
Hbase和Hive以及傳統資料庫的區別
Hbase和Hive
HBase 是一種類似於資料庫的儲存層,也就是說 HBase 適用於結構化的儲存。並且 HBase 是一種列式的分散式資料庫。
HBase 底層依舊依賴 HDFS 來作為其物理儲存,這點類似於 Hive。
1.實時性:Hive 適合用來對一段時間內的資料進行分析查詢,例如,用來計算趨勢或者網站的日誌。Hive 不應該用來進行
實時的查詢(Hive 的設計目的,也不是支援實時的查詢)。因為它需要很長時間才可以返回結果;HBase 則非常
適合用來進行大資料的實時查詢,例如 Facebook 用 HBase 進行訊息和實時的分析。
2.部署:Hive 一般只要有 Hadoop 便可以工作。而 HBase 則還需要 Zookeeper 的幫助(Zookeeper,是一個用來進行
分散式協 調的服務,這些服務包括配置服務,維護元資訊和名稱空間服務)
3.SQL查詢:HBase 本身只提供了 Java 的 API 介面,並不直接支援 SQL 的語句查詢,而 Hive 則可以直接使用 HQL
(一種類SQL 語言)。如果想要在 HBase 上使用 SQL,則需要聯合使用 Apache Phonenix,或者聯合使用
Hive 和HBase。但是和上面提到的一樣,如果整合使用 Hive 查詢 HBase 的資料,則無法繞過 MapReduce,
那麼實時性還是有一定的損失。Phoenix 加 HBase 的組合則不經過 MapReduce 的框架,因此當使用 Phoneix
加 HBase 的組成,實時性上會優於 Hive 加 HBase 的組合。
4.儲存層:預設情況下 Hive 和 HBase 的儲存層都是 HDFS。但是 HBase 在一些特殊的情況下也可以直接使用本機
的檔案系統。例如 Ambari 中的 AMS 服務直接在本地檔案系統上執行 HBase。
Hbase與傳統資料庫
首先讓瞭解下什麼是 ACID。ACID 是指資料庫事務正確執行的四個基本要素的縮寫,其包含:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)以及永續性(Durability)。對於一個支援事務(Transaction)的資料庫系統,必需要具有這四種特性,否則在事務過程(Transaction Processing)當中無法保證資料的正確性,交易過程極可能達不到交易方的要求。下面,我們就簡單的介紹下這 4 個特性的含義。
-
原子性(Atomicity)是指一個事務要麼全部執行,要麼全部不執行。換句話說,一個事務不可能只執行了一半就停止了。比如一個事情分為兩步完成才可以完成,那麼這兩步必須同時完成,要麼一步也不執行,絕不會停留在某一箇中間狀態。如果事物執行過程中,發生錯誤,系統會將事物的狀態回滾到最開始的狀態。
-
一致性(Consistency)是指事務的執行並不改變資料庫中資料的一致性。也就是說,無論併發事務有多少個,但是必須保證資料從一個一致性的狀態轉換到另一個一致性的狀態。例如有 a、b 兩個賬戶,分別都是 10。當 a 增加 5 時,b 也會隨著改變,總值 20 是不會改變的。
-
隔離性(Isolation)是指兩個以上的事務不會出現交錯執行的狀態。因為這樣可能會導致資料不一致。如果有多個事務,執行在相同的時間內,執行相同的功能,事務的隔離性將確保每一事務在系統中認為只有該事務在使用系統。這種屬性有時稱為序列化,為了防止事務操作間的混淆,必須序列化或序列化請求,使得在同一時間僅有一個請求用於同一資料。
-
永續性(Durability)指事務執行成功以後,該事務對資料庫所作的更改便是持久的儲存在資料庫之中,不會無緣無故的回滾。
在具體的介紹 HBase 之前,我們先簡單對比下 HBase 與傳統關係資料庫的(RDBMS,全稱為 Relational Database
Management System)區別。如表 1 所示。

