
Hive通過查詢語句向表中插入資料過程中發現的坑
前言
最近在學習使用Hive(版本0.13.1)的過程中,發現了一些坑,它們或許是Hive提倡的比關係資料庫更加自由的體現(同時引來一些問題),或許是一些bug。總而言之,這些都需要使用Hive的開發人員額外注意。本文旨在列舉我發現的3個通過查詢語句向表中插入資料過程中的問題,希望大家注意。
資料準備
為了驗證接下來出現的問題,需要先準備兩張表employees和staged_employees,並準備好測試資料。首先使用以下語句建立表employees:
create table employees ( id int comment 'id', name string comment 'name') partitioned by (country string, state string) row format delimited fields terminated by ',';
employees的結構比較簡單,有id、name、country、state四個欄位,其中country和state都是分割槽欄位。特別需要提醒的是這裡顯示的給行格式指定了欄位分隔符為逗號,因為預設的欄位分隔符\001不便於筆者準備資料。然後建立表staged_employees:
create table staged_employees (
id int comment 'id',
user_name string comment 'user name')
partitioned by (cnty string, st string);staged_employees也有4個欄位,除了欄位名不同之外,和employees的4個欄位的含義是相同的。
我們首先使用以下語句給employees的country等於US,state等於CA的分割槽載入一些資料:
load data local inpath '${env:HOME}/test.txt'
into table employees
partition (country = 'US', state = 'CA');再給employees的country等於CN,state等於BJ的分割槽載入一些資料:
以上語句的執行過程如圖1所示。load data local inpath '${env:HOME}/test2.txt' overwrite into table employees partition (country = 'CN', state = 'BJ');
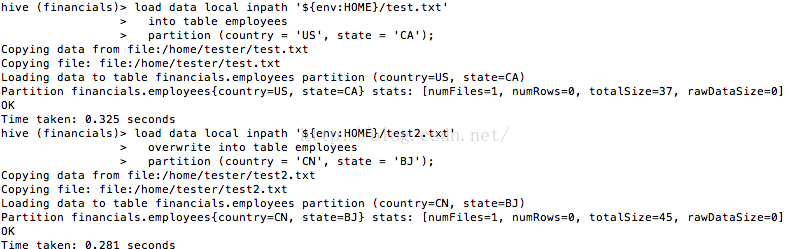
圖1給employees載入資料
最後我們看看employees中準備好的資料,如圖2所示。

圖2 employees中準備好的資料
INSERT OVERWRITE的歧義
由於staged_employees中還沒有資料,所以我們查詢employees的資料,並插入staged_employees中:
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select * from employees e
where e.country = 'US' and e.state = 'CA';
FAILED: SemanticException [Error 10044]: Line 1:23 Cannot insert into target table because column number/types are different ''CA'': Table insclause-0 has 2 columns, but query has 4 columns.insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name from employees e
where e.country = 'US' and e.state = 'CA';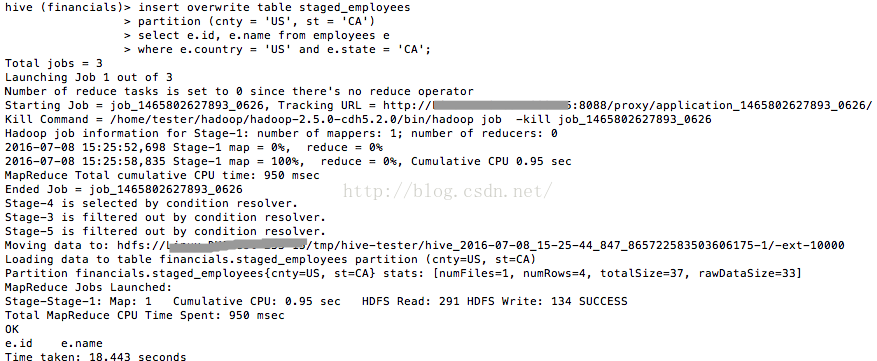
圖4正確執行insert overwrite
我們看看staged_employees表中,現在有哪些資料(如圖5所示):

圖5 staged_employees中的資料
熟悉MySQL等關係型資料庫的同學可能要格外注意此問題了!
