
深度學習解決大規模文字分類問題
from https://zhuanlan.zhihu.com/p/25928551
(1)文字預處理
文字分詞
去停用詞
(2)文字表示和特徵提取
文字表示:
文字表示的目的是把文字預處理後的轉換成計算機可理解的方式,是決定文字分類質量最重要的部分。傳統做法常用詞袋模型(BOW, Bag Of Words)或向量空間模型(Vector Space Model),最大的不足是忽略文字上下文關係,每個詞之間彼此獨立,並且無法表徵語義資訊。詞袋模型的示例如下:
( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0)
一般來說詞庫量至少都是百萬級別,因此詞袋模型有個兩個最大的問題:高緯度、高稀疏性。詞袋模型是向量空間模型的基礎,因此向量空間模型通過特徵項選擇降低維度,通過特徵權重計算增加稠密性。
特徵提取:
向量空間模型的文字表示方法的特徵提取對應特徵項的選擇和特徵權重計算兩部分。特徵選擇的基本思路是根據某個評價指標獨立的對原始特徵項(詞項)進行評分排序,從中選擇得分最高的一些特徵項,過濾掉其餘的特徵項。常用的評價有文件頻率、互資訊、資訊增益、χ²統計量等。
特徵權重計算——TF-IDF方法。主要思路是一個詞的重要度與在類別內的詞頻成正比,與所有類別出現的次數成反比。
