
【hadoop】16、學習hive操作語句
學習DDL語句
建立物件的語句
Create/Drop/Alter Database
Create Database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT Alter Database
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES
(property_name=property_value, ...);
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;Use Database
USE database_name;
USE DEFAULT;
Hive執行的時候,元資料儲存在關係係數據庫裡面。
Hive執行的時候需要有對映關係的資料,需要快速地讀取
Linux裡面其實有自帶的關係資料庫,但是十分不穩定,所以我們不用這個資料庫

我們自己搭建一個關係資料庫
安裝一個關係資料庫(mysql)
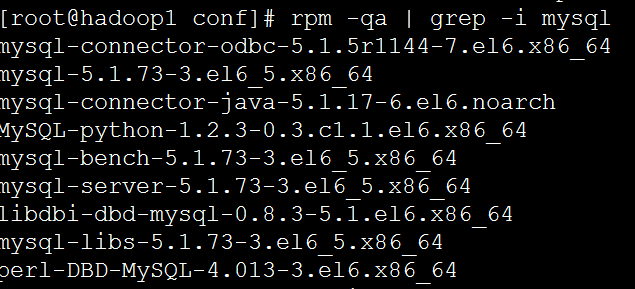
我們在安裝Linux的時候已經安裝了mysql
啟動mysql

檢視mysql是否已經進行監聽

3306埠,對的
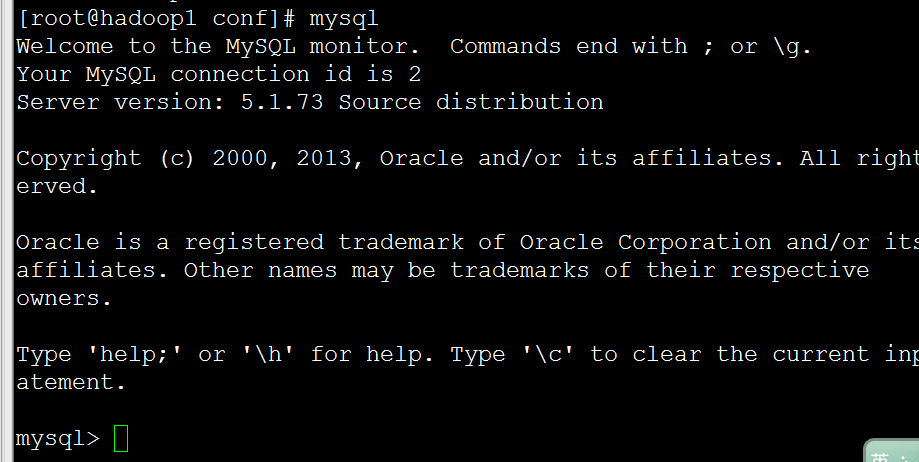
連線mysql
受限我們需要驅動


設定mysql中遠端登入的問題
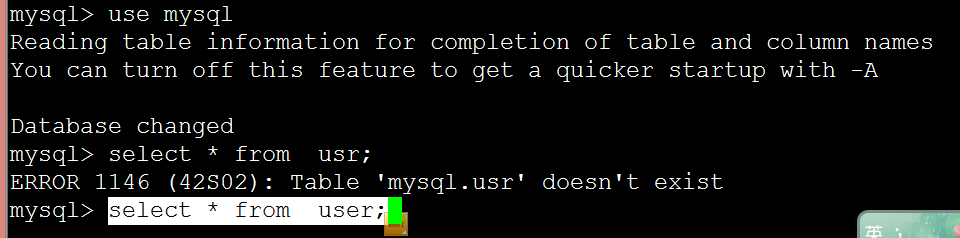
輸入use mysql
select * from user;
grant all on . to [email protected]’%’ identified by ‘123456’;
這個是給所有的使用者在所有的資料庫上的所有的表的所有許可權,密碼是123456