FROM ... INSERT ... SELECT的歧義
本節正式開始之前,向employees表中再載入一些資料:
load data local inpath '${env:HOME}/test3.txt'
into table employees
partition (country = 'CA', state = 'ML');
圖6載入新的資料
這時表employees的資料如圖7所示。
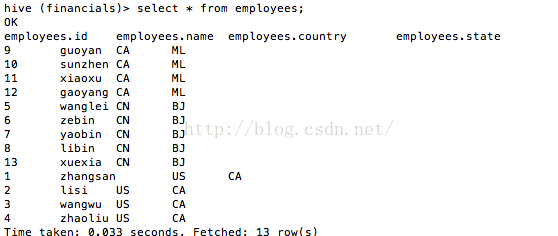
圖7
Hive提供了一種特別的INSERT語法,我們不妨先看看其使用方式,sql如下:
from employees e
insert into table staged_employees
partition (cnty = 'CA', st = 'ML')
select * where e.country = 'CA' and e.state = 'ML';
圖8 SemanticException [Error 10044]
可以看到這裡再次出現了之前提到的問題,我們依然按照之前的方式進行修改,sql如下:
from employees e
insert into table staged_employees
partition (cnty = 'CA', st = 'ML')
select e.id, e.name where e.country = 'CA' and e.state = 'ML';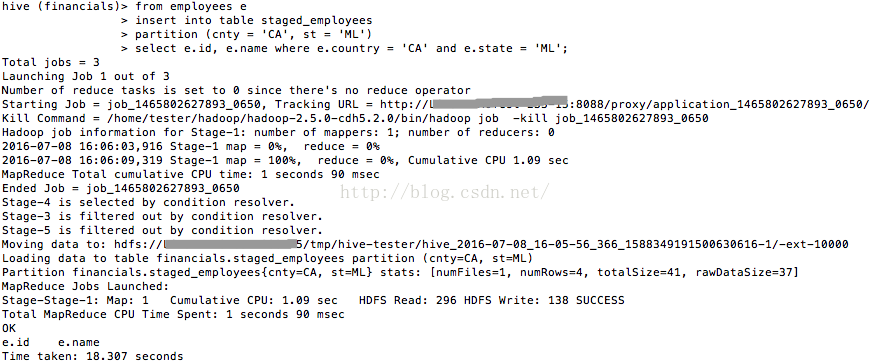
圖9
現在來看看staged_employees中的資料(如圖10所示),看來的確將分割槽資料插入了。
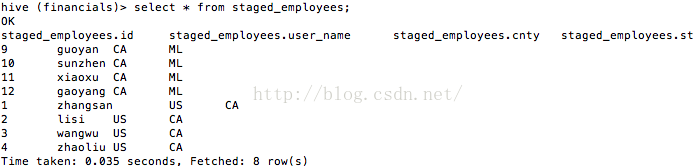
圖10 staged_employees中的資料
FROM ... INSERT ... SELECT存在bug
