
深入HBase架構解析(一)
前記
公司內部使用的是MapR版本的Hadoop生態系統,因而從MapR的官網看到了這篇文文章:An In-Depth Look at the HBase Architecture,原本想翻譯全文,然而如果翻譯就需要各種咬文嚼字,太麻煩,因而本文大部分使用了自己的語言,並且加入了其他資源的參考理解以及本人自己讀原始碼時對其的理解,屬於半翻譯、半原創吧。
HBase架構組成
HBase採用Master/Slave架構搭建叢集,它隸屬於Hadoop生態系統,由一下型別節點組成:HMaster節點、HRegionServer節點、ZooKeeper叢集,而在底層,它將資料儲存於HDFS中,因而涉及到HDFS的NameNode、DataNode等,總體結構如下: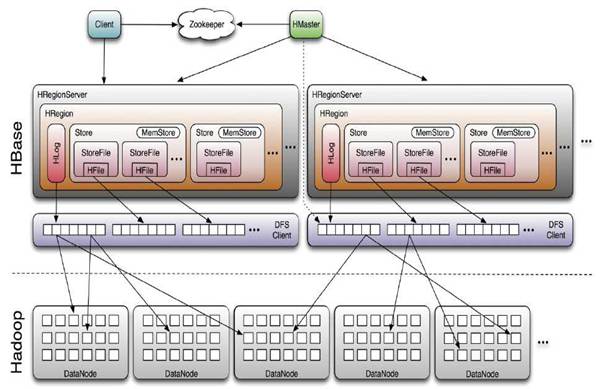
其中HMaster節點用於:
- 管理HRegionServer,實現其負載均衡。
- 管理和分配HRegion,比如在HRegion split時分配新的HRegion;在HRegionServer退出時遷移其內的HRegion到其他HRegionServer上。
- 實現DDL操作(Data Definition Language,namespace和table的增刪改,column familiy的增刪改等)。
- 管理namespace和table的元資料(實際儲存在HDFS上)。
- 許可權控制(ACL)。
HRegionServer節點用於:
- 存放和管理本地HRegion。
- 讀寫HDFS,管理Table中的資料。
- Client直接通過HRegionServer讀寫資料(從HMaster中獲取元資料,找到RowKey所在的HRegion/HRegionServer後)。
ZooKeeper叢集是協調系統,用於:
- 存放整個 HBase叢集的元資料以及叢集的狀態資訊。
- 實現HMaster主從節點的failover。
HBase Client通過RPC方式和HMaster、HRegionServer通訊;一個HRegionServer可以存放1000個HRegion;底層Table資料儲存於HDFS中,而HRegion所處理的資料儘量和資料所在的DataNode在一起,實現資料的本地化;資料本地化並不是總能實現,比如在HRegion移動(如因Split)時,需要等下一次Compact才能繼續回到本地化。
本著半翻譯的原則,再貼一個《An In-Depth Look At The HBase Architecture》的架構圖: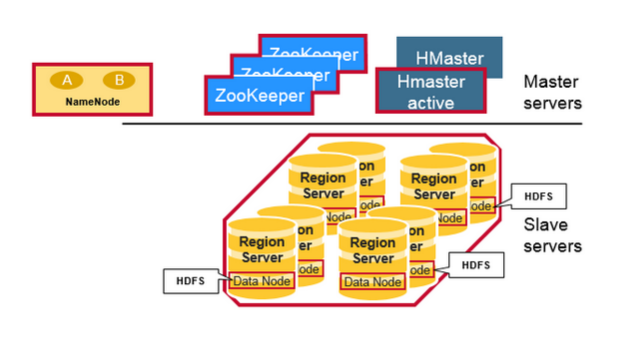
這個架構圖比較清晰的表達了HMaster和NameNode都支援多個熱備份,使用ZooKeeper來做協調;ZooKeeper並不是雲般神祕,它一般由三臺機器組成一個叢集,內部使用PAXOS演算法支援三臺Server中的一臺宕機,也有使用五臺機器的,此時則可以支援同時兩臺宕機,既少於半數的宕機,然而隨著機器的增加,它的效能也會下降;RegionServer和DataNode一般會放在相同的Server上實現資料的本地化。
HRegion