二、深度學習文字分類方法
2.1文字的分散式表示:詞向量(word
embedding)
文字的表示通過詞向量的表示方式,把文字資料從高緯度高稀疏的神經網路難處理的方式,變成了類似影象、語音的的連續稠密資料。深度學習演算法本身有很強的資料遷移性,很多之前在影象領域很適用的深度學習演算法比如CNN等也可以很好的遷移到文字領域了。
2.2
深度學習文字分類模型
1)fastText
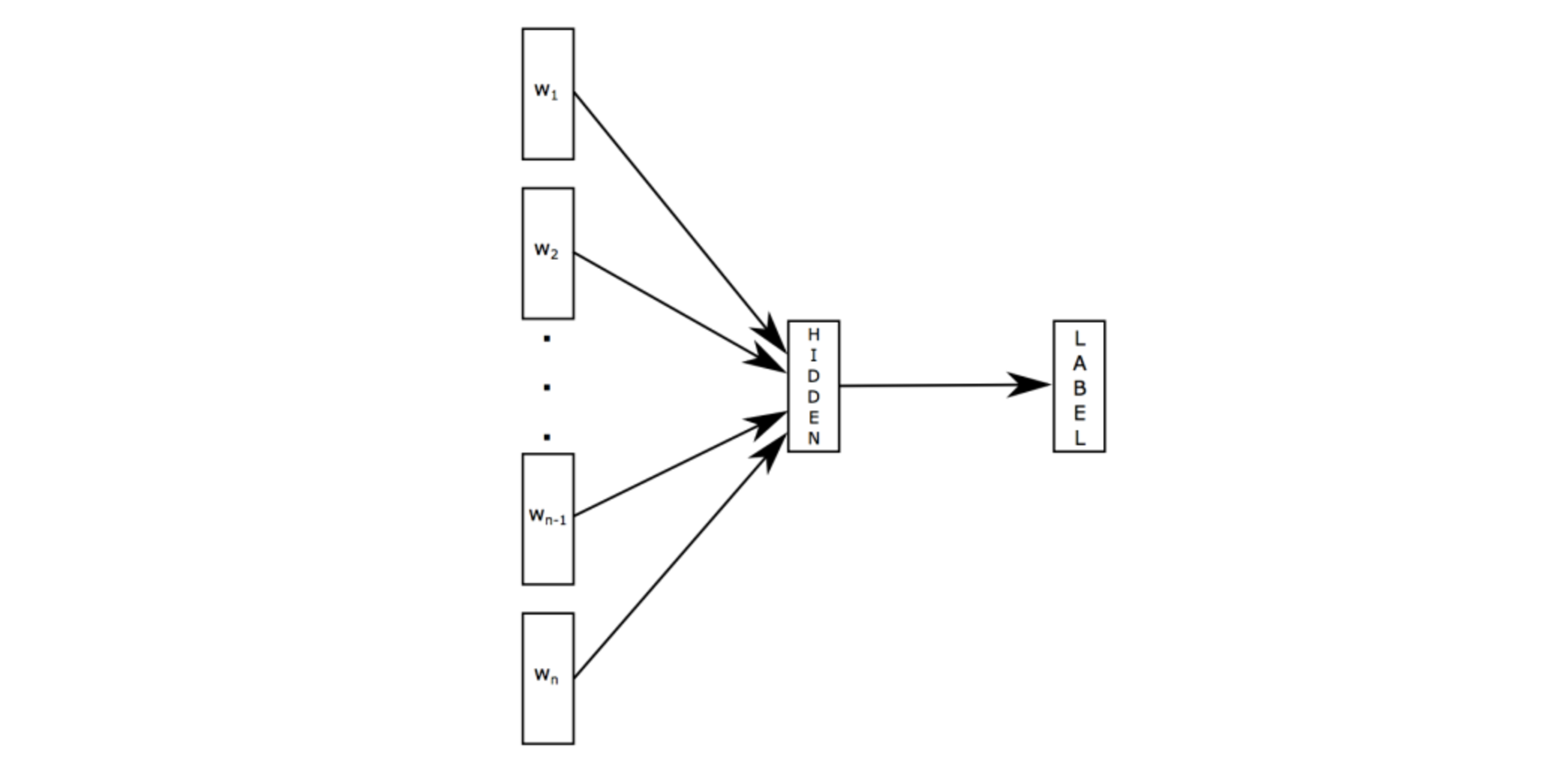
原理是把句子中所有的詞向量進行平均(某種意義上可以理解為只有一個avg pooling特殊CNN),然後直接接 softmax 層。其實文章也加入了一些 n-gram 特徵的 trick 來捕獲區域性序列資訊。文章倒沒太多資訊量,算是“水文”吧,帶來的思考是文字分類問題是有一些“線性”問題的部分[from項亮],也就是說不必做過多的非線性轉換、特徵組合即可捕獲很多分類資訊,因此有些任務即便簡單的模型便可以搞定了。
2)TextCNN
本篇文章的題圖選用的就是14年這篇文章提出的TextCNN的結構(見下圖)。fastText 中的網路結果是完全沒有考慮詞序資訊的,而它用的 n-gram 特徵 trick 恰恰說明了區域性序列資訊的重要意義。
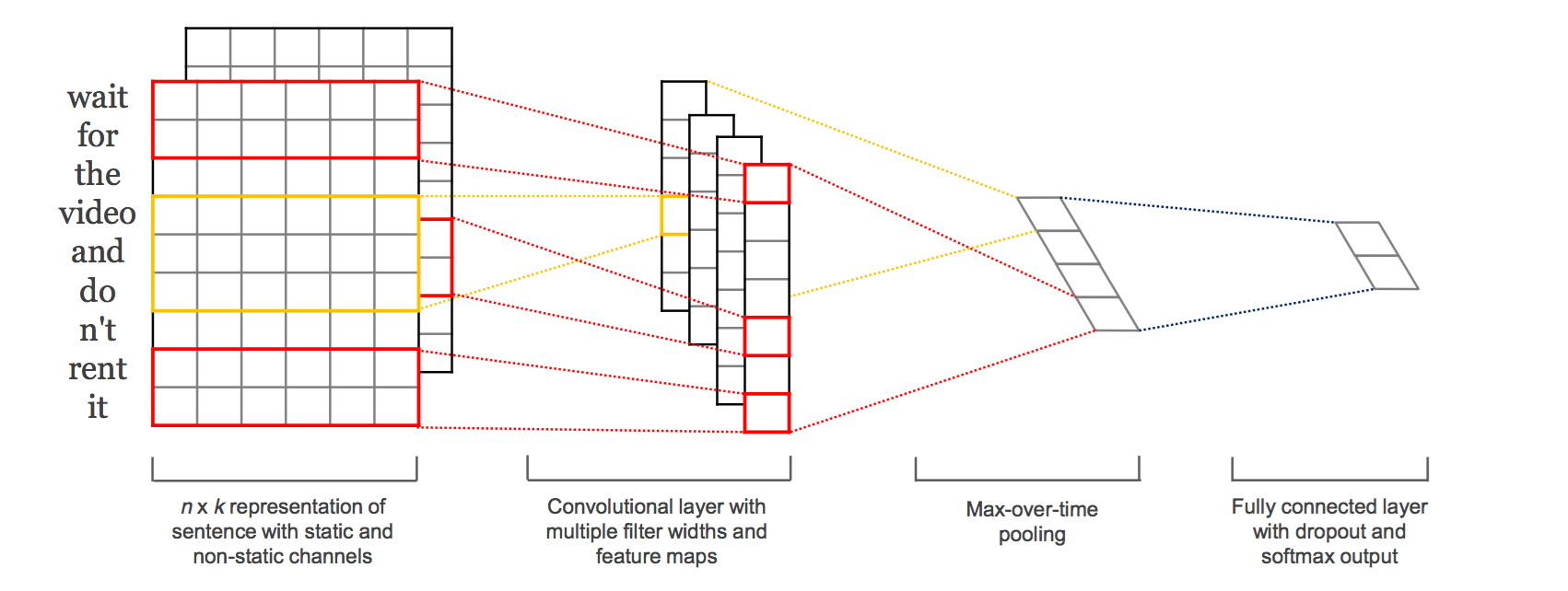
