
ARM32/ARM64函式呼叫規則
COPY網址:https://community.arm.com/android-community/b/android/posts/arm-neon-programming-quick-reference
ARM NEON programming quick reference
1 Introduction
This article aims to introduce ARM NEON technology. Hope that beginners can get started with NEON programming quickly after reading the article. The article will also inform users which documents can be consulted if more detailed information is needed.
2 NEON overview
This section describes the NEON technology and supplies some background knowledge.
2.1 What is NEON?
NEON technology is an advanced SIMD (Single Instruction, Multiple Data) architecture for the ARM Cortex-A series processors. It can accelerate multimedia and signal processing algorithms such as video encoder/decoder, 2D/3D graphics, gaming, audio and speech processing, image processing, telephony, and sound.
NEON instructions perform "Packed SIMD" processing:
- Registers are considered as vectorsof elements of the samedata type
- Data types can be: signed/unsigned 8-bit, 16-bit, 32-bit, 64-bit, single-precision floating-point on ARM 32-bit platform, both single-precision floating-point and double-precision floating-point on ARM 64-bit platform.
- Instructions perform the sameoperationin all lanes
2.2 History of ARM Adv SIMD
|
ARMv6[i] SIMD extension |
ARMv7-A NEON |
ARMv8-A AArch64 NEON |
|
|
|
[i] The ARM Architecture Version 6 (ARMv6) David Brash: page 13
2.3 Why use NEON
NEON provides:
- Support for both integer and floating point operations ensures the adaptability of a broad range of applications, from codecs to High Performance Computing to 3D graphics.
- Tight coupling to the ARM processor provides a single instruction stream and a unified view of memory, presenting a single development platform target with a simpler tool flow[ii]
3 ARMv7/v8 comparison
ARMv8-A is a fundamental change to the ARM architecture. It supports the 64-bit Execution state called“AArch64”, and a new 64-bit instruction set “A64”. To provide compatibility with the ARMv7-A (32-bit architecture) instruction set, a 32-bit variant of ARMv8-A “AArch32” is provided. Most of existing ARMv7-A code can be run in the AArch32 execution state of ARMv8-A.
This section compares the NEON-related features of both the ARMv7-A and ARMv8-A architectures. In addition, general purpose ARM registers and ARM instructions, which are used often for NEON programming, will also be mentioned. However, the focus is still on the NEON technology.
3.1 Register
ARMv7-A and AArch32 have the same general purpose ARM registers – 16 x 32-bit general purpose ARM registers (R0-R15).
ARMv7-A and AArch32 have 32 x 64-bit NEON registers (D0-D31). These registers can also be viewed as 16x128-bit registers (Q0-Q15). Each of the Q0-Q15 registers maps to a pair of D registers, as shown in the following figure.
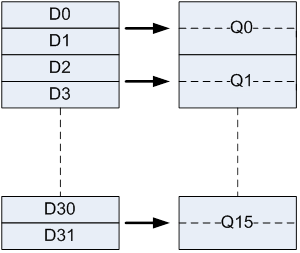
AArch64 by comparison, has 31 x 64-bit general purpose ARM registers and 1 special register having different names, depending on the context in which it is used. These registers can be viewed as either 31 x 64-bit registers (X0-X30) or as 31 x 32-bit registers (W0-W30).
AArch64 has 32 x 128-bit NEON registers (V0-V31). These registers can also be viewed as 32-bit Sn registers or 64-bit Dn registers.

3.2 Instruction set[iii]
The following figure illustrates the relationship between ARMv7-A, ARMv8-A AArch32 and ARMv8-A AArch64 instruction set.
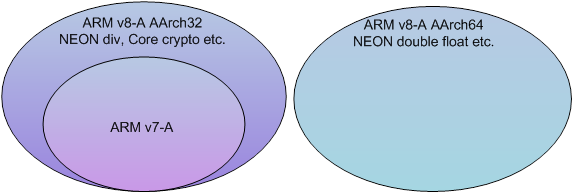
The ARMv8-A AArch32 instruction set consists of A32 (ARM instruction set, a 32-bit fixed length instruction set) and T32 (Thumb instruction set, a 16-bit fixed length instruction set; Thumb2 instruction set, 16 or 32-bit length instruction set). It is a superset of the ARMv7-A instruction set, so that it retains the backwards compatibility necessary to run existing software. There are some additions to A32 and T32 to maintain alignment with the A64 instruction set, including NEON division, and the Cryptographic Extension instructions. NEON double precision floating point (IEEE compliance) is also supported.
3.3 NEON instruction format
This section describes the changes to the NEON instruction syntax.