HBase使用RowKey將表水平切割成多個HRegion,從HMaster的角度,每個HRegion都紀錄了它的StartKey和EndKey(第一個HRegion的StartKey為空,最後一個HRegion的EndKey為空),由於RowKey是排序的,因而Client可以通過HMaster快速的定位每個RowKey在哪個HRegion中。HRegion由HMaster分配到相應的HRegionServer中,然後由HRegionServer負責HRegion的啟動和管理,和Client的通訊,負責資料的讀(使用HDFS)。每個HRegionServer可以同時管理1000個左右的HRegion(這個數字怎麼來的?沒有從程式碼中看到限制,難道是出於經驗?超過1000個會引起效能問題?來回答這個問題:感覺這個1000的數字是從BigTable的論文中來的(5 Implementation節):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))。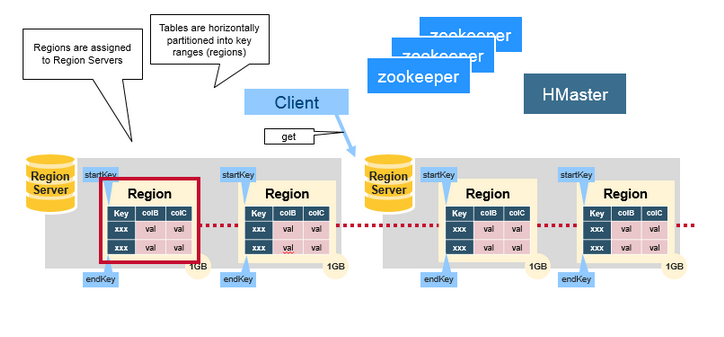
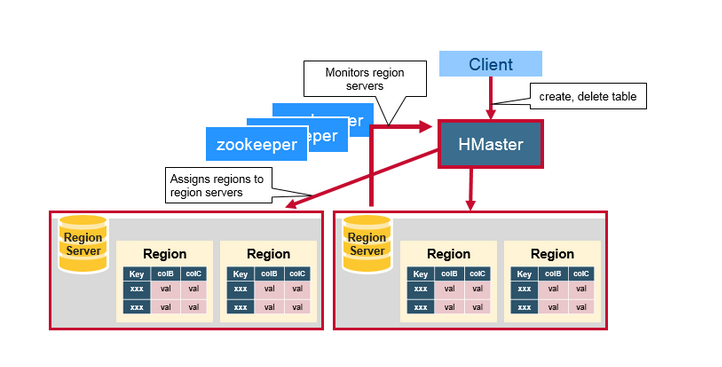
HMaster
HMaster沒有單點故障問題,可以啟動多個HMaster,通過ZooKeeper的Master Election機制保證同時只有一個HMaster出於Active狀態,其他的HMaster則處於熱備份狀態。一般情況下會啟動兩個HMaster,非Active的HMaster會定期的和Active HMaster通訊以獲取其最新狀態,從而保證它是實時更新的,因而如果啟動了多個HMaster反而增加了Active HMaster的負擔。前文已經介紹過了HMaster的主要用於HRegion的分配和管理,DDL(Data Definition Language,既Table的新建、刪除、修改等)的實現等,既它主要有兩方面的職責:
- 協調HRegionServer
- 啟動時HRegion的分配,以及負載均衡和修復時HRegion的重新分配。
- 監控叢集中所有HRegionServer的狀態(通過Heartbeat和監聽ZooKeeper中的狀態)。
- Admin職能
- 建立、刪除、修改Table的定義。
ZooKeeper:協調者
ZooKeeper為HBase叢集提供協調服務,它管理著HMaster和HRegionServer的狀態(available/alive等),並且會在它們宕機時通知給HMaster,從而HMaster可以實現HMaster之間的failover,或對宕機的HRegionServer中的HRegion集合的修復(將它們分配給其他的HRegionServer)。ZooKeeper叢集本身使用一致性協議(PAXOS協議)保證每個節點狀態的一致性。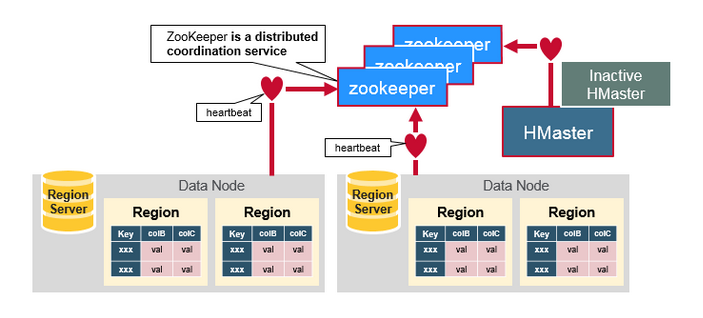
How The Components Work Together
ZooKeeper協調叢集所有節點的共享資訊,在HMaster和HRegionServer連線到ZooKeeper後建立Ephemeral節點,並使用Heartbeat機制維持這個節點的存活狀態,如果某個Ephemeral節點實效,則HMaster會收到通知,並做相應的處理。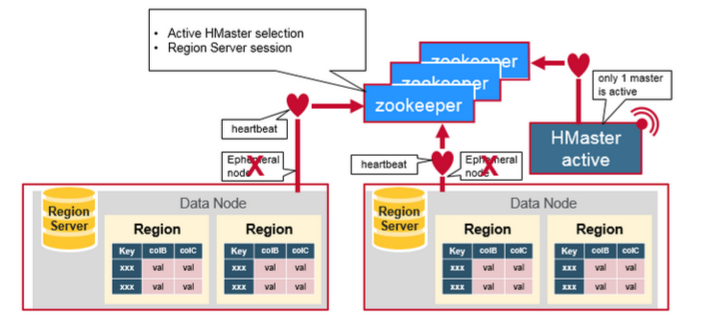