我們繼續使用FROM ... INSERT ... SELECT語法向staged_employees中插入資料,sql如下:from employees e
insert into table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA';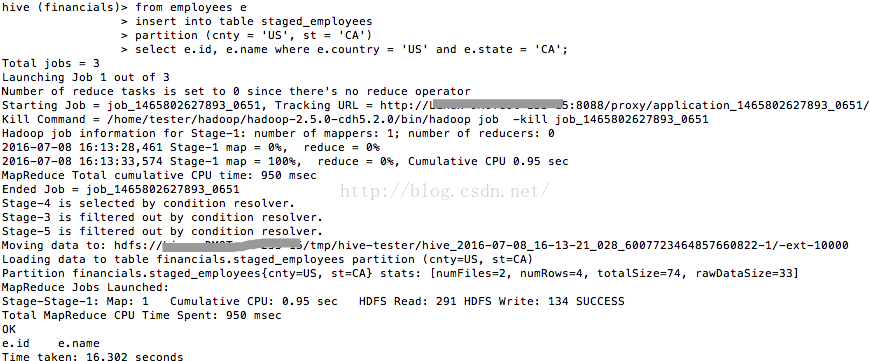
圖11
我們看看這時staged_employees中的資料,如圖12所示。
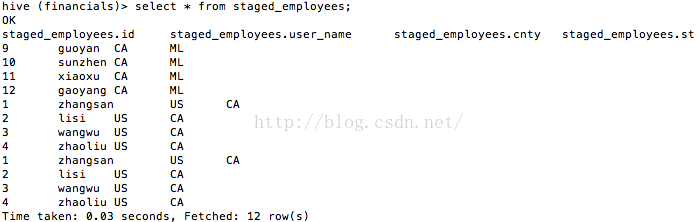
圖12
的確印證了,INSERT INTO是用於追加的。
我們將sql進行調整,即將INSERT INTO改為INSERT OVERWRITE:
from employees e
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA';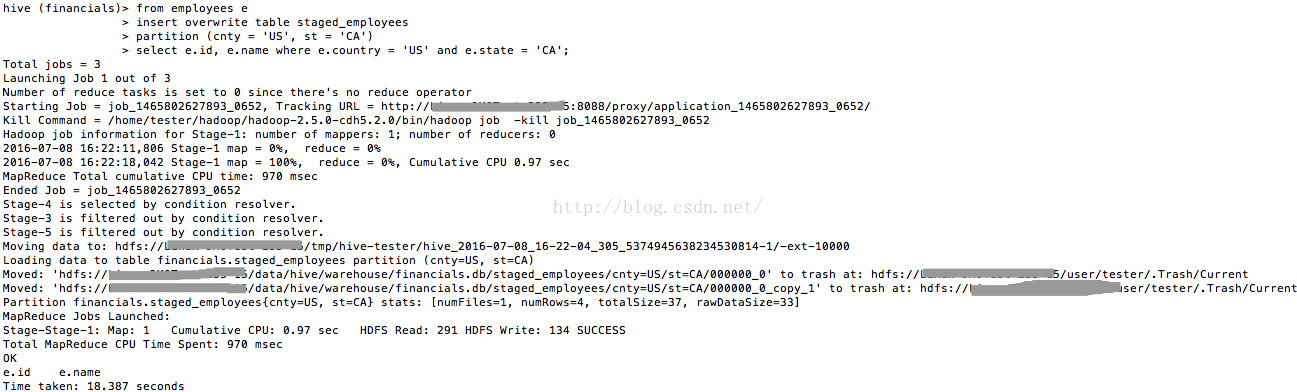
圖13
我們看看這時staged_employees中的資料,如圖14所示。

圖14
這說明INSERT OVERWRITE是用於覆蓋的。
根據官方文件說明,這種FROM ... INSERT ... SELECT語法中的INSERT ... SELECT是可以有多個的,於是我編寫以下sql,用來向表staged_employees中覆蓋“country等於CA,state等於ML”分割槽的資料,並且覆蓋“country等於US,state等於CA”分割槽的資料。
from employees e
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA'
insert overwrite table staged_employees
partition (cnty = 'CA', st = 'ML')
