
Hive原理及查詢優化
通常來說,Hive只支援資料查詢和載入,但後面的版本也支援了插入,更新和刪除以及流式api。Hive具有目前Hadoop上最豐富最全的SQL語法,也擁有最慢最穩定的執行。是目前Hadoop上幾乎標準的ETL和資料倉庫工具。
Hive這個特點與其它AdHoc查詢工具如Impala,Spark SQL或者Presto有著應用場景的區別,也就是雖然都是即席查詢工具,前者適用與穩定作業執行,排程以及ETL,或者更傾向於交戶式。一個典型的場景是分析師使用Impala去探測資料,驗證想法,並把資料產品部署在Hive上執行。
在我們講Hive原理和查詢優化前,讓我們先回顧一下Hadoop基本原理。
Hadoop是一個分散式系統,有HDFS和Yarn。HDFS用於執行儲存,Yarn用於資源排程和計算。MapReduce是跑在Yarn上的一種計算作業,此外還有Spark等。
關於Hadoop介紹,矽谷的太閣實驗室錄製了一個視訊。 http://v.youku.com/v_show/id_XMTUxOTA5MjA1Mg==.html 也是我主講的。
Hive通常意義上來說,是把一個SQL轉化成一個分散式作業,如MapReduce,Spark或者Tez。無論Hive的底層執行框架是MapReduce、Spark還是Tez,其原理基本都類似。
而目前,由於MapReduce穩定,容錯性好,大量資料情況下使用磁碟,能處理的資料量大,所以目前Hive的主流執行框架是MapReduce,但效能相比Spark和Tez也就較低,等下講到Group By和JOIN原理時會解釋這方面的原因。
目前的Hive除了支援在MapReduce上執行,還支援在Spark和Tez 上執行。我們以MapReduce為例來說明的Hive的原理。先回顧一下 MapReduce 原理。
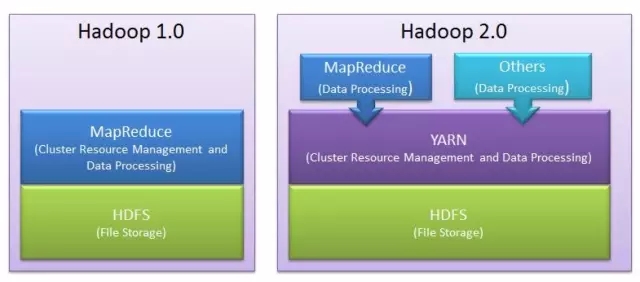
兩個Mapper各自輸入一塊資料,由鍵值對構成,對它進行加工(加上了個字元n),然後按加工後的資料的鍵進行分組,相同的鍵到相同的機器。這樣的話,第一臺機器分到了鍵nk1和nk3,第二臺機器分到了鍵nk2。
接下來再在這些Reducers上執行聚合操作(這裡執行的是是count),輸出就是nk1出現了2次,nk3出現了1次,nk2出現了3次。從全域性上來看,MapReduce就是一個分散式的GroupBy的過程。