檢視一下是否成功



修改配置檔案

配置mysql路徑


修改使用者名稱和密碼
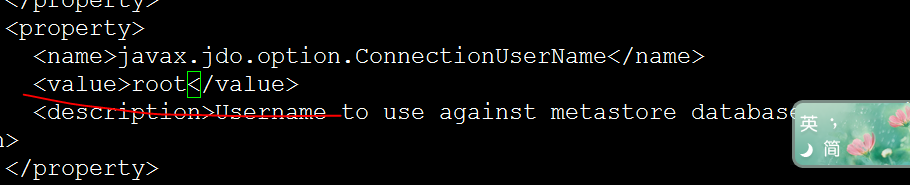


我們建立一個hive的資料庫

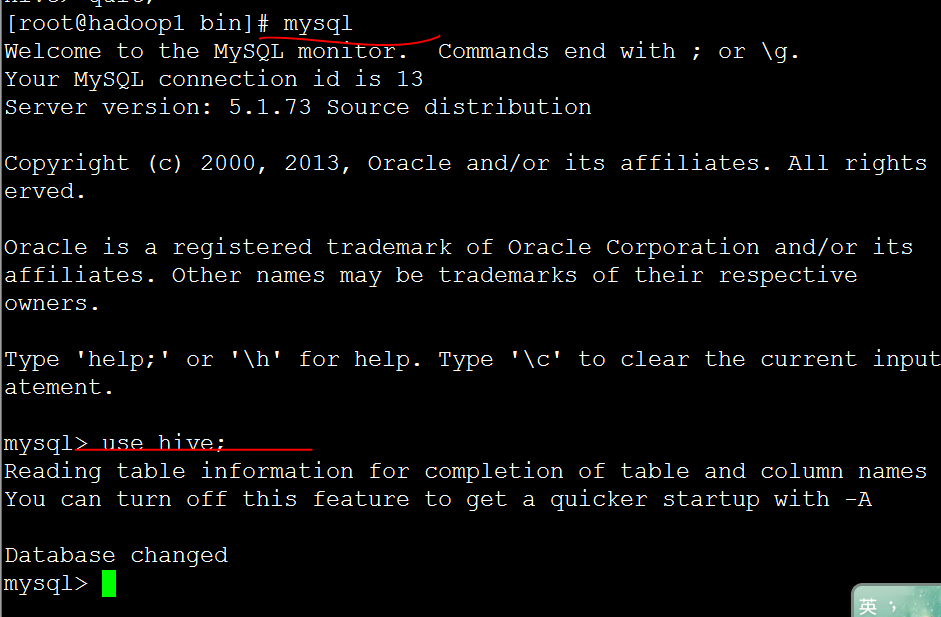
進入hive

啟動之後推出hive
Quite;
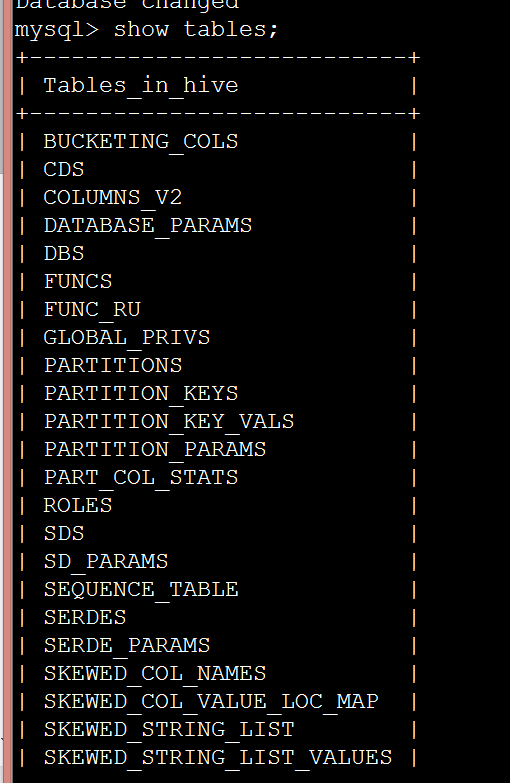
然後在mysql中查看錶
退出
學習hive的DDL語句
Create Table
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname例子:
id int,
date date,
name varchar
create table table_name
(
id int,
dtDontQuery string,
name string
)
partitioned by (date string)一個例子
CREATE TABLE page_view
(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING COMMENT 'IP Address of the User'
)
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001' 這個是分隔符,行的每一列用什麼分割
STORED AS SEQUENCEFILE;我們建立一張表
在hive中
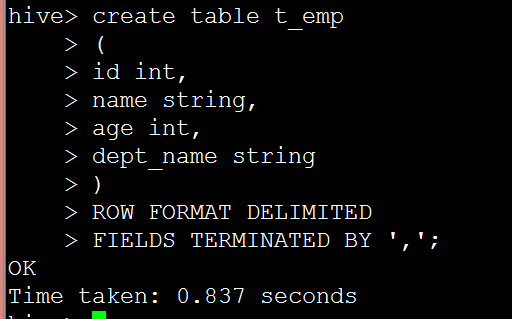
create table t_emp
(
id int,
name string,
age int,
dept_name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';我們在Linux中建立一個文字的資料檔案
Emp.txt
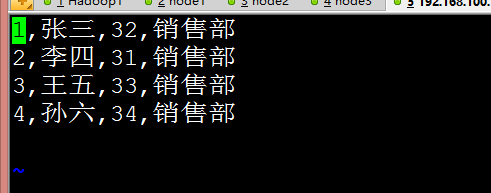
匯入資料
Loading files into tables
Hive does not do any transformation while loading data into tables. Load operations are currently pure copy/move operations that move datafiles into locations corresponding to Hive tables.
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)]