另外,HMaster通過監聽ZooKeeper中的Ephemeral節點(預設:/hbase/rs/*)來監控HRegionServer的加入和宕機。在第一個HMaster連線到ZooKeeper時會建立Ephemeral節點(預設:/hbasae/master)來表示Active的HMaster,其後加進來的HMaster則監聽該Ephemeral節點,如果當前Active的HMaster宕機,則該節點消失,因而其他HMaster得到通知,而將自身轉換成Active的HMaster,在變為Active的HMaster之前,它會建立在/hbase/back-masters/下建立自己的Ephemeral節點。
HBase的第一次讀寫
在HBase 0.96以前,HBase有兩個特殊的Table:-ROOT-和.META.(如BigTable中的設計),其中-ROOT- Table的位置儲存在ZooKeeper,它儲存了.META. Table的RegionInfo資訊,並且它只能存在一個HRegion,而.META. Table則儲存了使用者Table的RegionInfo資訊,它可以被切分成多個HRegion,因而對第一次訪問使用者Table時,首先從ZooKeeper中讀取-ROOT- Table所在HRegionServer;然後從該HRegionServer中根據請求的TableName,RowKey讀取.META. Table所在HRegionServer;最後從該HRegionServer中讀取.META. Table的內容而獲取此次請求需要訪問的HRegion所在的位置,然後訪問該HRegionSever獲取請求的資料,這需要三次請求才能找到使用者Table所在的位置,然後第四次請求開始獲取真正的資料。當然為了提升效能,客戶端會快取-ROOT- Table位置以及-ROOT-/.META. Table的內容。如下圖所示: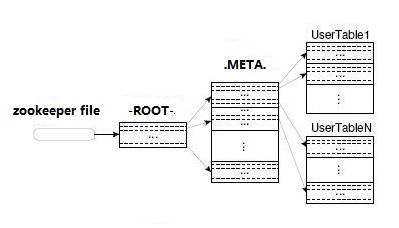
可是即使客戶端有快取,在初始階段需要三次請求才能直到使用者Table真正所在的位置也是效能低下的,而且真的有必要支援那麼多的HRegion嗎?或許對Google這樣的公司來說是需要的,但是對一般的叢集來說好像並沒有這個必要。在BigTable的論文中說,每行METADATA儲存1KB左右資料,中等大小的Tablet(HRegion)在128MB左右,3層位置的Schema設計可以支援2^34個Tablet(HRegion)。即使去掉-ROOT- Table,也還可以支援2^17(131072)個HRegion, 如果每個HRegion還是128MB,那就是16TB,這個貌似不夠大,但是現在的HRegion的最大大小都會設定的比較大,比如我們設定了2GB,此時支援的大小則變成了4PB,對一般的叢集來說已經夠了,因而在HBase 0.96以後去掉了-ROOT- Table,只剩下這個特殊的目錄表叫做Meta Table(hbase:meta),它儲存了叢集中所有使用者HRegion的位置資訊,而ZooKeeper的節點中(/hbase/meta-region-server)儲存的則直接是這個Meta Table的位置,並且這個Meta Table如以前的-ROOT- Table一樣是不可split的。這樣,客戶端在第一次訪問使用者Table的流程就變成了:
- 從ZooKeeper(/hbase/meta-region-server)中獲取hbase:meta的位置(HRegionServer的位置),快取該位置資訊。
- 從HRegionServer中查詢使用者Table對應請求的RowKey所在的HRegionServer,快取該位置資訊。
- 從查詢到HRegionServer中讀取Row。
從這個過程中,我們發現客戶會快取這些位置資訊,然而第二步它只是快取當前RowKey對應的HRegion的位置,因而如果下一個要查的RowKey不在同一個HRegion中,則需要繼續查詢hbase:meta所在的HRegion,然而隨著時間的推移,客戶端快取的位置資訊越來越多,以至於不需要再次查詢hbase:meta Table的資訊,除非某個HRegion因為宕機或Split被移動,此時需要重新查詢並且更新快取。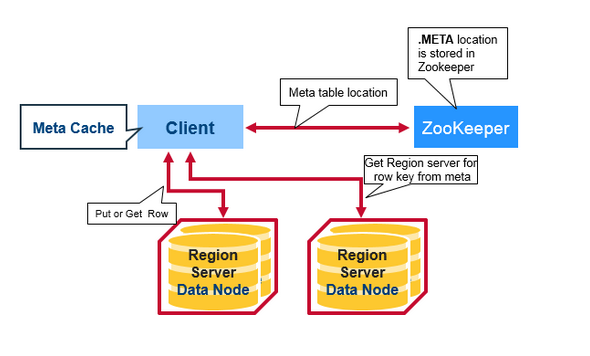
hbase:meta表
hbase:meta表儲存了所有使用者HRegion的位置資訊,它的RowKey是:tableName,regionStartKey,regionId,replicaId等,它只有info列族,這個列族包含三個列,他們分別是:info:regioninfo列是RegionInfo的proto格式:regionId,tableName,startKey,endKey,offline,split,replicaId;info:server格式:HRegionServer對應的server:port;info:serverstartcode格式是HRegionServer的啟動時間戳。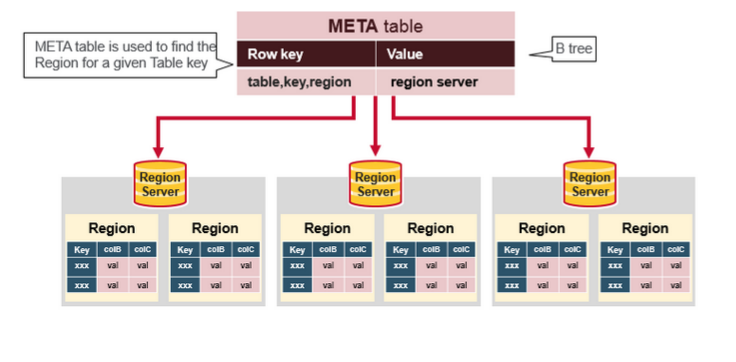
HRegionServer詳解
HRegionServer一般和DataNode在同一臺機器上執行,實現資料的本地性。HRegionServer包含多個HRegion,由WAL(HLog)、BlockCache、MemStore、HFile組成。
- WAL即Write Ahead Log,在早期版本中稱為HLog,它是HDFS上的一個檔案,如其名字所表示的,所有寫操作都會先保證將資料寫入這個Log檔案後,才會真正更新MemStore,最後寫入HFile中。採用這種模式,可以保證HRegionServer宕機後,我們依然可以從該Log檔案中讀取資料,Replay所有的操作,而不至於資料丟失。這個Log檔案會定期Roll出新的檔案而刪除舊的檔案(那些已持久化到HFile中的Log可以刪除)。WAL檔案儲存在/hbase/WALs/${HRegionServer_Name}的目錄中(在0.94之前,儲存在/hbase/.logs/目錄中),一般一個HRegionServer只有一個WAL例項,也就是說一個HRegionServer的所有WAL寫都是序列的(就像log4j的日誌寫也是序列的),這當然會引起效能問題,因而在HBase 1.0之後,通過HBASE-5699實現了多個WAL並行寫(MultiWAL),該實現採用HDFS的多個管道寫,以單個HRegion為單位。關於WAL可以參考Wikipedia的Write-Ahead Logging。順便吐槽一句,英文版的維基百科竟然能毫無壓力的正常訪問了,這是某個GFW的疏忽還是以後的常態?