從上圖可以看到,Global Shuffle左邊,兩臺機器執行的是Map。Global Shuffle右邊,兩臺機器執行的是Reduce。所以Hive,實際上就是一個編譯器,一個翻譯機。把SQL翻譯成MapReduce之類的作業。
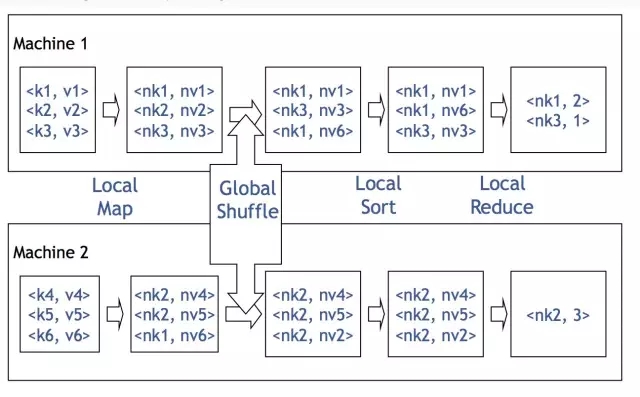
>>>>Hive架構
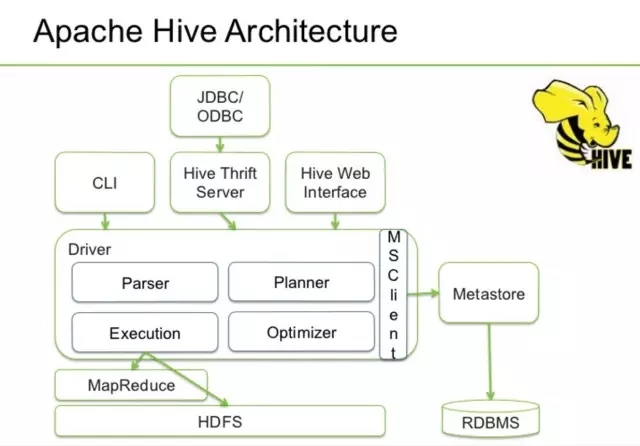
下面這個舊一點的圖片來自Facebook
從架構圖上可以很清楚地看出Hive和Hadoop(MapReduce,HDFS)的關係。
Hive是最上層,即客戶端層或者作業提交層。
MapReduce/Yarn是中間層,也就是計算層。
HDFS是底層,也就是儲存層。
從Facebook的圖上可以看出,Hive主要有QL,MetaStore和Serde三大核心元件構成。QL就是編譯器,也是Hive中最核心的部分。Serde就是Serializer和Deserializer的縮寫,用於序列化和反序列化資料,即讀寫資料。MetaStore對外暴露Thrift API,用於元資料的修改。比如表的增刪改查,分割槽的增刪改查,表的屬性的修改,分割槽的屬性的修改等。等下我會簡單介紹一下核心,QL。
>>>>Hive的資料模型
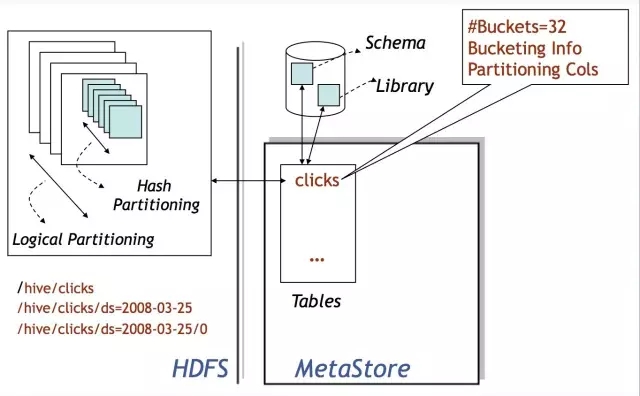
Hive的資料儲存在HDFS上,基本儲存單位是表或者分割槽,Hive內部把表或者分割槽稱作SD,即Storage Descriptor。一個SD通常是一個HDFS路徑,或者其它檔案系統路徑。SD的元資料資訊儲存在Hive MetaStore中,如檔案路徑,檔案格式,列,資料型別,分隔符。Hive預設的分格符有三種,分別是^A、^B和^C,即ASCii碼的1、2和3,分別用於分隔列,分隔列中的陣列元素,和元素Key-Value對中的Key和Value。
還記得大明湖畔暴露Thrift API的MetaStore麼?嗯,是她,就是它!所有的資料能不能認得出來全靠它!
Hive的核心是Driver,Driver的核心是SemanticAnalyzer。 Hive實際上是一個SQL到Hadoop作業的編譯器。 Hadoop上最流行的作業就是MapReduce,當然還有其它,比如Tez和Spark。Hive目前支援MapReduce, Tez, Spark三種作業,其原理和剛才回顧的MapReduce過程類似,只是在執行優化上有區別。
Hive作業的執行過程實際上是SQL翻譯成作業的過程?那麼,它是怎麼翻譯的?