3.3.1 ARMv7-A/AArch32 instruction syntax[iv]
All mnemonics for ARMv7-A/AAArch32 NEON instructions (as with VFP) begin with the letter “V”. Instructions are generally able to operate on different data types, with this being specified in the instruction encoding. The size is indicated with a suffix to the instruction. The number of elements is indicated by the specified register size and data type of operation. Instructions have the following general format:
V{<mod>}<op>{<shape>}{<cond>}{.<dt>}{<dest>}, src1, src2
Where:
<mod> - modifiers
- Q: The instruction uses saturating arithmetic, so that the result is saturated within the range of the specified data type, such as VQABS, VQSHL etc.
- H: The instruction will halve the result. It does this by shifting right by one place (effectively a divide by two with truncation), such as VHADD, VHSUB.
- D: The instruction doubles the result, such as VQDMULL, VQDMLAL, VQDMLSL and VQ{R}DMULH
- R: The instruction will perform rounding on the result, equivalent to adding 0.5 to the result before truncating, such as VRHADD, VRSHR.
<op> - the operation (for example, ADD, SUB, MUL).
<shape> - Shape.
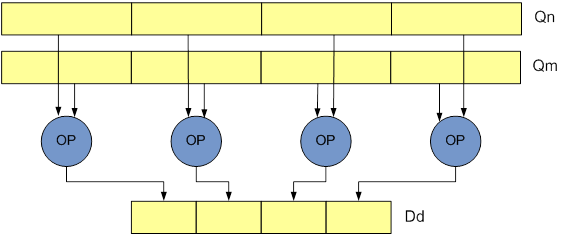
Neon data processing instructions are typically available in Normal, Long, Wide and Narrow variants.
- Long (L): instructions operate on double-word vector operands and produce a quad-word vector result. The result elements are twice the width of the operands, and of the same type. Lengthening instructions are specified using an L appended to the instruction.

- Wide (W): instructions operate on a double-word vector operand and a quad-word vector operand, producing a quad-word vector result. The result elements and the first operand are twice the width of the second operand elements. Widening instructions have a W appended to the instruction.
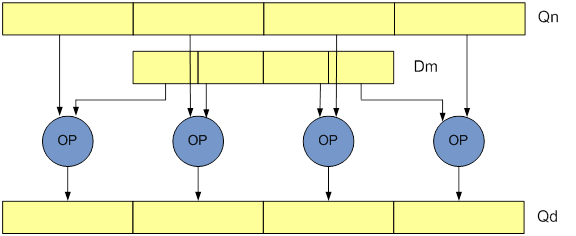
- Narrow (N): instructions operate on quad-word vector operands, and produce a double-word vector result. The result elements are half the width of the operand elements. Narrowing instructions are specified using an N appended to the instruction.
<cond> - Condition, used with IT instruction
<.dt> - Data type, such as s8, u8, f32 etc.
<dest> - Destination
<src1> - Source operand 1
<src2> - Source operand 2
Note: {} represents and optional parameter.
For example:
VADD.I8 D0, D1, D2
VMULL.S16 Q2, D8, D9
For more information, please refer to the documents listed in the Appendix.
3.3.2 AArch64 NEON instruction syntax[v]
In the AArch64 execution state, the syntax of NEON instruction has changed. It can be described as follows:
{<prefix>}<op>{<suffix>} Vd.<T>, Vn.<T>, Vm.<T>
Where:
<prefix> - prefix, such as using S/U/F/P to represent signed/unsigned/float/bool data type.
<op> – operation, such as ADD, AND etc.
<suffix> - suffix
- P: “pairwise” operations, such as ADDP.
- V: the new reduction (across-all-lanes) operations, such as FMAXV.
- 2:new widening/narrowing “second part” instructions, such as ADDHN2, SADDL2.
ADDHN2: add two 128-bit vectors and produce a 64-bit vector result which is stored as high 64-bit part of NEON register.
SADDL2: add two high 64-bit vectors of NEON register and produce a 128-bit vector result.
<T> - data type, 8B/16B/4H/8H/2S/4S/2D. B represents byte (8-bit). H represents half-word (16-bit). S represents word (32-bit). D represents a double-word (64-bit).
For example:
UADDLP V0.8H, V0.16B
FADD V0.4S, V0.4S, V0.4S
For more information, please refer to the documents listed in the Appendix.
3.4 NEON instructions[vi]
The following table compares the ARMv7-A, AArch32 and AArch64 NEON instruction set.
“√” indicates that the AArch32 NEON instruction has the same format as ARMv7-A NEON instruction.
“Y” indicates that the AArch64 NEON instruction has the same functionality as ARMv7-A NEON instructions, but the format is different. Please check the ARMv8-A ISA document.