Hive通過我們的環境變數找到hadoop在哪,然後連上hadoop,就會建立hive的工作目錄在hdfs上,在user下的hive下
我們查詢,在hive下面
select count(*) from t_emp;
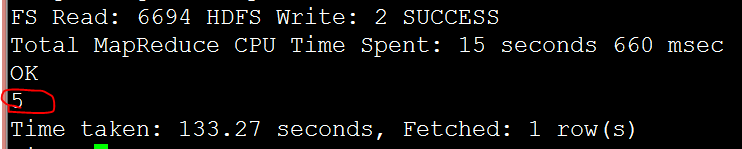
Hive還可以使用各種集合型別
create table t_person
(
id int,
name string,
like array<string>,
tedian map<string, string>
)
row format delimited
fields terminated by ','
collection items terminated by '_'
map keys terminated by ':';資料格式
1,,zhangsan,sports_books_TV,sex:男_color:red
載入檔案
Load data local inpath ‘root/data.exe’ into table t_person
Hive在執行的時候有一些元資料需要儲存。預設保持到DBMS。
學習DML語句
匯入資料
Loading files into tables
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]建立分割槽表
分割槽實際是一個資料夾,表名就是資料夾名。每個分割槽,實際上是表名這個資料夾下面的不同檔案。分割槽可以根據時間,地點等等進行分割槽,比如,每天一個分割槽,等於每天存每天的資料,或者每個城市,存放每個城市的資料。每次查詢資料的時候,只要寫下類似where pt=2010_08_23這樣的條件即可查詢指定時間的資料
Create table sxtstu(id int, sname string, city string)
Partitioned by (ds string) row format delimited fields terminated by ‘,’ stored as textfile;
我們儲存資料的時候
Load data local inpath ‘sxtstu.txt’ overwrite into table sxtstu partition(ds=’2013-07-09’);
Copying data from file:/home/Hadoop/sxtstu.txt
Copying file:file:/home/Hadoop/sxtstu.txt
Loading data to table default.sxtstu partition (ds=2013-07-09)
OK
我們嘗試建立一張表
create table dept_count(
dname string,
num int)
;
insert into table dept_count select dept_name, count(1) from t_emp group by dept_name;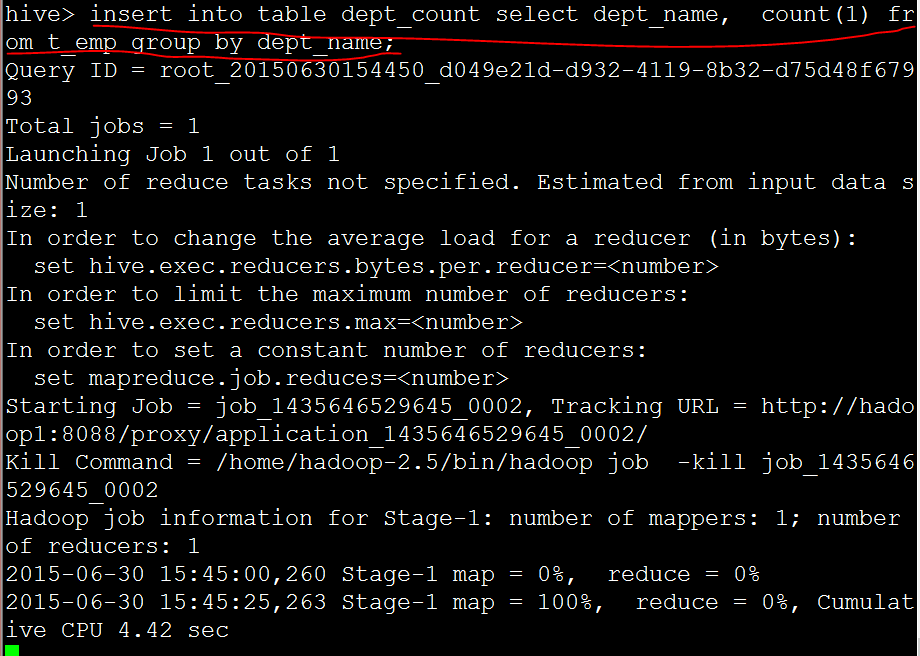