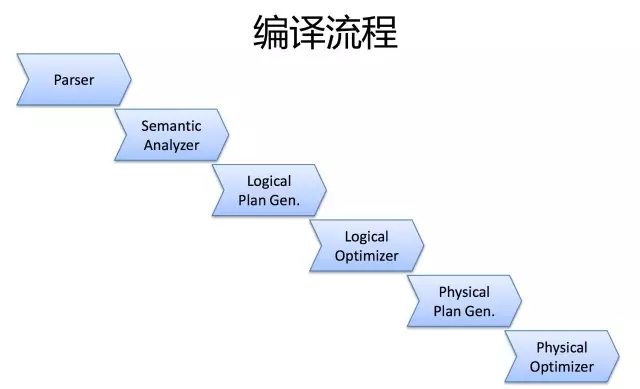
一條SQL,進入的Hive。經過上述的過程,其實也是一個比較典型的編譯過程變成了一個作業。
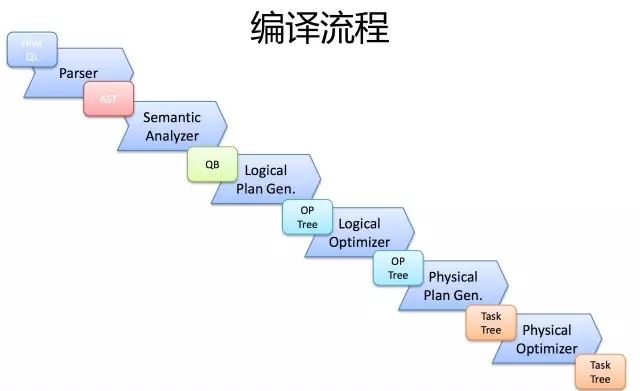
首先,Driver會輸入一個字串SQL,然後經過Parser變成AST,這個變成AST的過程是通過Antlr來完成的,也就是Anltr根據語法檔案來將SQL變成AST。
AST進入SemanticAnalyzer(核心)變成QB,也就是所謂的QueryBlock。一個最簡的查詢塊,通常來講,一個From子句會生成一個QB。生成QB是一個遞迴過程,生成的 QB經過GenLogicalPlan過程,變成了一個Operator圖,也是一個有向無環圖。
OP DAG經過邏輯優化器,對這個圖上的邊或者結點進行調整,順序修訂,變成了一個優化後的有向無環圖。這些優化過程可能包括謂詞下推(Predicate Push Down),分割槽剪裁(Partition Prunner),關聯排序(Join Reorder)等等
經過了邏輯優化,這個有向無環圖還要能夠執行。所以有了生成物理執行計劃的過程。GenTasks。Hive的作法通常是碰到需要分發的地方,切上一刀,生成一道MapReduce作業。如Group By切一刀,Join切一刀,Distribute By切一刀,Distinct切一刀。
這麼很多刀砍下去之後,剛才那個邏輯執行計劃,也就是那個邏輯有向無環圖,就被切成了很多個子圖,每個子圖構成一個結點。這些結點又連成了一個執行計劃圖,也就是Task Tree.
把這些個Task Tree 還可以有一些優化,比如基於輸入選擇執行路徑,增加備份作業等。進行調整。這個優化就是由Physical Optimizer來完成的。經過Physical Optimizer,這每一個結點就是一個MapReduce作業或者本地作業,就可以執行了。
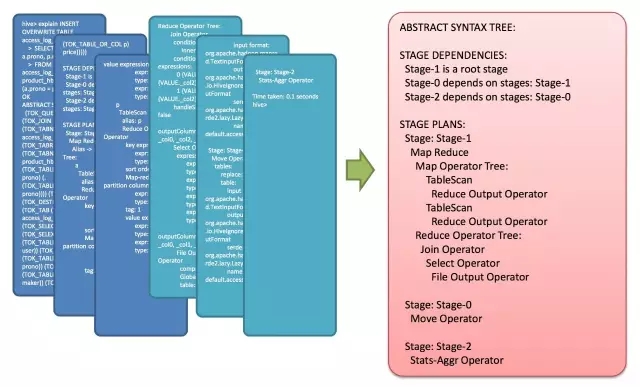
