
遞迴演算法深入淺出五:深度搜索尋找圖最短路徑
如果你看到這篇文章並不是在我的CSDN部落格釋出,同時文章裡面的圖片、URL全沒了的,那麼,很有可能你上了一個爬蟲網站!
在此,我建議你馬上關閉該頁面!因為爬蟲或多或少都會出現內容的紕漏,對讀者造成的危害更大,誤人子弟。
同時,轉載本文的請加上本文連結:
對於爬蟲網站隨意爬取以及轉載不加本文連結的,本人保留追究法律責任的權力!
對於不尊重版權的行為,我們也沒必要客氣!
深度優先搜尋
又稱深度搜索、深搜。簡單地說深搜就是一種**【不撞南牆不回頭】** 的 暴力演算法,基本上該演算法常用遞迴作為設計基礎,當然也有使用for迴圈巢狀的,本文是以遞迴為講解方向的。
至於更深一層的理論在這裡就不詳細說明了,詳細可以去搜索更多關於。
簡單的圖搜尋問題
本文講述的是一個基於無向圖為基礎的圖搜尋,用二位陣列組成的圖。
【關於圖的更多的理論也麻煩大家去搜索相關的資料,今天寫這個文章主要針對下面描述的問題,在這裡不過多闡述】
問題描述
描述如下:
在一個n行m列組成的二位陣列中,每個單元格代表空地或障礙物。
鄰接的單元格距離單位為1,但不包括對角的單元格。
圖中是屬於無向圖,移動的方向不受限制(不能出界)。
現在給定在圖中任意的兩個座標(兩個均座標不屬於障礙物),求出兩個座標之間到達的最短距離。
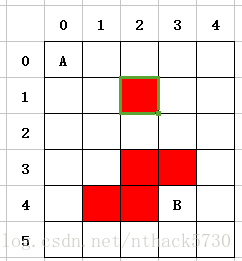
如圖:
這是一個6行5列的圖,其中 (1,2)、(3,2)、(3,3) 、(4,1)、(4,2) 為障礙物
求A點到B點的最短距離
問題分析
問題中可以知道這是一個由二維陣列組成的圖,每個單元格代表空地或者障礙物。
現在要從A點到達B點或者從B點到達A點,行走的方向可以是(上、下、左、右),同時要避開所有紅色的障礙物(如上圖)。首先要明白每走一步所到達的位置:
- 當在A點(0,0)時,下一步能到達的點為**(0,1)、(1,0)**
- 當在點**(0,1)時,下一步能到達的點為(0,0)、(1,1)、(1、2)**
- 當在點**(1,0)時,下一步能到達的點為(0,0)、(2,0)、(1、1)**
- 當在點**(1,1)時,由於(1,2)為障礙物**,因此下一步能到達的點為**(0,1)、(1,0)、(2,1)**
- 每一步都去嘗試下一步可以到達的位置,直到到達終點B。
有個問題就來了,例如上面的,有的位置是已經被走過的,如果程式沒有對走過的位置進行判斷,那麼可能永遠都不能到達B點...
應該怎麼做呢?定義一個結果集來記錄當前訪問過的點。
請慢慢往下看,別急!
遞迴程式設計思路
一、定義
1. 設定地圖
我們可以用一個二維的 int 陣列來表示該圖,我們假設在陣列中:- 值為 1 的是障礙物
- 值為 0 的是為空地
- 注意:使用二維int陣列的原因是:如果需要,可以用數字表示不同型別的障礙物,本問題中可以用boolean陣列表示空地或障礙物,但為了讓大家更加清晰不和下面的 boolean[][] used 二維標記陣列弄混,還是使用 int[][] map 來定義。
那麼就可以得出下列二維陣列:
0 0 0 0 0
0 0 1 0 0
0 0 0 0 0
0 0 1 1 0
0 1 1 0 0
0 0 0 0 0
2. 首先是定義需要用上的變數:
- int n,m:定義圖的大小。
- int[][] map:需要搜尋的圖(在這裡用int[][]二維陣列表示)
- boolean[][] used:大小和圖一樣,用於標記被訪問過的點(訪問過為true),保證每次走的都是沒有被走過的點,這也是解決上面的重複訪問同一個點的問題的方案
- int p,q:終點的Y軸、X軸座標,由使用者輸入。
- int count:計算由起點到終點所有的可行路徑。
- int minStep:記錄最短路徑所需要的步數,因為要考慮起點和終點為同一個點,因此設定初始值為 -1。
3.設定一個 dfsMap(...) 方法,該方法主要用於深度搜索圖。
除了上面設定的變數,dfsMap(...) 需要管理的引數有:- int x:當前點所在的X軸座標值
- int y:當前點所在的Y軸座標值
- int step:當前點與開始點的距離
二、程式碼編寫的思路
當我們在一個點時,需要做的是要判斷當前所在的點是否為終點,如果是終點,那麼就對歷史記錄進行判斷,程式碼如下:
if (y == p && x == q) {
System.out.println("找到一條路徑,距離為:" + step);
count++;
if (minStep == -1) {
minStep = step;
}
if (step < minStep) {
minStep = step;
}
}
如果不是終點,那麼程式就要去尋找當前點的下一步;同時,我們需要用上boolean[][] used二維陣列,大小和當前的地圖一樣,用於標記當前地圖中哪些點被訪問過,如果被訪問過,那麼就跳過該點。
假設目前所在點的位置為 (x,y),那麼可以得出下一步可到達的點為:
(x+1, y)、(x-1, y)、(x, y+1)、(x, y-1),如下圖:
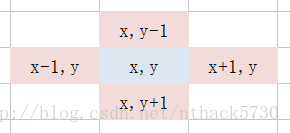
轉換成程式碼形式就是,該陣列可以定義為全域性靜態變數:
int[][] wayPoint = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
根據上面四個點,用表格來表示(X,Y)座標的變化量更為直觀:(以行為變化單位)
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
用迴圈就能得到以(X,Y)為中心的周邊四個點。
但得出這些點並不能一下子就進行遞迴尋路操作,要確定這些點是不是能夠“走”得到,需要對其進行邊界和障礙物以及該點是否被訪問過判斷。程式碼如下:
for (int i = 0; i < 4; i++) {
int gX, gY;//新的座標位置
gX = x + wayPoint[i][0];//獲取每行的第0列,即上面表格中X的變化值
gY = y + wayPoint[i][1];//獲取每行的第1列,即上面表格中Y 的變化值
//判斷越界
if (gX < 0 || gX >= m || gY < 0 || gY >= n) {
continue;
}
//判斷障礙物,以及該點是否被訪問過
if (map[gY][gX] == 1 || used[gY][gX] == true) {
continue;
}
....
}
三、得到dfs(...)遞迴體程式碼