TextCNN的詳細過程原理圖見下:
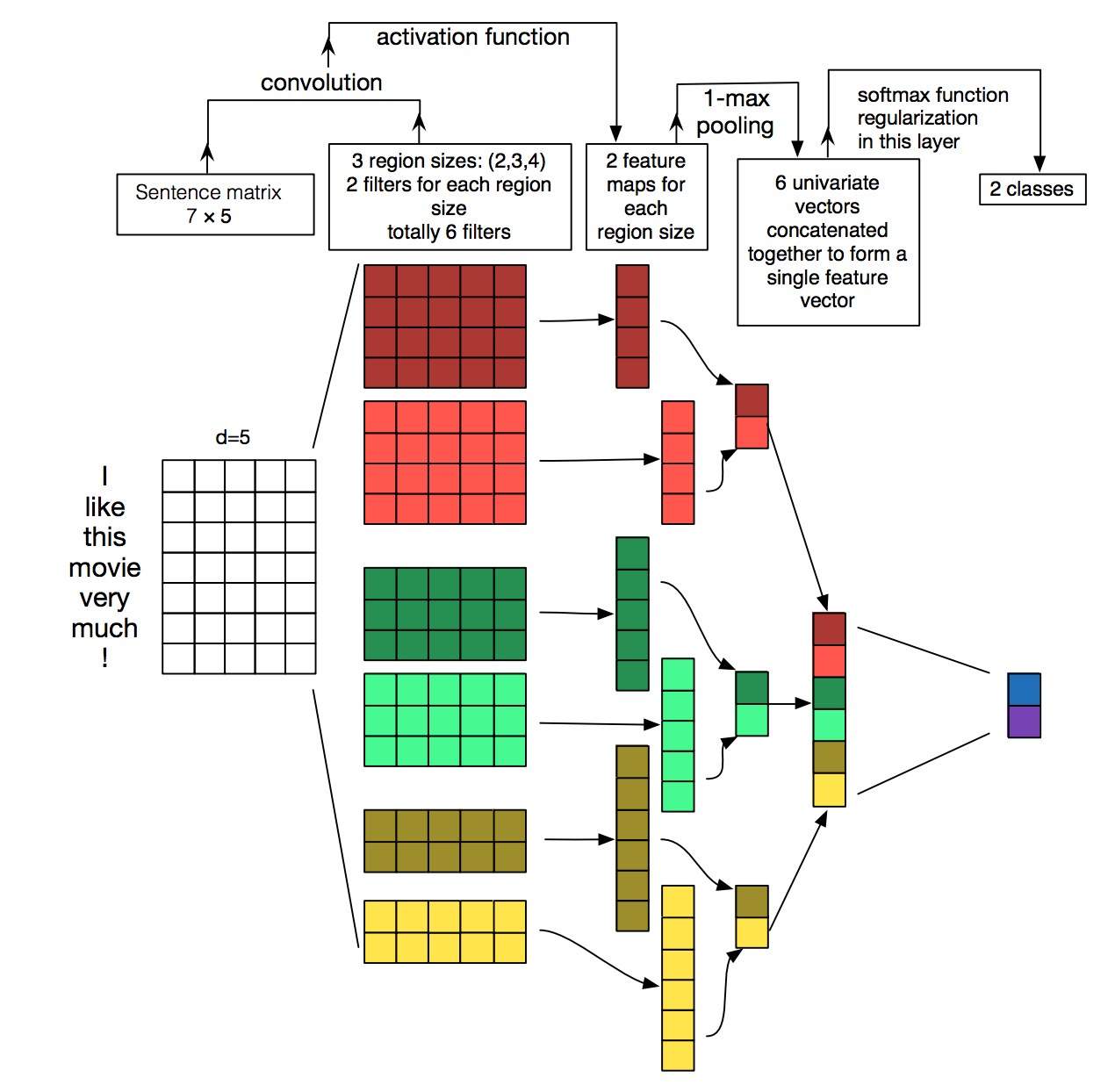
TextCNN詳細過程:第一層是圖中最左邊的7乘5的句子矩陣,每行是詞向量,維度=5,這個可以類比為影象中的原始畫素點了。然後經過有 filter_size=(2,3,4) 的一維卷積層,每個filter_size 有兩個輸出 channel。第三層是一個1-max pooling層,這樣不同長度句子經過pooling層之後都能變成定長的表示了,最後接一層全連線的 softmax 層,輸出每個類別的概率。
特徵:這裡的特徵就是詞向量,有靜態(static)和非靜態(non-static)方式。static方式採用比如word2vec預訓練的詞向量,訓練過程不更新詞向量,實質上屬於遷移學習了,特別是資料量比較小的情況下,採用靜態的詞向量往往效果不錯。non-static則是在訓練過程中更新詞向量。推薦的方式是 non-static 中的 fine-tunning方式,它是以預訓練(pre-train)的word2vec向量初始化詞向量,訓練過程中調整詞向量,能加速收斂,當然如果有充足的訓練資料和資源,直接隨機初始化詞向量效果也是可以的。