這就是一個SQL如何變成MapReduce作業的過程。要想觀查這個過程的最終結果,可以開啟Hive,輸入Explain + 語句,就能夠看到。
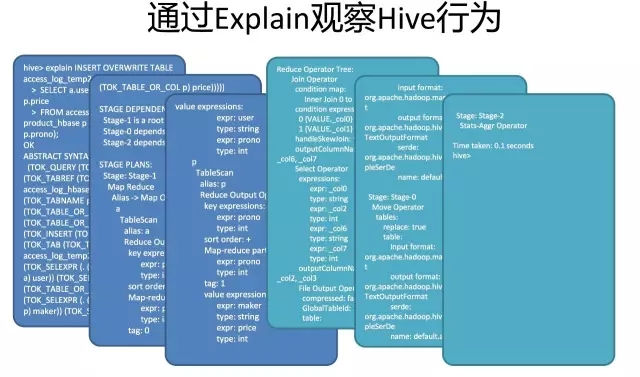
Hive最重要的部分是Group By和Join。下面分別講解一下:
首先是Group By
例如我們有一條SQL語句:
INSERT INTO TABLE pageid_age_sum
SELECT pageid, age, count(1)
FROM pv_users
GROUP BY pageid, age;
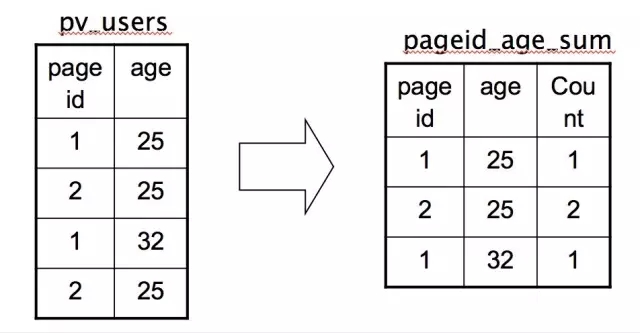
把每個網頁的閱讀數按年齡進行分組統計。由於前面介紹了,MapReduce就是一個Group By的過程,這個SQL翻譯成MapReduce就是相對簡單的。
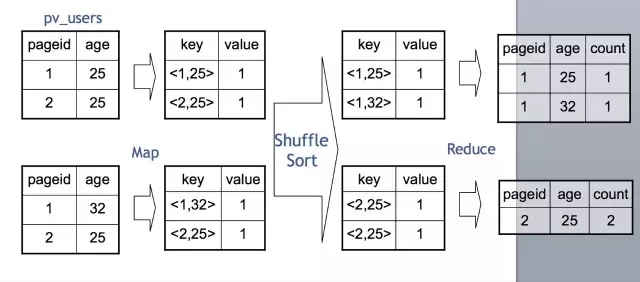
我們在Map端,每一個Map讀取一部分表的資料,通常是64M或者256M,然後按需要Group By的Key分發到Reduce端。經過Shuffle Sort,每一個Key再在Reduce端進行聚合(這裡是Count),然後就輸出了最終的結果。值得一提的是,Distinct在實現原理上與Group By類似。當Group By遇上 Distinct……例如:SELECT pageid, COUNT(DISTINCT userid) FROM page_view GROUP BY pageid
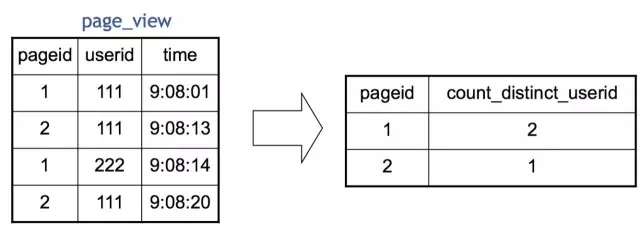
Hive 實現成MapReduce的原理如下:
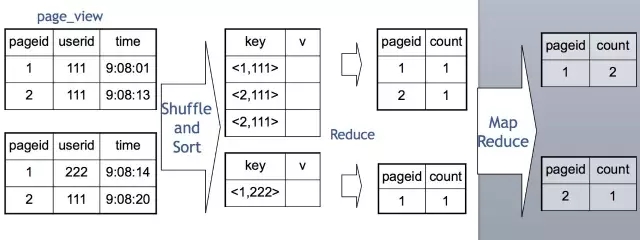
也就是說Map分發到Reduce的時候,會使用pageid和userid作為聯合分發鍵,再去聚合(Count),輸出結果。
介紹了這麼多原理,重點還是為了使用,為了適應場景和業務,為了優化。從原理上可以看出,當遇到Group By的查詢時,會按Group By 鍵進行分發?如果鍵很多,撐爆了機器會怎麼樣?