- BlockCache是一個讀快取,即“引用區域性性”原理(也應用於CPU,分空間區域性性和時間區域性性,空間區域性性是指CPU在某一時刻需要某個資料,那麼有很大的概率在一下時刻它需要的資料在其附近;時間區域性性是指某個資料在被訪問過一次後,它有很大的概率在不久的將來會被再次的訪問),將資料預讀取到記憶體中,以提升讀的效能。HBase中提供兩種BlockCache的實現:預設on-heap LruBlockCache和BucketCache(通常是off-heap)。通常BucketCache的效能要差於LruBlockCache,然而由於GC的影響,LruBlockCache的延遲會變的不穩定,而BucketCache由於是自己管理BlockCache,而不需要GC,因而它的延遲通常比較穩定,這也是有些時候需要選用BucketCache的原因。這篇文章BlockCache101對on-heap和off-heap的BlockCache做了詳細的比較。
- HRegion是一個Table中的一個Region在一個HRegionServer中的表達。一個Table可以有一個或多個Region,他們可以在一個相同的HRegionServer上,也可以分佈在不同的HRegionServer上,一個HRegionServer可以有多個HRegion,他們分別屬於不同的Table。HRegion由多個Store(HStore)構成,每個HStore對應了一個Table在這個HRegion中的一個Column Family,即每個Column Family就是一個集中的儲存單元,因而最好將具有相近IO特性的Column儲存在一個Column Family,以實現高效讀取(資料區域性性原理,可以提高快取的命中率)。HStore是HBase中儲存的核心,它實現了讀寫HDFS功能,一個HStore由一個MemStore 和0個或多個StoreFile組成。
- MemStore是一個寫快取(In Memory Sorted Buffer),所有資料的寫在完成WAL日誌寫後,會 寫入MemStore中,由MemStore根據一定的演算法將資料Flush到地層HDFS檔案中(HFile),通常每個HRegion中的每個 Column Family有一個自己的MemStore。
- HFile(StoreFile) 用於儲存HBase的資料(Cell/KeyValue)。在HFile中的資料是按RowKey、Column Family、Column排序,對相同的Cell(即這三個值都一樣),則按timestamp倒序排列。
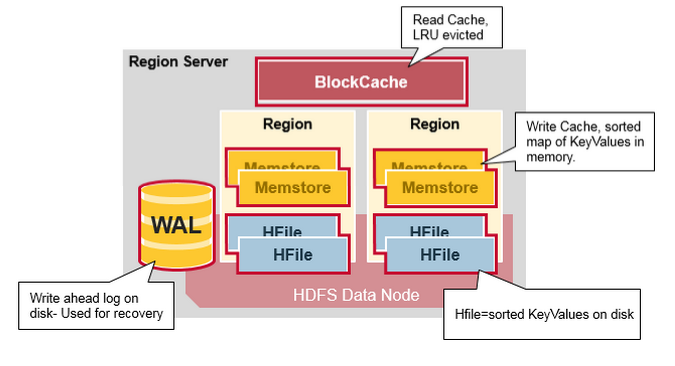
雖然上面這張圖展現的是最新的HRegionServer的架構(但是並不是那麼的精確),但是我一直比較喜歡看以下這張圖,即使它展現的應該是0.94以前的架構。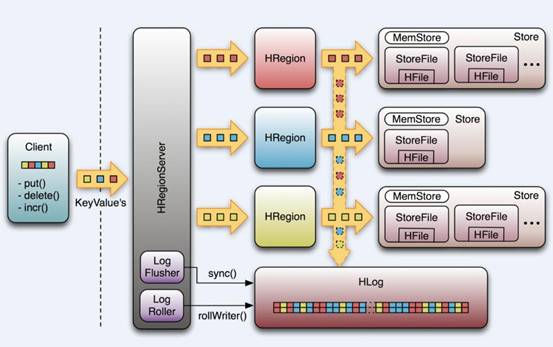
HRegionServer中資料寫流程圖解