關於分割槽:
Create table dept_count
(
Num int
)
Partitioned by (dname string);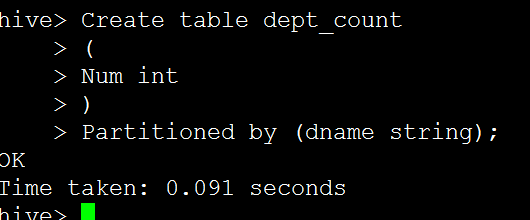
Insert into table dept_count
partition (dname='銷售部')
select count(1)
from t_emp
where dept_name='銷售部'
group by dept_name一些案例:
CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2))
CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC;
INSERT INTO TABLE students
VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
CREATE TABLE pageviews (userid VARCHAR(64), link STRING, came_from STRING)
PARTITIONED BY (datestamp STRING) CLUSTERED BY (userid) INTO 256 BUCKETS STORED AS ORC;
INSERT INTO TABLE pageviews PARTITION (datestamp = '2014-09-23')
VALUES ('jsmith', 'mail.com', 'sports.com'), ('jdoe', 'mail.com', null);
INSERT INTO TABLE pageviews PARTITION (datestamp)
VALUES ('tjohnson', 'sports.com', 'finance.com', '2014-09-23'), ('tlee', 'finance.com', null, '2014-09-21');關於import和export
EXPORT TABLE tablename [PARTITION (part_column="value"[, ...])]
TO 'export_target_path'
IMPORT [[EXTERNAL] TABLE new_or_original_tablename [PARTITION (part_column="value"[, ...])]]
FROM 'source_path'
[LOCATION 'import_target_path']匯出語句
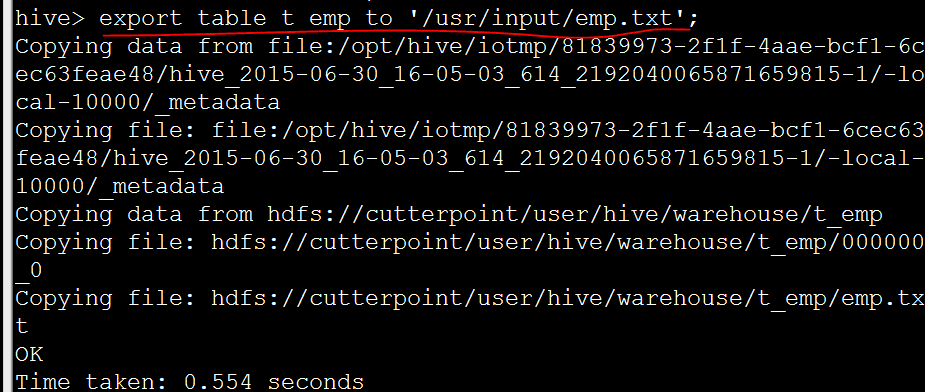
學習資料查詢語句
類似SQL語句
create table t_stu
(
userid int,
name string,
age int,
sex int,
classid int
)
row format delimited fields terminated by ','
stored as textfile;
create table t_class
(
cid int,
name string,
teacher string
)
row format delimited fields terminated by ','
stored as textfile;
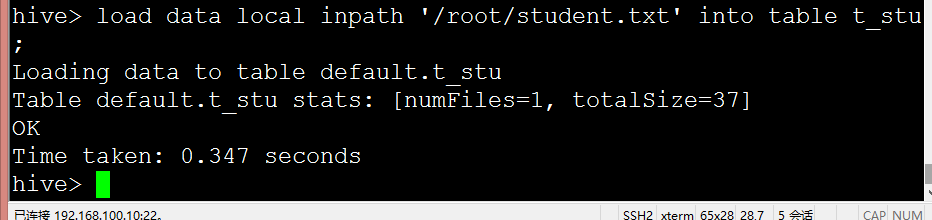
load data inpath '/pub/student.txt' into table t_stu;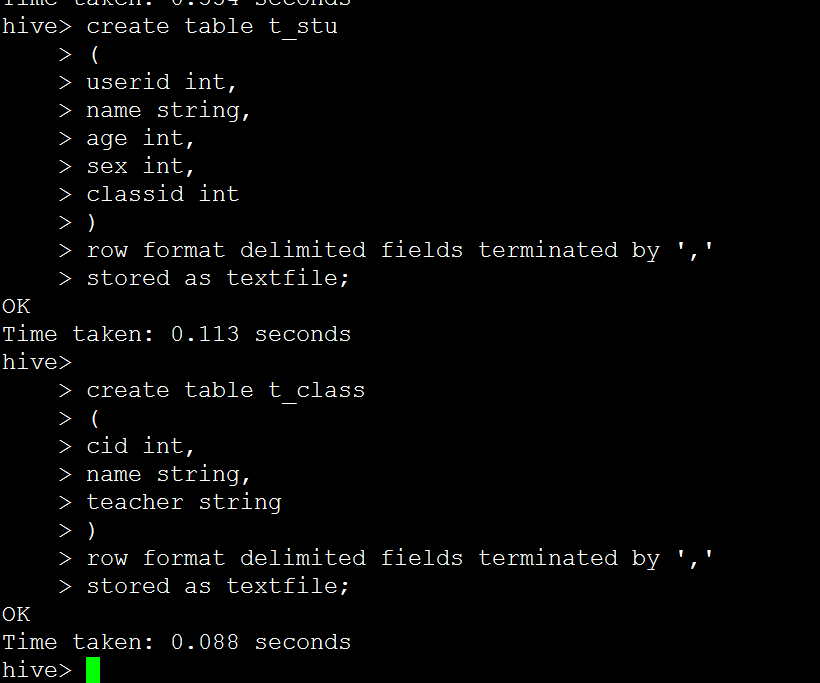
