
python--識別圖片中的文字
本篇文章主要參考了 python影象處理之識別影象中的文字 這篇文章,在實現的過程中出現了些偏差,特此記錄。因為此時筆者不是第一次安裝,所展示的結果會和首次安裝的結果有所差別。
1.安裝PIL
以管理員的身份開啟命令提示符,輸入:pip install pillow.
(注:PIL是python平臺事實上的影象處理標準庫,但PIL僅支援到python2.7,加上年久失修,於是在PIL的基礎上建立了相容的版本pillow,支援最新的python3.X。)
2.安裝pytesser3
開啟命令提示符,輸入:pip install pytesser3
3.安裝pytesseract
開啟命令提示符,輸入:pip install pytesseract

4.安裝autopy3
先安裝wheel,即先在命令提示符中輸入pip install wheel。
下載autopy3-0.51.1-cp36-cp36m-win_amd64.whl。點選此處下載,此時該檔案所在目錄為D:\liuyan\autopy3-0.51.1-cp36-cp36m-win_amd64.whl。
在命令提示符中輸入: pip install D:\liuyan\autopy3-0.51.1-cp36-cp36m-win_amd64.whl
5.安裝Tesseract-OCR
5.1 下載安裝包
百度搜索Tesseract-OCR下載 Tesseract-orc-setup-3.02.02.exe 。要記得自己的安裝目錄(博主的安裝路徑為:C:\Program Files(x86)\Tesseract-OCR),等會配置環境變數要用。
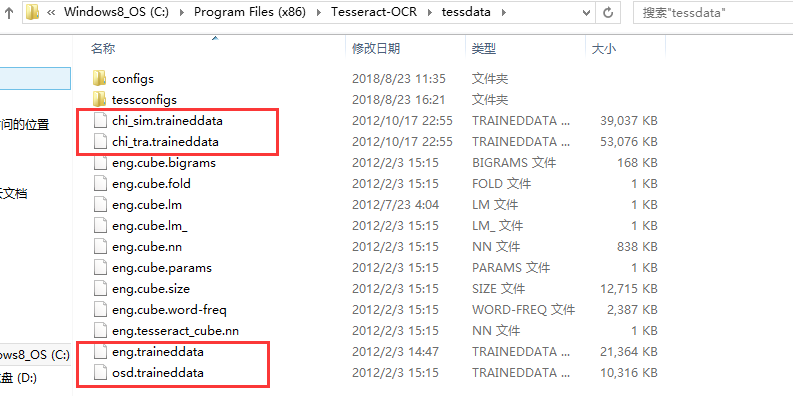
如果不是做英文的圖文識別,還需要下載其他語言的識別包 其他語言各版本的識別包下載 ,如簡體字識別包對應的是chi_sim.traineddata ,繁體字識別包對應的是chi_tra.traineddata 。
5.2 安裝
5.3 配置環境變數
博主的安裝路徑為:C:\Program Files(x86)\Tesseract-OCR。電腦屬性--高階系統設定--環境變數,進入如下介面。
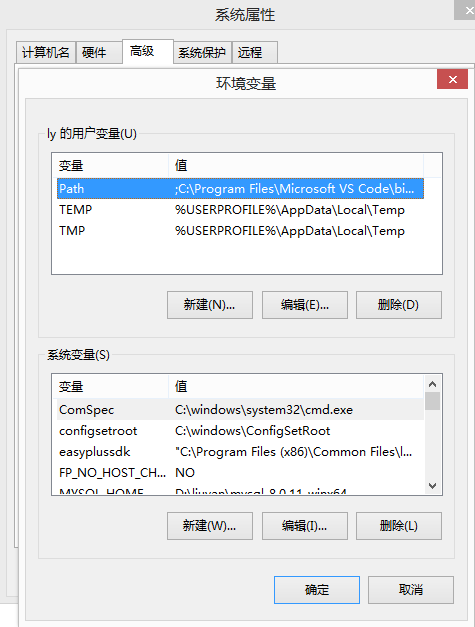
把剛剛的安裝路徑"C:\Program Files(x86)\Tesseract-OCR"新增到使用者變數和系統變數的path中,注意,新增的時候開頭用";"跟之前的變數隔開,以";"結尾。配置好後點擊確定。
開啟命令終端,輸入:tesseract -v,可以看到版本資訊。

到這裡,我們就算安裝完成了。但是,我們的系統還是無法識別中文的,要去下載簡體漢字、繁體漢字語言包(其他語言各版本識別包下載),下載好之後放到安裝目錄的tessdata目錄下即可。
5.4 驗證是否安裝成功
進入cmd視窗,敲入命令cd C:\Program Files (x86)\Tesseract-OCR,再輸入tesseract,若有如下資訊則表示安裝成功。
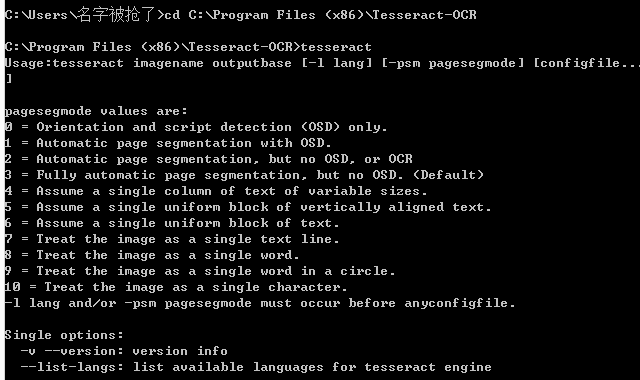
還可以用命令tesseract --list-langs來檢視Tesseract-OCR支援的語言。
入門使用
1.tesseract是一個命令列OCR程式,開啟一個終端(Win+R),輸入語法如下:
tesseract 輸入圖片的檔名 輸出檔案的檔名 [-l lang][-psm pagesegmode][configfile...]例如:識別 微信圖片5.png 影象,將識別結果存入 out2.txt,如下

2.用pycharm進行影象中的漢字識別
要識別的原圖如下:(來自小華的《煙火裡的塵埃》)

實現的程式碼如下:
import pytesseract
from PIL import Image
im=Image.open(r'C:\Users\名字被搶了\desktop\圖片2.png')
print(pytesseract.image_to_string(im,lang='chi_sim'))效果圖
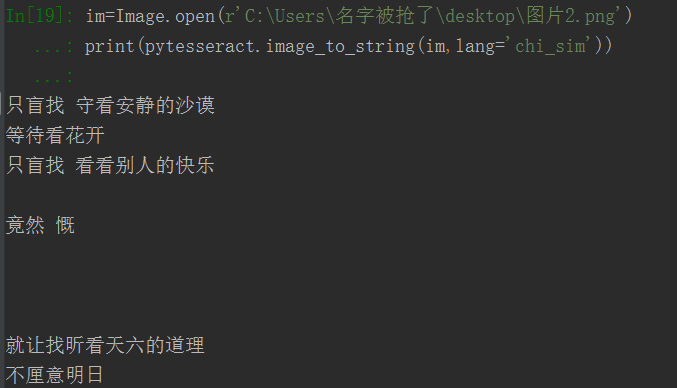
識別的效果不是很好,有待於進一步提高正確率。