當客戶端發起一個Put請求時,首先它從hbase:meta表中查出該Put資料最終需要去的HRegionServer。然後客戶端將Put請求傳送給相應的HRegionServer,在HRegionServer中它首先會將該Put操作寫入WAL日誌檔案中(Flush到磁碟中)。
寫完WAL日誌檔案後,HRegionServer根據Put中的TableName和RowKey找到對應的HRegion,並根據Column Family找到對應的HStore,並將Put寫入到該HStore的MemStore中。此時寫成功,並返回通知客戶端。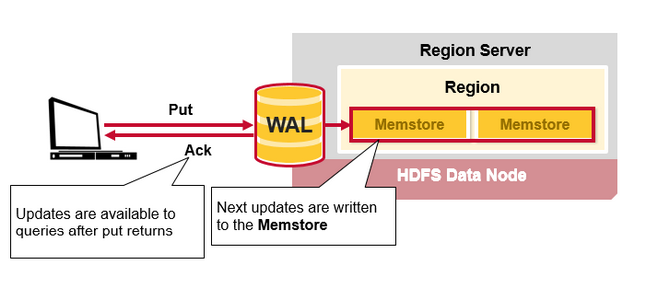
MemStore Flush
MemStore是一個In Memory Sorted Buffer,在每個HStore中都有一個MemStore,即它是一個HRegion的一個Column Family對應一個例項。它的排列順序以RowKey、Column Family、Column的順序以及Timestamp的倒序,如下所示: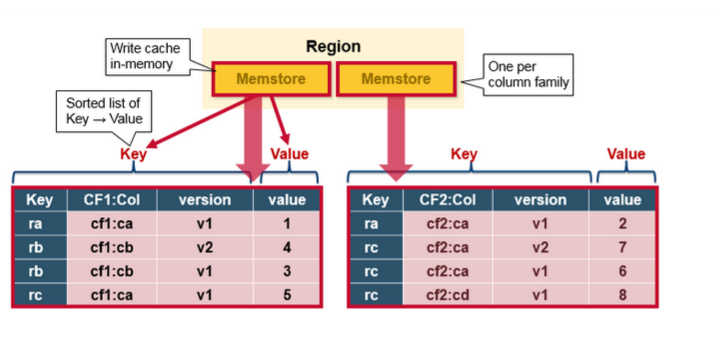
每一次Put/Delete請求都是先寫入到MemStore中,當MemStore滿後會Flush成一個新的StoreFile(底層實現是HFile),即一個HStore(Column Family)可以有0個或多個StoreFile(HFile)。有以下三種情況可以觸發MemStore的Flush動作,需要注意的是MemStore的最小Flush單元是HRegion而不是單個MemStore。據說這是Column Family有個數限制的其中一個原因,估計是因為太多的Column Family一起Flush會引起效能問題?具體原因有待考證。
- 當一個HRegion中的所有MemStore的大小總和超過了hbase.hregion.memstore.flush.size的大小,預設128MB。此時當前的HRegion中所有的MemStore會Flush到HDFS中。
- 當全域性MemStore的大小超過了hbase.regionserver.global.memstore.upperLimit的大小,預設40%的記憶體使用量。此時當前HRegionServer中所有HRegion中的MemStore都會Flush到HDFS中,Flush順序是MemStore大小的倒序(一個HRegion中所有MemStore總和作為該HRegion的MemStore的大小還是選取最大的MemStore作為參考?有待考證),直到總體的MemStore使用量低於hbase.regionserver.global.memstore.lowerLimit,預設38%的記憶體使用量。