1,zs,32,2,2
2,lis,23,1,2
3,ww,21,1,1
select s.*, c.name from t_stu s join t_class c on s.classid=c.cid;
相關推薦
【hadoop】16、學習hive操作語句
學習DDL語句 建立物件的語句 Create/Drop/Alter Database Create Database CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMEN
【Spring】16、註解事務 @Transactional
引用 相關 連接池 每次 one 作用 事務性 簡單 這一 概述 事務管理對於企業應用來說是至關重要的,即使出現異常情況,它也可以保證數據的一致性。Spring Framework對事務管理提供了一致的抽象,其特點如下: 為不同的事務API提供一致的編程模型,
【hadoop】1、MapReduce進行日誌分析,並排序統計結果
1.網上很多關於搭建Hadoop叢集的知識,這裡不多做敘述,並且本機執行Hadoop程式是不需要hdfs叢集的,我們本機執行只做個demo樣式,當真的需要執行大資料的時候,才需要真正的叢集 2.還有就是詞頻統計的知識,不論是官方文件,還是網上的知識,基本都能隨意百度個幾百篇出來 但是我找半天,確實是沒有找
【Hadoop】HBase框架學習之路
1 背景知識 1.1 解決問題 解決HDFS不支援單條記錄的快速查詢和更新的問題。 1.2 適用情況 存在億萬條記錄的資料庫,只有千萬或者百萬條記錄使用RDBMS更加合適 確保你的應用不需要使用RDBMS的高階特性(第二索引,事務機制,
【Hadoop】6、Hadoop安裝之報錯處理
錯誤報錯 1、時間不能同步 2014.12.18 做同步時間的時候,執行命令操作: [[email protected] ~]# /usr/sbin/ntpdate pool.ntp.org 會報錯: Name server
【Hadoop】HBase、HDFS和MapReduce架構異同簡解
HBase、HDFS和MapReduce架構異同 .. HBase(公司架構模型) HDFS2.0(公司架構模型) MR2.0(公司架構模型) MR1.0(公司架構模型)
【Python+OpenCV入門學習】七、軌跡條操作
本篇文章,將學習如何進行軌跡條操作。主要學習函式getTrackbarPos()和createTrackbar()使用。 環境:Windows 7(64) python 3.6 opencv 3.4.2 一、瞭解函式 軌跡條使用起來非常的方便,通過滑鼠滑動軌跡
【QT】QT的學習:qml中使用listmode、listview實現選項的變換操作,類似qwidget中listwidget的作用。
(1)方法一:點選某一選項,某一個選項的顏色就立即會發生變化 ListView { id : m_listView anchors.fill: parent anchors.margins: 20 clip: true model: ["A","B","C","D","E"
【算法設計與分析基礎】16、高斯消元法
ane sys cnblogs 根據 gauss tostring logs junit air package cn.xf.algorithm.ch06ChangeRule; import java.util.ArrayList; import java.util.L
【作業】條件、循環、函數定義、字符串操作練習
同心圓 print com alt while imp val orm format 一、註意標準庫的兩種導入與使用方式,建議大家采用<庫名>.<函數名>的方式。 二、對前面的代碼進行優化,用for,while,if,def實現: 1、用循環畫五角星