If you are familiar with the ARMv7-A NEON instructions, there is a simple way to map the NEON instructions of ARMv7-A and AArch64. It is to check the NEON intrinsics document, so that you can find the AArch64 NEON instruction according to the intrinsics instruction.
New or changed functionality is highlighted.
|
ARMv7-A |
AArch32 |
AArch64 |
|
|
logical and compare |
VAND, VBIC, VEOR, VORN, and VORR (register) |
√ |
Y |
|
VBIC and VORR (immediate) |
√ |
Y |
|
|
VBIF, VBIT, and VBSL |
√ |
Y |
|
|
VMOV, VMVN (register) |
√ |
Y |
|
|
VACGE and VACGT |
√ |
Y |
|
|
VCEQ, VCGE, VCGT, VCLE, and VCLT |
√ |
Y |
|
|
VTST |
√ |
Y |
|
|
general data processing |
VCVT (between fixed-point or integer, and floating-point) |
√ |
Y |
|
VCVT (between half-precision and single-precision floating-point) |
√ |
Y |
|
|
n/a |
n/a |
FCVTXN(double to single-precision) |
|
|
VDUP |
√ |
Y |
|
|
VEXT |
√ |
Y |
|
|
VMOV, VMVN (immediate) |
√ |
Y |
|
|
VMOVL, V{Q}MOVN, VQMOVUN |
√ |
Y |
|
|
VREV |
√ |
Y |
|
|
VSWP |
√ |
n/a |
|
|
VTBL, VTBX |
√ |
Y |
|
|
VTRN |
√ |
TRN1, TRN2 |
|
|
VUZP, VZIP |
√ |
UZP1,UZP2, ZIP, ZIP2 |
|
|
n/a |
n/a |
INS |
|
|
n/a |
VRINTA, VRINM, VRINTN, VRINTP, VRINTR, VRINTX, VRINTZ |
FRINTA, FRINTI, FRINTM, FRINTN, FRINTP, FRINTX, FRINTZ |
|
|
shift |
VSHL, VQSHL, VQSHLU, and VSHLL (by immediate) |
√ |
Y |
|
V{Q}{R}SHL (by signed variable) |
√ |
Y |
|
|
V{R}SHR |
√ |
Y |
|
|
V{R}SHRN |
√ |
Y |
|
|
V{R}SRA |
√ |
Y |
|
|
VQ{R}SHR{U}N |
2018/10/03-函式呼叫約定、cdecl、stdcall、fastcall- 《惡意程式碼分析實戰》cdecl是最常用的約定之一,引數是從右到左按序被壓入棧,當函式完成時由呼叫者清理棧,並且將返回值儲存在EAX中。 stdcall約定是被呼叫函式負責清理棧,其他和cdecl非常類似。 fastcall呼叫約定跨編譯器時變化最多,但是它總體上在所有情況下的工作方式都是相似的。在fastcall 函式呼叫 壓棧的工作原理【轉】(轉自:https://blog.csdn.net/u011555996/article/details/70211315) 1.開篇 本篇文章著重寫的是系統中棧的工作原理,以及函式呼叫過程中棧幀的產生與釋放的過程,有可能名字過大,如果不合適我可以換一個名字,希望大家能夠指正,小丁虛心求 Python設定函式呼叫超時http://blog.sina.com.cn/s/blog_63041bb80102uy5o.html 背景: 最近寫的Python程式碼不知為何,總是執行到一半卡住不動,為了使程式能夠繼續執行,設定了函式呼叫超時機 C++函式呼叫方式(_stdcall, _pascal, _cdecl...)總結分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興! JS不同檔案間函式呼叫假設條件是:JS(A)要呼叫JS(B)的函式.那麼要滿足以下條件: 1.要保證你所呼叫的JS必須在同一個頁面裡. 也就是JS(A)和JS(B)都要在頁面X裡. 2.要保證你所呼叫的JS先於呼叫者本身被解釋.也就是JS(B)要先於JS(A)被解釋.反映在頁面上,就是JS(B)要寫到JS(A)的前面. 看開原始碼利器—用Graphviz + CodeViz生成C/C++函式呼叫圖(call graph)一、Graphviz + CodeViz簡單介紹 CodeViz是《Understanding The Linux Virtual Memory Manager》的作者 Mel Gorman 寫的一款分析C/C++原始碼中函式呼叫關係的open source工具(類似的ope C#VS中一個函式呼叫另一個函式的程式碼樣例//主函式 說明:下面的函式是想求許可證的十六位編號,最後一位是許可編號的校驗碼,是以本體碼("JY" + xukbh)為基礎來計算 entities[0].XuKeZhengBianHao = "JY" + xukbh + xukebianhaojiaoyanma(xukbh); |