在對新的點進行判斷後,就確定該點是能到達的,那麼就可以 將當前的結果集(即當前深度搜索所走過的位置的集合) 進行遞迴,繼續交給 dfsMap(...) 方法進行迭代尋找。
在進入該點之前,我們需要標記該點已經被訪問過,同時在遞迴結束之後要對標記進行消除, dsfMap(int, int ,int) 核心程式碼如下:
/**
* @param x 當前所處的X軸座標
* @param y 當前所處的Y軸座標
* @param step 距離
*/
static void dfsMap(int x, int y, int step) {
if (y == p && x == q) {
//System.out.println("找到一條路徑,距離為:" + step);
count++;
if (minStep == -1) {
minStep = step;
}
if (step < minStep) {
minStep = step;
}
} else {
for (int i = 0; i < 4; i++) {
int gX, gY;//新的座標位置
gX = x + wayPoint[i][0];//獲取每行的第0列,即上面表格中X的變化值
gY = y + wayPoint[i][1];//獲取每行的第1列,即上面表格中Y 的變化值
//判斷越界
if (gX < 0 || gX >= m || gY < 0 || gY >= n) {
continue;
}
//判斷障礙物,以及該點是否被訪問過
if (map[gY][gX] == 1 || used[gY][gX] == true) {
continue;
}
used[gY][gX] = true;
dfsMap(gX, gY, step + 1);
used[gY][gX] = false;
}
}
}
測試
最終完整的程式碼如下:
//此文老貓原創,轉載請加本文連線:
//http://blog.csdn.net/nthack5730/article/details/71774434
//更多有關老貓的文章:http://blog.csdn.net/nthack5730
public class SearchMap {
static int[][] map;
static boolean[][] used;
//圖面積設定
static int n;
static int m;
//需要尋找的點
static int p;
static int q;
//最小位置
static int minStep = -1;
//次數統計
static int count = 0;
static int[][] wayPoint = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.println("輸入圖的行、列:");
n =scan.nextInt();
m =scan.nextInt();
System.out.println("輸入開始點的座標:");
int startX = scan.nextInt();
int startY = scan.nextInt();
System.out.println("輸入終點的座標:");
p =scan.nextInt();
q =scan.nextInt();
map = new int[n][m];
used = new boolean[n][m];
System.out.println("輸入圖資料:");
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
map[i][j] = scan.nextInt();
}
}
//遞迴呼叫開始
used[startY][startX] = true;//初始化開始點被訪問過,注意Y值代表行,X值代表列
dfsMap(startX, startY, 0);
//輸出結果
System.out.println("\n//=============================");
System.out.println("// 找到的總路徑數為:" + count);
if (minStep == -1) {
System.out.println("// 沒有找到結果");
} else {
System.out.println("// 最小距離為:" + minStep);
}
System.out.println("\n//=============================");
}
/**
* 深搜暴力尋圖
*
* @param x 當前所處的X軸座標
* @param y 當前所處的Y軸座標
* @param step 距離
*/
static void dfsMap(int x, int y, int step) {
if (y == p && x == q) {
// System.out.println("找到一條路徑,距離為:" + step);
count++;
if (minStep == -1) {
minStep = step;
}
if (step < minStep) {
minStep = step;
}
} else {
for (int i = 0; i < 4; i++) {
int gX, gY;//新的座標位置
gX = x + wayPoint[i][0];//獲取每行的第0列,即上面表格中X的變化值
gY = y + wayPoint[i][1];//獲取每行的第1列,即上面表格中Y 的變化值
//判斷越界
if (gX < 0 || gX >= m || gY < 0 || gY >= n) {
continue;
}
//判斷障礙物,以及該點是否被訪問過
if (map[gY][gX] == 1 || used[gY][gX] == true) {
continue;
}
used[gY][gX] = true;
dfsMap(gX, gY, step + 1);
used[gY][gX] = false;
}
}
}
}
測試輸入如下:
輸入圖的行、列:
6 5
輸入開始點的座標:
0 0
輸入終點的座標:
4 3
輸入圖資料:
0 0 0 0 0
0 0 1 0 0
0 0 0 0 0
0 0 1 1 0
0 1 1 0 0
0 0 0 0 0
程式輸出:
//=============================
// 找到的總路徑數為:124
// 最小距離為:9
//=============================總結
難點所在
至此,深度搜索圖的最短路徑已經完成。其中最難理解的應該就是每次遞迴前標記位置已經被訪問,並且在遞迴結束(相當於當前層)後對標記進行撤銷:
....