select e.id, e.name where e.country = 'CA' and e.state = 'ML';執行以上sql的過程如圖15所示。
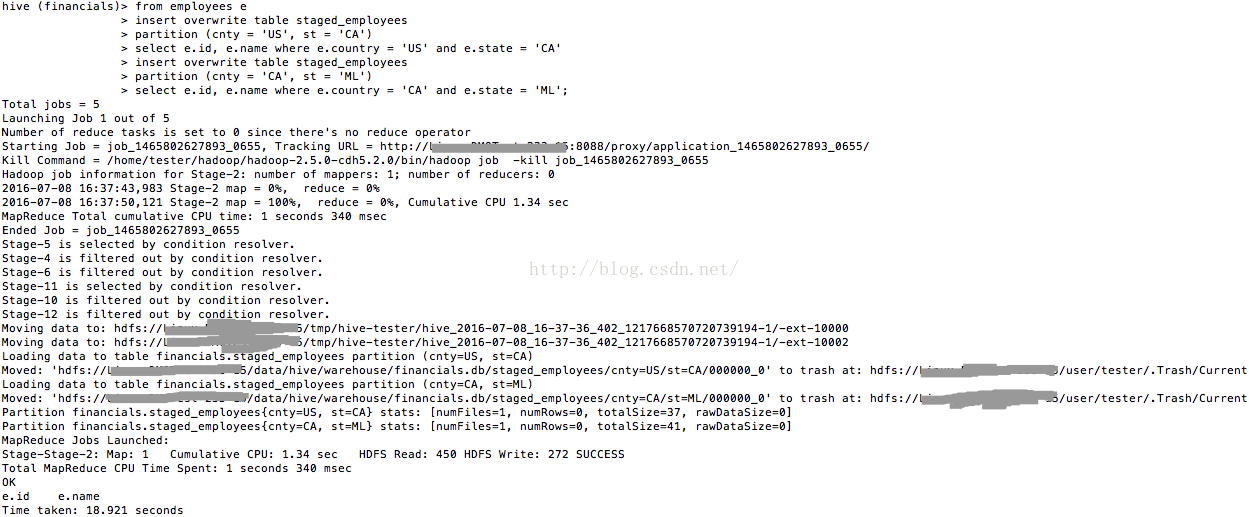
圖15
由於都是覆蓋更新,所以staged_employees中的資料並未發生改變。
根據官方文件,以上sql中還可以將INSERT OVERWRITE和INSERT INTO進行混用,sql如下:
from employees e
insert overwrite table staged_employees
partition (cnty = 'US', st = 'CA')
select e.id, e.name where e.country = 'US' and e.state = 'CA'
insert into table staged_employees
partition (cnty = 'CN', st = 'BJ')
select e.id, e.name where e.country = 'CN' and e.state = 'BJ';這段sql將覆蓋“country等於US,state等於CA”分割槽的資料,並且追加“country等於CN,state等於BJ”分割槽的資料。執行這段sql的過程如圖16所示。

圖16
最後,我們來看看staged_employees中的資料,如圖17所示。
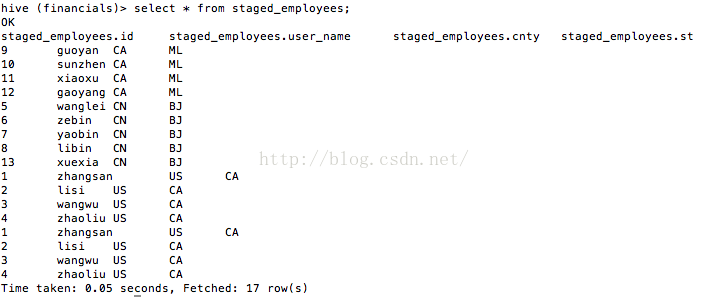
圖17
從圖17中看到,“country等於CN,state等於BJ”分割槽的資料如我們所願追加到表staged_employees中了。“country等於US,state等於CA”分割槽的資料並沒有被覆蓋,而是追加。這很明顯是一個bug,希望大家注意!
後記:個人總結整理的《深入理解Spark:核心思想與原始碼分析》一書現在已經正式出版上市,目前京東、噹噹、天貓等網站均有銷售,歡迎感興趣的同學購買。