- 當前HRegionServer中WAL的大小超過了hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs的數量,當前HRegionServer中所有HRegion中的MemStore都會Flush到HDFS中,Flush使用時間順序,最早的MemStore先Flush直到WAL的數量少於hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs。這裡說這兩個相乘的預設大小是2GB,查程式碼,hbase.regionserver.max.logs預設值是32,而hbase.regionserver.hlog.blocksize是HDFS的預設blocksize,32MB。但不管怎麼樣,因為這個大小超過限制引起的Flush不是一件好事,可能引起長時間的延遲,因而這篇文章給的建議:“Hint: keep hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs just a bit above hbase.regionserver.global.memstore.lowerLimit * HBASE_HEAPSIZE.”。並且需要注意,這裡給的描述是有錯的(雖然它是官方的文件)。
在MemStore Flush過程中,還會在尾部追加一些meta資料,其中就包括Flush時最大的WAL sequence值,以告訴HBase這個StoreFile寫入的最新資料的序列,那麼在Recover時就直到從哪裡開始。在HRegion啟動時,這個sequence會被讀取,並取最大的作為下一次更新時的起始sequence。
HFile格式
HBase的資料以KeyValue(Cell)的形式順序的儲存在HFile中,在MemStore的Flush過程中生成HFile,由於MemStore中儲存的Cell遵循相同的排列順序,因而Flush過程是順序寫,我們直到磁碟的順序寫效能很高,因為不需要不停的移動磁碟指標。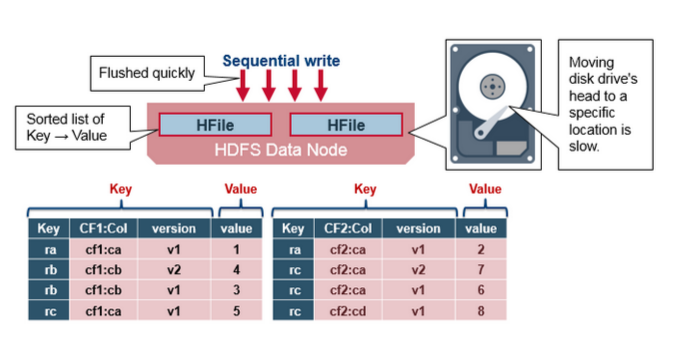
HFile參考BigTable的SSTable和Hadoop的TFile實現,從HBase開始到現在,HFile經歷了三個版本,其中V2在0.92引入,V3在0.98引入。首先我們來看一下V1的格式: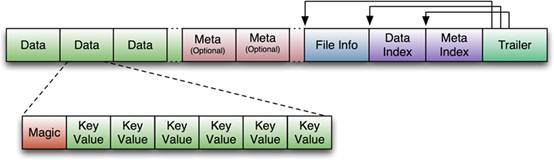
V1的HFile由多個Data Block、Meta Block、FileInfo、Data Index、Meta Index、Trailer組成,其中Data Block是HBase的最小儲存單元,在前文中提到的BlockCache就是基於Data Block的快取的。一個Data Block由一個魔數和一系列的KeyValue(Cell)組成,魔數是一個隨機的數字,用於表示這是一個Data Block型別,以快速監測這個Data Block的格式,防止資料的破壞。Data Block的大小可以在建立Column Family時設定(HColumnDescriptor.setBlockSize()),預設值是64KB,大號的Block有利於順序Scan,小號Block利於隨機查詢,因而需要權衡。Meta塊是可選的,FileInfo是固定長度的塊,它紀錄了檔案的一些Meta資訊,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index紀錄了每個Data塊和Meta塊的其實點、未壓縮時大小、Key(起始RowKey?)等。Trailer紀錄了FileInfo、Data Index、Meta Index塊的起始位置,Data Index和Meta Index索引的數量等。其中FileInfo和Trailer是固定長度的。