對於Impala,或Spark,為了快,key在記憶體中,爆是經常的。爆了就失敗了。對於Hive,Key在硬碟,本身就比Impala, Spark的處理能力大上幾萬倍。但……不幸的是,硬碟也有可能爆。
當然,硬碟速度也比記憶體慢上不少,這也是Hive總是被吐槽的原因,場景不同,要明白自己使用的場景。當Group By Key大到連硬碟都能撐爆時……這個時候可能就需要優化了。
Group By優化通常有Map端資料聚合和傾斜資料分發兩種方式。Map端部分聚合,配置開關是hive.map.aggr
也就是執行SQL前先執行 set hive.map.aggr=true;它的原理是Map端在發到Reduce端之前先部分聚合一下。來減少資料量。因為我們剛才已經知道,聚合操作是在Reduce端完成的,只要能有效的減少Reduce端收到的資料量,就能有效的優化聚合速度,避免爆機,快速拿到結果。
另外一種方式則是針對傾斜的key做兩道作業的聚合。什麼是傾斜的資料?比如某貓雙11交易,華為賣了1億臺,蘋果賣了10萬臺。華為就是典型的傾斜資料了。如果要統計華為和蘋果,會用兩個Reduce作Group By,一個處理1億臺,一個處理10萬臺,那個1億臺的就是傾餘。
由於按key分發,遇到傾斜資料怎麼辦?
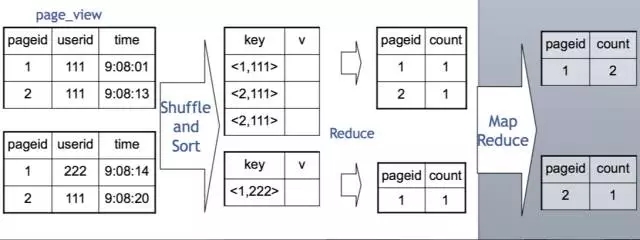
可以使用hive.groupby.skewindata選項,通過兩道MapReduce作業來處理。當選項設定為 true,生成的查詢計劃會有兩個 MR Job。第一個 MR Job 中,Map 的輸出結果集合會隨機分佈到Reduce 中,每個 Reduce 做部分聚合操作,並輸出結果,這樣處理的結果是相同的 Group By Key有可能被分發到不同的 Reduce 中,從而達到負載均衡的目的;第二個 MR Job 再根據預處理的資料結果按照 Group ByKey 分佈到 Reduce 中(這個過程可以保證相同的
Group By Key 被分佈到同一個 Reduce中),最後完成最終的聚合操作。
第一道作業:Map隨機分發,按gby key部分聚合
第二道作業:第一道作業結果Map傾斜的key分發,按gbk key進行最終聚合
無論你使用Map端,或者兩道作業。其原理都是通過部分聚合來來減少資料量。能不能部分聚合,部分聚合能不能有效減少資料量,通常與UDAF,也就是聚合函式有關。也就是隻對代數聚合函式有效,對整體聚合函式無效。
所謂代數聚合函式,就是由部分結果可以彙總出整體結果的函式,如count,sum。 所謂整體聚合函式,就是無法由部分結果彙總出整體結果的函式,如avg,mean。 比如,sum, count,知道部分結果可以加和得到最終結果。 而對於,mean,avg,知道部分資料的中位數或者平均數,是求不出整體資料的中位數和平均數的。
在遇到複雜邏輯的時候,還是要具體問題具體分析,根據系統的原理,優化邏輯。剛才說了,Hive最重要的是Group By和Join,所以下面我們講Join.