【劍指offer】16、數值的整數次方
urn bsp unsigned info 直接 signed http 指數 ret 題目 實現double Power(double base, int exponent),求base的exponent次方,不得使用庫函數,同樣需要考慮大數問題。 思路 題目意思很清楚,
【hadoop】hive 安裝實踐
1.下載Hive安裝包: 官網下載:http://hive.apache.org/downloads.html 2.上傳Hive的tar包,並解壓:建議和hadoop目錄在一級,方便後續使用; 解壓:tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /home/
【足跡C++primer】38、關聯容器操作(2)
關聯容器操作(2) map的下標操作 map的下標操作 map和unordered_map容器提供了下標運算符合一個相應的at函式 對於一個map使用下標操作,其行為與陣列或vector上的下標操作非常不同樣: 使用一個不再容器中的keywo
【Redis】一、簡單介紹及操作
一、什麼是Redis Redis 是一個高效能的開源的、C語言寫的Nosql(非關係型資料庫),資料儲存在記憶體中。 Redis 是以key-value形式儲存,和傳統的關係型資料庫不一樣。不一定遵循傳統資料庫的一些基本要求,比如說,不遵循sql標準,事務,表結構等等,非關係型資料庫嚴格
【springboot】4、SpringBoot+Mybatis多表操作以及增刪改查
Mybatis整合成功之後,接下來了解一下增刪改查的配置以及多表操作,先從增刪改查開始 為了方便後面的多表操作,現在針對資料表的配置我這裡全部在xml中配置(暫時不用註解的方式了),先看一下目前的工程結構(注意包名) 首先為了瞭解增刪改查的操作,我這裡將針對資料庫中的一個文
【QT】QT的學習:char×跟QString、string之間的轉換
(1)QString轉成char*或者char陣列。 QString data; QByteArray tempData = data.toLocal8Bit(); char *value = (ch
【TDH】Kafka、Flume、Slipstream基本操作
【Kafka操作:在${KAFKA_HOME}/bin下執行Kafka操作】 1、在星環TDH叢集上操作Kafka的時候首先要進行相關的賦權操作 (1)賦予當前使用者(當前使用者以hive為例,可以使用kinit進行使用者的切換)操作叢集的許可權 ./kafka-acls.sh --
【SQL注入技巧拓展】————16、繞過WAF注入
正文開始: 找到一個有裝有安全狗的站: 繞過攔截and 1=1: payload: id=1/*!and*/1=/*!1*/ 即可繞過。 通常order by 不會被攔截,攔截了繞過道理差不
【JavaScript高階】16、執行緒機制與事件機制筆記
執行緒與程序 程序: 程式的一次執行, 它佔有一片獨有的記憶體空間 可以通過windows工作管理員檢視程序 執行緒: 是程序內的一個獨立執行單元 是程式執行的一個完整流程 是CPU的最小的排
【hadoop】MapReduce工作流程和MapTask、Shuffle、ReduceTask工作機制
MapReduce整個工作流程:一、MapTask階段(1)Read階段:MapTask通過使用者編寫的RecordReader,從輸入InputSplit中解析出一個個key/value。(2)Map階段:該節點主要是將解析出的key/value交給使用者編寫map()函式