通道(Channels):影象中可以利用 (R, G, B) 作為不同channel,而文字的輸入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),實踐中也有利用靜態詞向量和fine-tunning詞向量作為不同channel的做法。
一維卷積(conv-1d):影象是二維資料,經過詞向量表達的文字為一維資料,因此在TextCNN卷積用的是一維卷積。一維卷積帶來的問題是需要設計通過不同 filter_size 的 filter 獲取不同寬度的視野。
Pooling層:利用CNN解決文字分類問題的文章還是很多的,比如這篇 A Convolutional Neural Network for Modelling Sentences 最有意思的輸入是在 pooling 改成 (dynamic) k-max pooling ,pooling階段保留 k 個最大的資訊,保留了全域性的序列資訊。比如在情感分析場景,舉個例子:
“ 我覺得這個地方景色還不錯,但是人也實在太多了 ”
雖然前半部分體現情感是正向的,全域性文字表達的是偏負面的情感,利用 k-max pooling能夠很好捕捉這類資訊。
以機器翻譯為例簡單介紹下,下圖中 是源語言的一個詞, 是目標語言的一個詞,機器翻譯的任務就是給定源序列得到目標序列。翻譯 的過程產生取決於上一個詞 和源語言的詞的表示 ( 的
bi-RNN 模型的表示),而每個詞所佔的權重是不一樣的。比如源語言是中文 “我 / 是 / 中國人” 目標語言 “i / am / Chinese”,翻譯出“Chinese”時候顯然取決於“中國人”,而與“我 / 是”基本無關。下圖公式, 則是翻譯英文第 個詞時,中文第 個詞的貢獻,也就是注意力。顯然在翻譯“Chinese”時,“中國人”的注意力值非常大。
Attention的核心point是在翻譯每個目標詞(或 預測商品標題文字所屬類別)所用的上下文是不同的,這樣的考慮顯然是更合理的。
加入Attention之後最大的好處自然是能夠直觀的解釋各個句子和詞對分類類別的重要性。
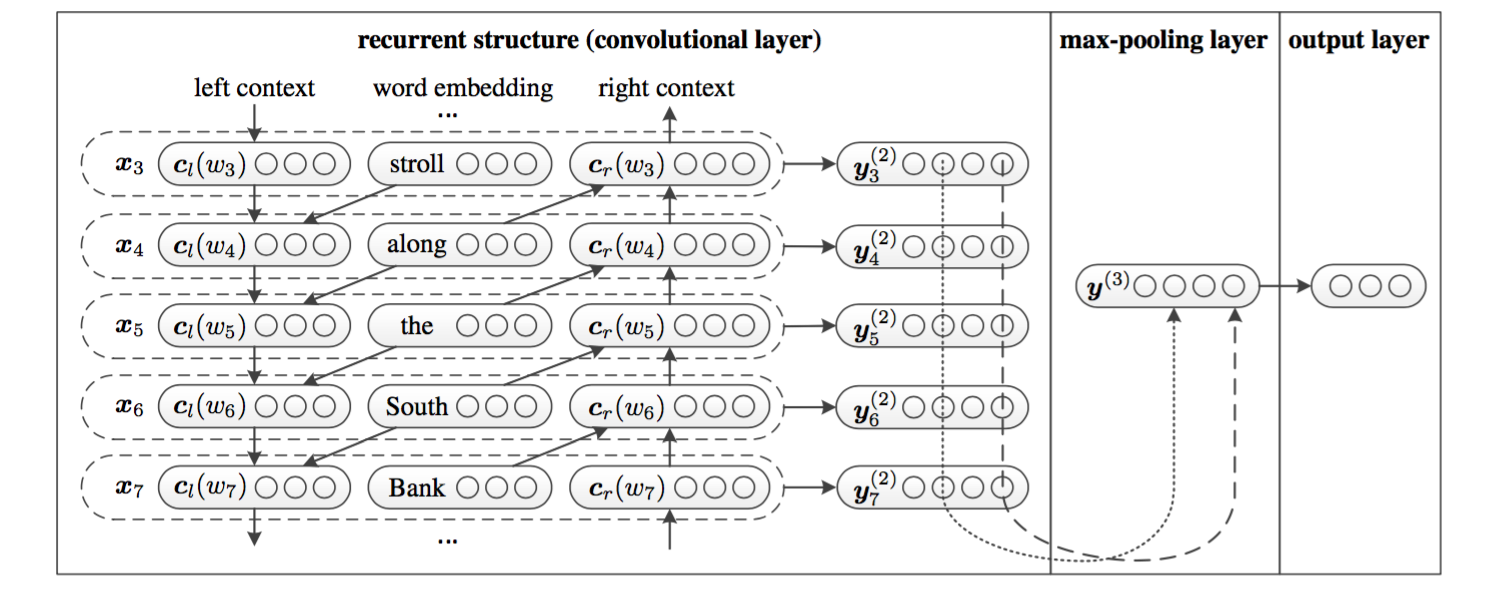
利用前向和後向RNN得到每個詞的前向和後向上下文的表示:
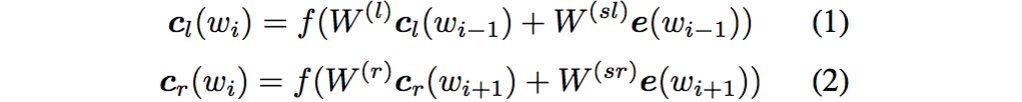
這樣詞的表示就變成詞向量和前向後向上下文向量concat起來的形式了,即:
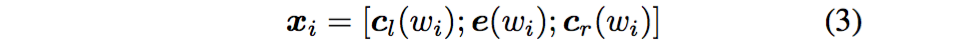
最後再接跟TextCNN相同卷積層,pooling層即可,唯一不同的是卷積層
filter_size = 1就可以了,不再需要更大 filter_size 獲得更大視野,這裡詞的表示也可以只用雙向RNN輸出。