HFile裡面的每個KeyValue對就是一個簡單的byte陣列。但是這個byte數組裡麵包含了很多項,並且有固定的結構。我們來看看裡面的具體結構:
開始是兩個固定長度的數值,分別表示Key的長度和Value的長度。緊接著是Key,開始是固定長度的數值,表示RowKey的長度,緊接著是 RowKey,然後是固定長度的數值,表示Family的長度,然後是Family,接著是Qualifier,然後是兩個固定長度的數值,表示Time Stamp和Key Type(Put/Delete)。Value部分沒有這麼複雜的結構,就是純粹的二進位制資料了。隨著HFile版本遷移,KeyValue(Cell)的格式並未發生太多變化,只是在V3版本,尾部添加了一個可選的Tag陣列。
HFileV1版本的在實際使用過程中發現它佔用記憶體多,並且Bloom File和Block Index會變的很大,而引起啟動時間變長。其中每個HFile的Bloom Filter可以增長到100MB,這在查詢時會引起效能問題,因為每次查詢時需要載入並查詢Bloom Filter,100MB的Bloom Filer會引起很大的延遲;另一個,Block Index在一個HRegionServer可能會增長到總共6GB,HRegionServer在啟動時需要先載入所有這些Block Index,因而增加了啟動時間。為了解決這些問題,在0.92版本中引入HFileV2版本: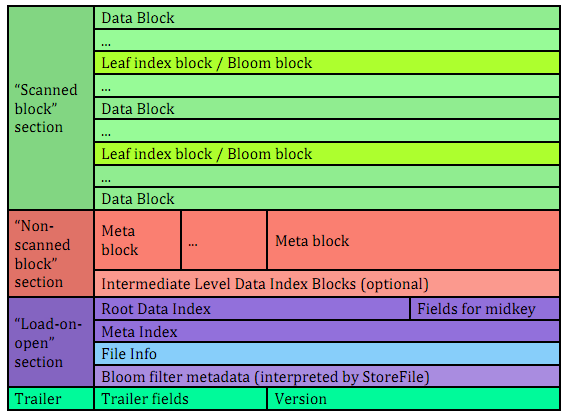
在這個版本中,Block Index和Bloom Filter新增到了Data Block中間,而這種設計同時也減少了寫的記憶體使用量;另外,為了提升啟動速度,在這個版本中還引入了延遲讀的功能,即在HFile真正被使用時才對其進行解析。
FileV3版本基本和V2版本相比,並沒有太大的改變,它在KeyValue(Cell)層面上添加了Tag陣列的支援;並在FileInfo結構中添加了和Tag相關的兩個欄位。關於具體HFile格式演化介紹,可以參考這裡。
對HFileV2格式具體分析,它是一個多層的類B+樹索引,採用這種設計,可以實現查詢不需要讀取整個檔案: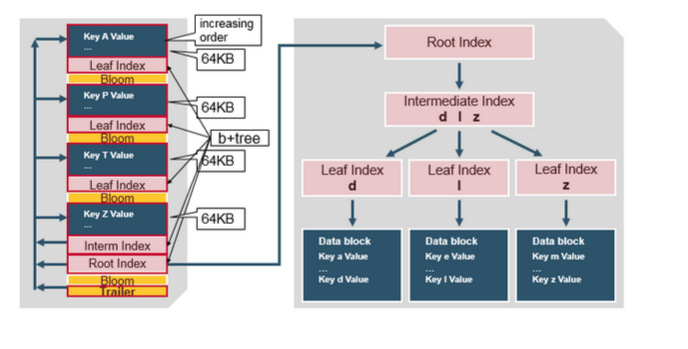
Data Block中的Cell都是升序排列,每個block都有它自己的Leaf-Index,每個Block的最後一個Key被放入Intermediate-Index中,Root-Index指向Intermediate-Index。在HFile的末尾還有Bloom Filter用於快速定位那麼沒有在某個Data Block中的Row;TimeRange資訊用於給那些使用時間查詢的參考。在HFile開啟時,這些索引資訊都被載入並儲存在記憶體中,以增加以後的讀取效能。