理解了上面的表格之後,我們在看看資料是如何在 HBase 以及 RDBMS 中排布的。
首先,資料在 RDBMS 的排布大致如表 2。

資料在 HBase 中的排佈會是什麼樣子呢?如表 3 所示(這只是邏輯上的排布)

我們可以看出,在 HBase 中首先會有 Column Family 的概念,簡稱為 CF。CF 一般用於將相關的列(Column)
組合起來。在物理上 HBase 其實是按 CF 儲存的,只是按照 Row-key 將相關 CF 中的列關聯起來。物理上的
資料排布大致可以如表 4 所示。

HBase 是按照 CF 來儲存資料的。在表 3 中,我們看到了兩個 CF,分別是 info 和 pwd。info 儲存著姓名
相關列的資料,而 pwd 則是密碼相關的資料。上表便是 info 這個 CF 儲存在 Hbase 中的資料排布。Pwd 的資料排布
是類似的。上表中的 fn 和 ln 稱之為 Column-key 或者 Qulifimer。在 Hbase 中,Row-key 加上 CF 加上 Qulifier 再加上
一個時間戳才可以定位到一個單元格資料(Hbase 中每個單元格預設有 3 個時間戳的版本資料)。
其實不管是 CF 還是 Qulifier 都是客戶定義出來的。也就是說在 HBase 中建立表格時,就需要指定表格的 CF、
Row-key 以及 Qulifier。
下圖理解 HBase 中邏輯上的資料排布與物理上的資料排布之間的關係:
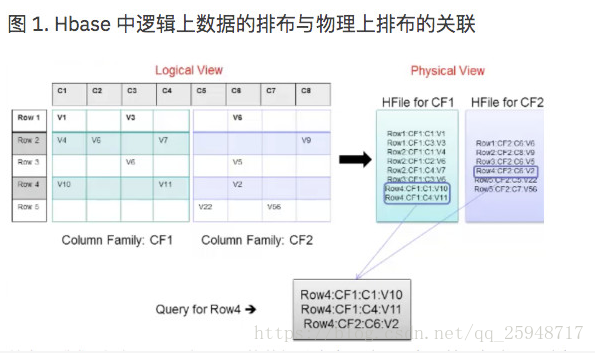
從上圖我們看到 Row1 到 Row5 的資料分佈在兩個 CF 中,並且每個 CF 對應一個 HFile。並且邏輯上每一行中的
一個單元格資料,對應於 HFile 中的一行,然後當用戶按照 Row-key 查詢資料的時候,HBase 會遍歷兩個 HFile,
通過相同的 Row-Key 標識,將相關的單元格組織成行返回,這樣便有了邏輯上的行資料。到此我們大致瞭解 HBase
中的資料排布格式,以及與 RDBMS 的一些區別。
對於 RDBMS 來說,一般都是以 SQL 作為為主要的訪問方式。而 HBase 是一種"NoSQL"資料庫。"NoSQL"是一個通用詞
表示該資料庫並不是 RDBMS 。
HBase 則為大型分散式 NoSql 資料庫。從技術上來說,Hbase 更像是"資料儲存"而非"資料庫"(HBase 和 HDFS 都屬於大資料的儲存層)。因此,HBase 缺少很多 RDBMS 特性,如列型別,二級索引,觸發器和高階查詢語言等。然而, HBase 也具有許多其他特徵同時支援線性化和模組化擴充。最明顯的方式,我們可以通過增加 Region Server 的數量擴充套件 HBase。並且 HBase 可以放在普通的伺服器中,例如將叢集從 5 個擴充到 10 個 Region Server 時,儲存空間和處理容量都可以同時翻倍。當然 RDBMS 也能很好的擴充,但僅對一個點,尤其是對一個單獨資料庫伺服器而言,為了更好的效能,往往需要特殊的硬體和儲存裝置(往往價格也非常昂貴)。