used[gY][gX] = true;
dfsMap(gX, gY, step + 1);
used[gY][gX] = false;
....
回到圖搜尋
我們將圖分為兩類結果集:
- 一類是“已經被訪問過的”結果集
- 剩下的就是“沒有被訪問過的”結果集
- 每次進行下一步都是以 當前“已經被訪問過的”集合 為基礎,將當前的結果集繼續迭代
- 當 “當前的結果集” 所有的可能性都被嘗試完時,就要將當前結果集的最後一步還原為上一個結果集的狀態。
在這裡,我簡單地用數學集合表示法描述下:
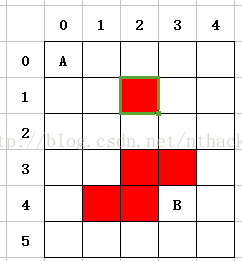
按照上圖,假設程式在前面訪問了2個點:(0,0)、(0,1),其中(0,1)是目前遊標所在(最後一個訪問的)。
設U為全圖所有點的集合,設A為“已經被訪問過的”結果集,當**A ={(0,0)、(0,1)}**時,剩下的 {U - A} 都是沒有被訪問的集合。
按照【每次只能走一步】的約定,當我們要走下一步時只能走(0,2)、(1,1)兩個中的一個:
- 按照順時針訪問順序,我們先走(0,2)這個點,對應程式碼中標記:
used[gY][gX] = true;
- 當走到(0,2)時,集合A就變為{(0,0),(0,1),(0,2)},設為A1,如果還要繼續往下走,那麼就要在A1的基礎上繼續擴充套件,對應程式碼中遞迴呼叫,表示繼續從(0,2)這個點繼續擴充套件其所有的結果:
dfsMap(gX, gY, step + 1);
- 當A1所有的情況都嘗試完的時候,A1就要返回A的集合狀態,這時就要從集合A1中移除(0,2),在程式碼中也就是取消(0,2)的標記:
used[gY][gX] = false;
- 當返回到集合A的資料時,就要去訪問(1,1)這個點,繼續重複上面的1,2,3步。
至於擴充套件的順序,就是根據上面定義的方向陣列waypoint陣列,用for迴圈獲取所有的(上、下、左、右)可能,然後進行1,2,3步
當然,在進行遞迴迭代之前,要對新的點進行邊界、障礙物判斷。
這個過程與全排列生成的解答樹相似
圖片參考《演算法競賽:入門經典》中P119頁的圖。
裡面通過描述全排列生成的解答樹,和本題的思維非常相似,如圖:

和全排列相似地,整個過程就如同生成一棵解答樹【如圖】:
- 每到達一個結點,所有已知的(走過的)都是一個結果集;
- 同時當前結果集與下一個可行的結點又會形成一個新的結果集(可行的結點越多,新的結果集越多);
- 如此下去,直到當前結果集的所有可行結點被列舉,返回當前結果集的上一個結果集;
- 當所有的結果集都被列舉,那麼就能得出所有可行性的遍歷。
寫在最後
雖然本人技術和文筆和很多大牛相比都是一般般的,但我樂於和大家分享技術、交流。
撰寫本文差不多花了一個多星期的時間去收集整理資料、寫稿。程式碼也前後修改了很多次,不修改分塊發出來很多人根本看不懂(變數比較多),也不想一次過全部程式碼“無腦推送”。如果你喜歡本文,請在下面給我點個贊吧!
(^ _ ^)
如果你看到這篇文章並不是在我的CSDN部落格釋出,同時文章裡面的圖片、URL全沒了的話,那麼,很有可能你上了一個爬蟲網站!
在此,我建議你馬上關閉該頁面!因為爬蟲或多或少都會出現內容的紕漏,對讀者造成的危害更大,誤人子弟。
同時,轉載本文的請加上本文連結:http://blog.csdn.net/nthack5730/article/details/71774434
對於爬蟲網站隨意爬取以及轉載不加本文連結的,本人保留追究法律責任的權力!
對於不尊重版權的行為,我們也沒必要客氣!