
為什麼有些語言可以被反編譯?而有的不能?
要理解這個問題,先要看「正」編譯的過程是怎樣的。
你有一個想法,這是一種人類自然語言可以表達出來的東西。你利用程式設計技能,把它「翻譯」成你熟悉的一種程式語言:

這個過程叫做程式設計。
然後你使用編譯器(compiler)將它翻譯成機器所能理解的語言:

這個過程叫做編譯。程式設計和編譯都是「資訊丟失」的過程。比如你說,我有一組整數,我要把這些數排個序,然後輕車熟路地寫了個氣泡排序。然而一定程度上,你的原始動機其實已經從程式碼裡丟失了——有經驗的人可以一眼看出這段程式碼是在排序,而新手小明看到的只有一些 for 和 if 之類的東西。如果是更復雜的功能,可能過一段時間你自己都看不懂自己當時是想幹什麼。從程式語言到機器語言的過程其實也是一樣的。這兩個過程其實都是把「做什麼」轉換成「怎麼做」的過程
所謂「反編譯」,其實就是找回這些丟失的資訊的過程。從這個角度上來說,你閱讀一段程式碼的過程,其實就是在將它「反編譯」成自然語言。如果要完美地反編譯,那隻存在一種可能,就是資訊完全沒有丟失——比如說你閱讀的這段程式碼有充分的註釋,或者它使用了一種你所知曉的模式(這也是為什麼大家一再強調註釋和設計模式的重要性)。對於從機器語言到程式語言的反編譯過程,也是一樣。
比如說有比反編譯更低階(非貶義)的過程,叫做反彙編:

嚴格來說組合語言也是一種程式語言,不過我們在這裡把它和我們常說的高階程式語言(包括C語言)區分開。
這個步驟裡,我在彙編和機器語言裡使用的是雙向實線箭頭,因為它們是可以互相轉換的。從組合語言到機器語言的過程中沒有丟失任何資訊——因為兩者的指令是一一對應的,因此反彙編可以輕鬆達成。
這就是很多程式語言只能反彙編、不能(難以,下同)反編譯的原因。一般我們管這種語言叫「編譯語言」,又稱「原生語言」。代表有C、C++等。
那為什麼有的語言可以反編譯呢?這又要從機器語言說起。就像不同地域的人所用的語言不同一樣,不同的機器說的語言也不盡相同。用行話說,叫「指令集不同」。比方說,你的電腦和你的手機,指令集通常是不一樣的。一段程式要讓不同的機器都能執行,只能分別翻譯(編譯)成相應的機器語言。這個過程太麻煩了,於是人們想了個辦法,搞出了一種叫解釋語言的東西(此處未考證解釋語言是否就是因此發明的,只是幫助理解)。如下圖:
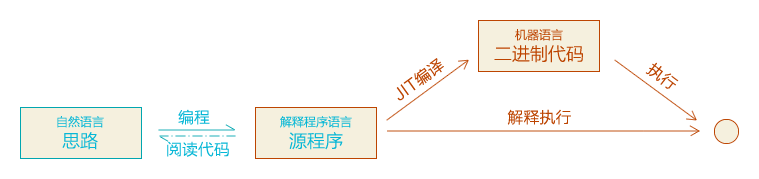
解釋語言有兩種執行方式,這取決於執行端的「直譯器」是如何工作的。一種是直接解釋執行,中間就沒有機器語言什麼事情了,但這種方式效率很低。因此現代的解釋語言基本上都會採用第二種方式,也就是經由圖中上部的路徑,先通過JIT編譯的方式翻譯成機器語言,然後再執行,保證執行效率。JIT編譯大致可以理解為「用到什麼就編譯什麼」,這個過程常常是在執行過程中同步進行的。
「直譯器」的英文interpreter,其實就是名詞「翻譯」的意思。這好比你國外交部發了封檔案到各國大使館,再由大使館的工作人員分別翻譯成相應的語言,傳達給目標國相關部門。代表性的解釋語言如Javascript,它要在不同機器的瀏覽器上都能正確執行,所以採用這種方式。
但是這樣一來,程式程式碼就必須提供給每一臺執行端機器了。這可是洩密啊。對於防止洩密,最直接的方式自然是加密。

有鎖就有鑰匙,同時也有開鎖術;有加密解密,也有相應的破解方式。這時候所謂的「反編譯」,其實就是破解加密演算法。這一點就不展開聊了。
後來,人們覺得解釋語言執行得實在有點慢,於是又想了一個辦法:把一些可以前期做掉的工作先做掉,只留著那些跟目標機器有關的工作,到時候再說。於是程式被處理成了一種叫做「中間語言」,或者叫「位元組碼」的東西:

這個過程一般也叫做編譯。中間語言詞彙少,比較精煉,執行起來也更快。這些語言一般也會用上JIT技術,進一步把中間語言編譯成機器語言(而非解釋執行),執行效率也就跟那些原生的編譯語言不相上下了。這種語言代表性的有C#、Java等。
程式語言可以編譯成中間語言,反過來,中間語言也可以在一定程度上反編譯成程式語言。這是因為採用這種編譯方式的程式語言為了保證它們的高階特性(比如說反射),在編譯的過程中保留了源程式的絕大部分資訊,只有很少的資訊丟失;也正是因為丟失了這一部分資訊,中間語言通常不能完美地反編譯——最常見的就是反編譯出來的程式中區域性變數的名字都丟了,被替換成了由反編譯器自動生成的名字。但這樣反編譯出來的程式,結構和功能都是完備的,可讀性也有一定的保障。一般來說,我們所說的可以反編譯的程式都是指這樣一類語言寫就的程式。
中間語言可以被反編譯;加密又會被破解,而且執行前還要解密,會帶來額外的效能開銷。有沒有辦法能讓程式碼既能有效執行,又不被截獲程式碼的人所利用呢?這時候人們從一些職業素養很差的程式設計師那裡得到了啟發。
實現一個相同的功能,可以有無數種形式的程式碼。你恪盡職守,認認真真地寫註釋,準確地命名函式和變數, 嚴格按照規範進行縮排和換行;小明卻相反,完全沒有註釋,變數全部用abcd乃至故意誤導別人(var mySon = laowang.Son),縮排換行邋遢,尤其是在大括號前不換行,讓大家很不滿。於是老闆想,我們先把小明開除掉,然後給你發獎金並要求大家按照你的方式寫程式碼,並且開發一個工具,喚作「混淆器」,在釋出時再把程式碼處理成小明寫的那種樣子:

這樣程式碼即使被反編譯和解密了,別人看也看不懂,不小心還會被帶到坑裡去。程式碼畢竟是寫給人看的,只是偶爾讓機器跑一跑,所以沒有可讀性的程式碼是沒有價值的。這種方法一出,廣受好評,於是變成了一種非常普遍的做法。注意圖中省略了中間程式碼和JIT的步驟,混淆通常會跟這些技術一起使用。
轉自:https://www.zhihu.com/question/21853681/answer/74134768