>>>>JOIN
例如這樣一個查詢:INSERT INTO TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv JOIN user u ON (pv.userid = u.userid);

把訪問和使用者表進行關聯,生成訪問使用者表。Hive的Join也是通過MapReduce來完成的。
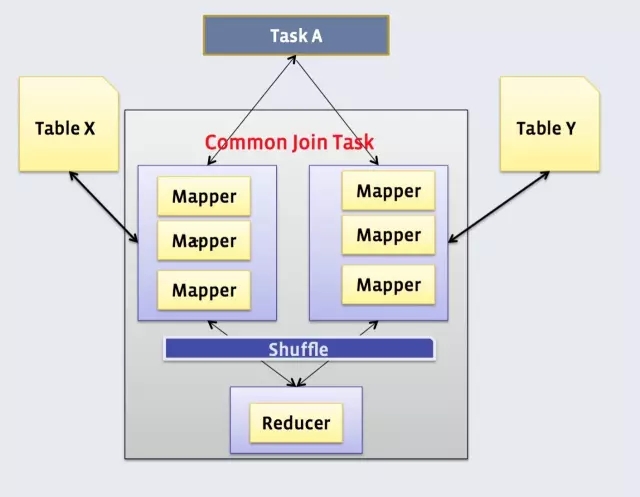
就上面的查詢,在MapReduce的Join的實現過程如下:
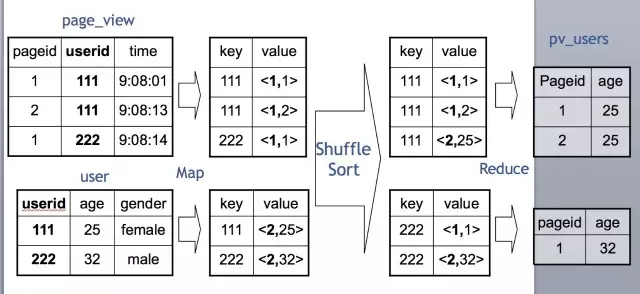
Map端會分別讀入各個表的一部分資料,把這部分資料進行打標,例如pv表標1,user表標2.
Map讀取是分散式進行的。標完完後分發到Reduce端,Reduce 端根據Join Key,也就是關聯鍵進行分組。然後按打的標進行排序,也就是圖上的Shuffle Sort。
在每一個Reduce分組中,Key為111的在一起,也就是一臺機器上。同時,pv表的資料在這臺機器的上端,user表的資料在這臺機器的下端。
這時候,Reduce把pv表的資料讀入到記憶體裡,然後逐條與硬碟上user表的資料做Join就可以了。
從這個實現可以看出,我們在寫Hive Join的時候,應該儘可能把小表(分佈均勻的表)寫在左邊,大表(或傾斜表)寫在右邊。這樣可以有效利用記憶體和硬碟的關係,增強Hive的處理能力。
同時由於使用Join Key進行分發, Hive也只支援等值Join,不支援非等值Join。由於Join和Group By一樣存在分發,所以也同樣存在著傾斜的問題。所以Join也要對抗傾斜資料,提升查詢執行效能。
通常,有一種執行非常快的Join叫Map Join 。
>>>>Map Join 優化
手動的Map Join SQL如下:
INSERT INTO TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv JOIN user u
ON (pv.userid = u.userid);
還是剛才的例子,用Map Join執行

Map Join通常只適用於一個大表和一個小表做關聯的場景,例如事實表和維表的關聯。
原理如上圖,使用者可以手動指定哪個表是小表,然後在客戶端把小表打成一個雜湊表序列化檔案的壓縮包,通過分散式快取均勻分發到作業執行的每一個結點上。然後在結點上進行解壓,在記憶體中完成關聯。
Map Join全過程不會使用Reduce,非常均勻,不會存在資料傾斜問題。預設情況下,小表不應該超過25M。在實際使用過程中,手動判斷是不是應該用Map Join太麻煩了,而且小表可能來自於子查詢的結果。
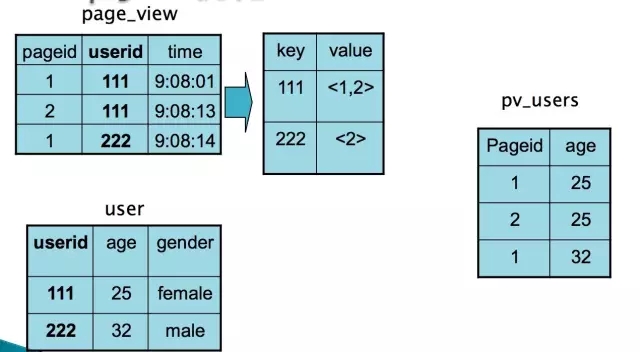
Hive有一種稍微複雜一點的機制,叫Auto Map Join
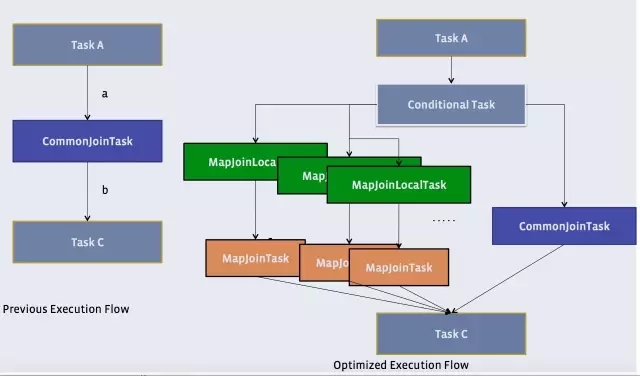
還記得原理中提到的物理優化器?Physical Optimizer麼?它的其中一個功能就是把Join優化成Auto Map Join
圖上左邊是優化前的,右邊是優化後的
優化過程是把Join作業前面加上一個條件選擇器ConditionalTask和一個分支。左邊的分支是MapJoin,右邊的分支是Common Join(Reduce Join)
看看左邊的分支是不是和我們上上一張圖很像?
