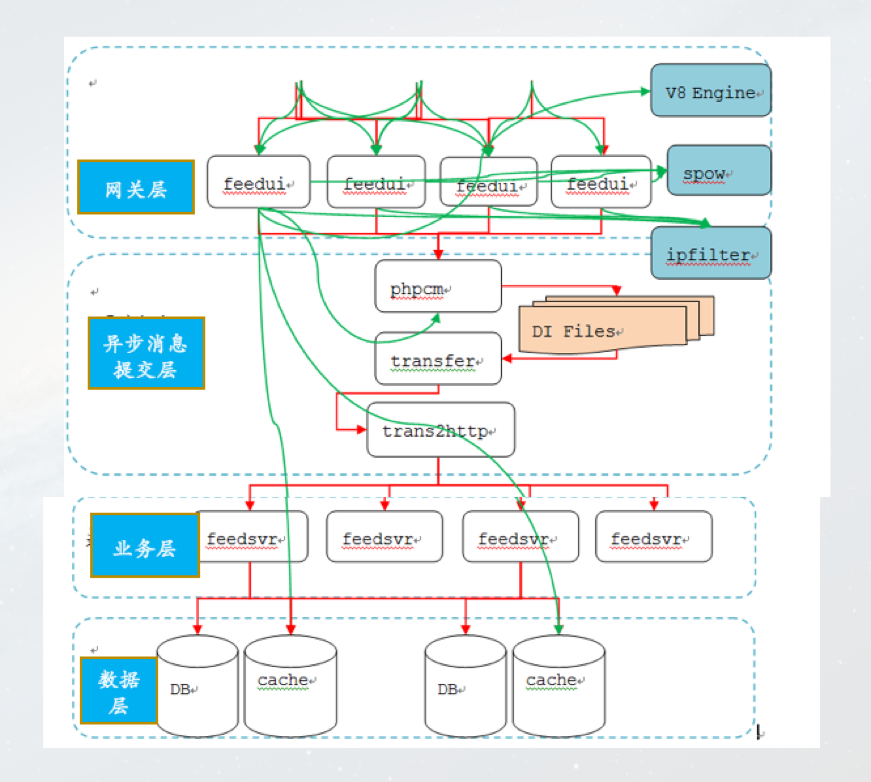
非同步訊息模式的這個案例比較早了,當時我們做了Feed 流,類似現在的微信朋友圈,這是我在百度做的事情。當時,我們採用的架構模式是非同步架構模式。前面是我們的APP,經過了閘道器,到達非同步提交層,可以認為是持久化功能的MQ。使用者請求經過閘道器到訊息非同步提交層後就返回了,業務處理部分從MQ裡面讀取資料再進行非同步處理。這個時候吞吐量會增加,但是會帶來一定的困惑。比如這個時候我發了一條Feed,使用者再一查就直接到資料庫裡面查,可能非同步提交訊息佇列有延遲,查不到,使用者就困惑了,這個問題怎麼解決?我們就想能不能在前端幫我們做一些事情?比如提交了MQ返回Response 200以後,前段配合插入這條Feed。使用者再次重新整理時候我相信已經是好幾秒以後的事情了,即使有延遲,這個訊息早就被你的業務處理完了。當然,我們這裡是有特定場景的,社群時候可以這樣去做,但是涉及到和金融相關的場景肯定不會這麼去做。
資料一致性實踐
微服務模組比較分散、資料也比較分散,整個系統複雜性非常高,如何進行資料一致性實踐?在一個單體模組裡面可以做Local Transaction,但是在微服務體系裡面就不奏效。雖然難解決,但是不能不解決,不解決的話微服務架構就很難實施。我們知道微服務中做強一致性性的事情是非常難的,今天分享的更多的是解決最終一致性。因為在微服務下基於不同的資料庫,Local Transaction是不可用的。大家在在分散式事務裡面一定聽說過兩階段提交和三階段提交,這種場景其實在微服務架構裡面也行不通,原因是因為它本質上是同步的模式,同步的模式之下做資料一致性吞吐量降低的非常多。
我們的業務場景無非是兩種:第一種是非同步呼叫,就是一個請求過來就寫到訊息佇列裡面就行,這種模式相對簡單。今天主要講下同步呼叫的場景之下怎麼打造資料的最終一致性。既然是同步呼叫場景,並且不能降低業務系統的吞吐量,那麼應該怎麼做呢?建立一個非同步的分散式事務,業務呼叫失敗後,通過非同步方式來補償業務。我們的想法是能不能在整個業務邏輯層實現分散式事務語義策略?如何實現,無非有兩種,第一是在調正常請求的時候要記錄業務呼叫鏈(呼叫正常介面的完整引數),第二是異常時沿呼叫鏈反向補償。
