
python動態渲染頁面的爬取--使用Selenium
2018年4月26日
10:05
一、安裝相關包和軟體
1、安裝Selenium包
Pip3 install Selenium
2、安裝chromedriver
訪問chromedriver映象站,下載對應版本的chromedriver,例如我的瀏覽器版本為

安裝的的chromdriver為v2.38(其支援的瀏覽器版本為v65-67,在其支援範圍內,下載後將其加入系統環境變數)

3、對之前的安裝進行測試
執行以下程式碼,如果能正確彈出chrome瀏覽器視窗,則正常(不正常的情況下重點檢查chromedriver版本)
from selenium import webdriver
browser=webdriver.Chrome()
二、Selenium的相關功能
1、初始化
from selenium import webdriver
browser=webdriver.Chrome()
該程式碼完成了瀏覽器物件的初始化,呼叫了Chrome瀏覽器(Selenium同樣支援其他瀏覽器,如browser=webdriver.Firefox(),browser=webdriver.Safari())
2、訪問頁面
browser.get('https://www.baidu.com') #執行了開啟百度網頁操作
print(browser.page_source) #輸出了網頁原始碼
Browser.close()#關閉了瀏覽器
3、查詢節點
這裡以淘寶網為例,檢視淘寶首頁原始碼
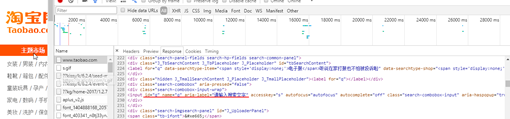
發現淘寶首頁搜尋框部分的id和name均為q
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.taobao.com') #開啟淘寶網頁
input_first=browser.find_element_by_id('q') #根據id進行選擇
input_second=browser.find_element_by_css_selector('#q') #根據css選擇器進行選擇
input_third=browser.find_element_by_xpath('//*[@id="q"]') #Xpath進行獲取
print(input_first)
print(input_second)
print(input_third)
browser.close()
執行以上程式碼,輸出結果為

三種方式結果完全相同
4、簡單互動
From selenium import webdriver
Import time
browser=webdriver.Chrome()
browser.get('https://www.taobao.com') #開啟淘寶
input=browser.find_element_by_id('q') #找到id為q的節點,也就是搜尋框
input.send_keys('Ipad') #輸入ipad
time.sleep(1) #暫停1秒
input.clear() #清空之前輸入的內容
input.send_keys('MI6') #輸入MI 6
button=browser.find_element_by_class_name('btn-search') #找到搜尋按鈕
button.click() #點選搜尋
以上程式碼中包含了輸入,清空內容,點選三種常用動作
5、執行JavaScript
使用execute_script()方法可以執行JavaScript,從而實現API沒有實現的功能
例如以下程式碼
From selenium import webdriver
Import time
browser=webdriver.Chrome()
url=('https://www.zhihu.com/explore')
browser.get(url)
time.sleep(3)
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_script('alert("ToBottom")')
該程式碼打開了知乎的explore頁面,並且呼叫JavaScript語句window.scrollTo(0,document.body.scrollHeight)翻頁到頁面最底部,
然後呼叫alert("ToBottom")輸出To Bottom
6、獲取節點資訊(需要選選中節點)
獲取屬性(get_attribute())
Test= browser.find_element_by_id('p') #選中了id為P的節點
Print(test.get_attribute('class')) #輸出該節點的class
獲取文字(.text),獲取id(.id),獲取位置(.location),獲取標籤名(.tag_name),獲取大小(.size)
Test= browser.find_element_by_id('p') #選中了id為P的節點
Print(test.text)
7、延時等待(等待網頁加載出想要的內容,免得網速太慢跟不上節奏)
隱式等待(implicitly_wait())——如果沒有想要找的節點,等待固定長的一段時間,時間完了再查詢
from selenium import webdriver
browser=webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('https://www.zhihu.com/explore')
input=browser.find_element_by_class_name('zu-top-question')
print(input)
隱式等待5秒,五秒後沒找到報錯
顯式等待——指定最長時間,該時間內找到就返回值,到了最長時間仍沒有找到就報錯
程式碼略
8、前進和後退
訪問多個網頁時,使用back()方法後退,forward()方法前進
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.zhihu.com')
browser.get('https://www.mi.com')
browser.get('http://www.taobao.com')
browser.back()
browser.forward()
9、對cookie操作
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies()) #獲取cookie值
browser.add_cookie({'name':'test','domain':'www.zhihu.com','value':'germey'}) #新增cookie
print(browser.get_cookies())
browser.delete_all_cookies() #刪除所有cookie
print(browser.get_cookies())
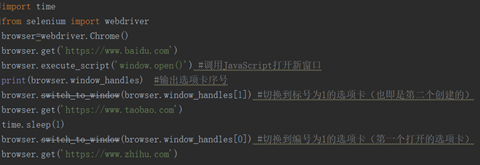
8、對選項卡進行操作
Ps:這篇文章主要是學習筆記,OneNote編寫過程中有自動首字母大寫,可能有大小寫錯誤。
筆記來源於書《Python3網路爬蟲開發實戰》,作者崔慶才,很不錯的一本書,侵刪