這個時候,我們在執行的時候,就由這個Conditional Task 進行實時路徑選擇,遇到小於25兆走左邊,大於25兆走右邊。所謂,男的走左邊,女的走右邊,人妖走中間。
在比較新版的Hive中,Auto Mapjoin是預設開啟的。如果沒有開啟,可以使用一個開關, set hive.auto.convert.join=true 開啟。
當然,Join也會遇到和上面的Group By一樣的傾斜問題。
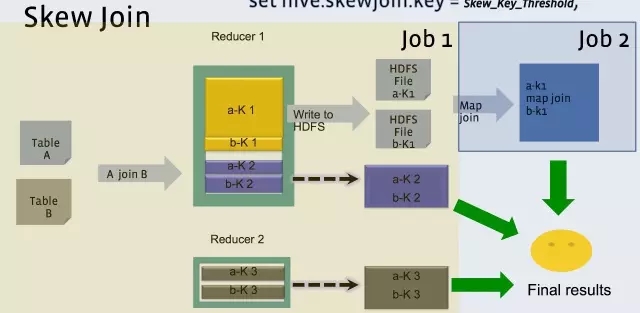
Hive 也可以通過像Group By一樣兩道作業的模式單獨處理一行或者多行傾斜的資料。
>>>>
hive 中設定
set hive.optimize.skewjoin = true;
set hive.skewjoin.key = skew_key_threshold (default = 100000)
其原理是就在Reduce Join過程,把超過十萬條的傾斜鍵的行寫到檔案裡,回頭再起一道Join單行的Map Join作業來單獨收拾它們。最後把結果取並集就是了。如上圖所示。
Update/Insert/Delete原理
Hive從0.14開始支援ACID。也就是支援了Update Insert Delete及一些流式的API。也就是這個原因,Hive把0.14.1 Bug Fixes版本改成了 Hive 1.0,也就是認為功能基本穩定和健全了。
由於HDFS是不支援本地檔案更改的,同時在寫的時候也不支援讀。
表或者分割槽內的資料作為基礎資料。事務產生的新資料如Insert/Update/Flume/Storm等會儲存在增量檔案(Delta Files)中。讀取這個檔案的時候,通常是Table Scan階段,會合並更改,使讀出的資料一致。
Hive Metastore上面增加了若干個執行緒,會週期性地合併併合並刪除這些增量檔案。
具體可以實現參考這個網頁。 https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions
>>>>
Hive適合做什麼?
由於多年積累,Hive比較穩定,幾乎是Hadoop上事實的SQL標準。 Hive適合離線ETL,適合大資料離線Ad-Hoc查詢。適合特大規模資料集合需要精確結果的查詢。對於互動式Ad-Hoc查詢,通常還會有別的解決方案,比如Impala, Presto等等。
特大規模的離線資料處理,尤其是大表關聯,特大規模資料聚集,很適合使用Hive。講了這麼多原理,最重要的還是應用,還是創造價值。
對Hive來說,資料量再大,都不怕。資料傾斜,是大難題。但有很多優化方法和業務改進方法可以避過。Hive執行穩定,函式多,擴充套件性強,資料吞吐量大,瞭解原理,有助於用好和選型。