基於這個思路,我們架構設計上的關鍵點有三,第一是基於補償機制,第二是記錄呼叫鏈,第三是提供冪等補償介面。架構層面,看下圖,右邊是聚合器架構設計模式,左邊是非同步補償服務。
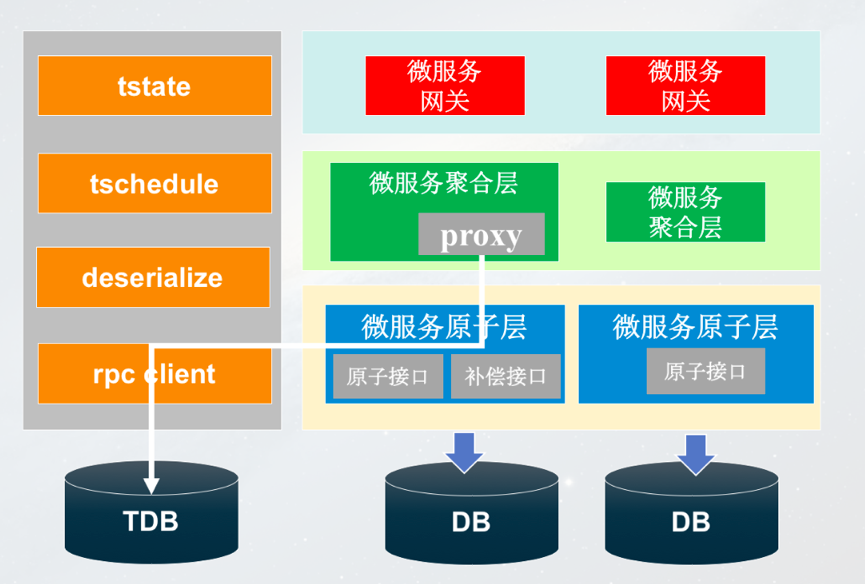
首先需要在聚合層引入一個Proxy。首先基於方法,在方法名加註解標註補償方法名,比如:- @Compensable(cancelMethod=“cancelRecord”)
另外,聚合層在呼叫原子層之前,通過代理記錄當前呼叫請求引數。如果業務正常,呼叫結束後,當前方法的呼叫記錄存檔或刪除,如果業務異常,查詢呼叫鏈回滾。
原子層我們做了哪些事情呢?主要是兩方面,第一是提供正常的原子介面,其次是提供補償冪等介面。
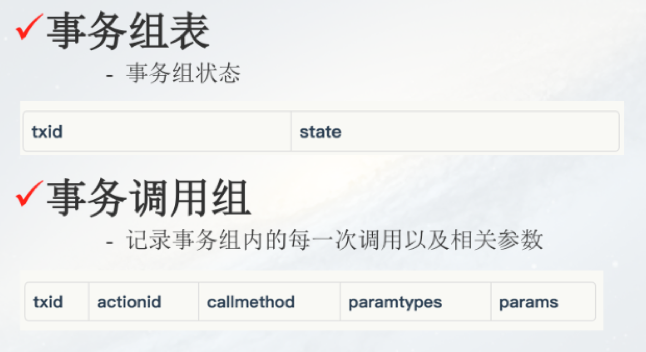
分散式事務關鍵是兩個表(如上圖),第一是事務組表,假設A->B->C三個請求是一個事務,首先針對ABC生成一個事務的ID,寫在這個表裡面,並且會記錄這個事務的狀態,預設的情況下正常的,執行失敗以後我們再把狀態由1(正常)變成2(異常);第二個表是事務呼叫組表,主要記錄事務組內的每一次呼叫以及相關引數,所以呼叫原子層之前需要記錄一下請求引數。如果失敗的話我們需要把這個事務的狀態由1變成2;第三,一旦狀態從1變成2就執行補償服務。這是我們的補償邏輯,就是不斷地掃描這個事務所處的表,比如一秒鐘掃一次事務組表,看一看這個表裡面有沒有狀態為2的,需要執行補償的服務。這個思路對業務的侵入比較小。
具體看下我們實際的例子,比如二手交易平臺裡面建立訂單事務組的正常流程,從鎖庫存到減紅包再到建立訂單,建立事務組完畢之後開始呼叫業務,首先Proxy記錄鎖庫存呼叫的引數,之後開始鎖庫存服務呼叫,成功後之後又開始減紅包和建立訂單過程,如果都成功了直接返回。
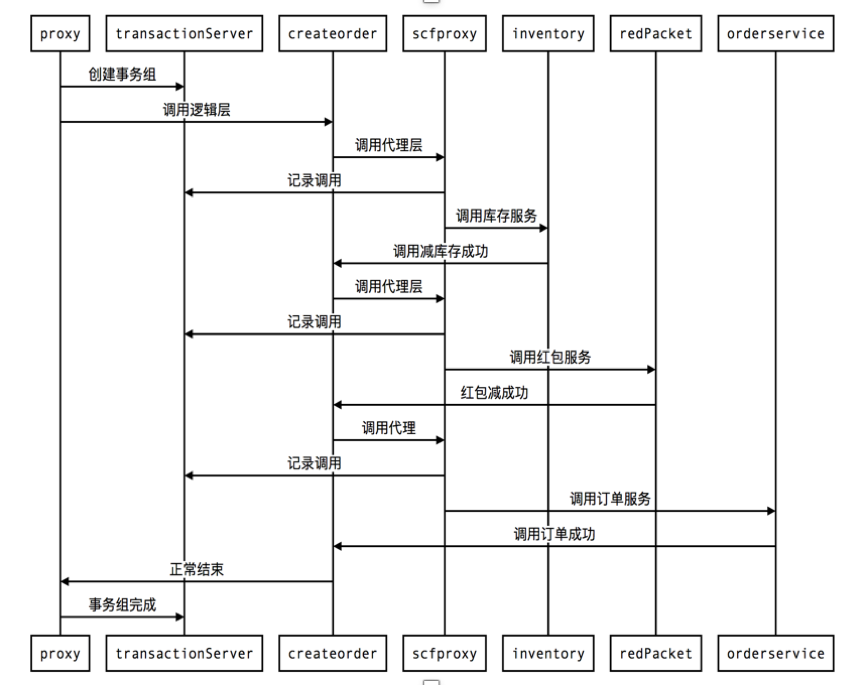
再看一下異常的流程,前面幾步都是一樣的,只是在調紅包服務、Proxy建立紅包的時候如果失敗了就會丟擲異常,業務正常返回,聚合層Proxy需要把事務組的狀態由1改成2,這個時候由左邊的補償服務非同步地補償呼叫。