
Spark面對OOM問題的解決方法及優化總結
阿新 • • 發佈:2019-02-18
Spark中的OOM問題不外乎以下兩種情況
1. map過程產生大量物件導致記憶體溢位: 這種溢位的原因是在單個map中產生了大量的物件導致的,例如:rdd.map(x=>for(i <- 1 to 10000) yield i.toString),這個操作在rdd中,每個物件都產生了10000個物件,這肯定很容易產生記憶體溢位的問題。針對這種問題,在不增加記憶體的情況下,可以通過減少每個Task的大小,以便達到每個Task即使產生大量的物件Executor的記憶體也能夠裝得下。具體做法可以在會產生大量物件的map操作之前呼叫repartition方法,分割槽成更小的塊傳入map。例如:rdd.repartition(10000).map(x=>for(i <- 1 to 10000) yield i.toString)。 面對這種問題注意,不能使用rdd.coalesce方法,這個方法只能減少分割槽,不能增加分割槽,不會有shuffle的過程。 2.資料不平衡導致記憶體溢位: 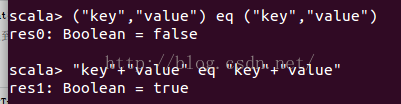
這個例子說明("key","value")和("key","value")在記憶體中是存在不同位置的,也就是存了兩份,但是"key"+"value"雖然出現了兩次,但是隻存了一份,在同一個地址,這用到了JVM常量池的知識.於是乎,如果RDD中有大量的重複資料,或者Array中需要存大量重複資料的時候我們都可以將重複資料轉化為String,能夠有效的減少記憶體使用. 優化: 這一部分主要記錄一下到spark-1.6.1版本,筆者覺得有優化效能作用的一些引數配置和一些程式碼優化技巧,在引數優化部分,如果筆者覺得預設值是最優的了,這裡就不再記錄。 程式碼優化技巧: 1.使用mapPartitions代替大部分map操作,或者連續使用的map操作: 這裡需要稍微講一下RDD和DataFrame的區別。RDD強調的是不可變物件,每個RDD都是不可變的,當呼叫RDD的map型別操作的時候,都是產生一個新的物件,這就導致了一個問題,如果對一個RDD呼叫大量的map型別操作的話,每個map操作會產生一個到多個RDD物件,這雖然不一定會導致記憶體溢位,但是會產生大量的中間資料,增加了gc操作。另外RDD在呼叫action操作的時候,會出發Stage的劃分,但是在每個Stage內部可優化的部分是不會進行優化的,例如rdd.map(_+1).map(_+1),這個操作在數值型RDD中是等價於rdd.map(_+2)的,但是RDD內部不會對這個過程進行優化。DataFrame則不同,DataFrame由於有型別資訊所以是可變的,並且在可以使用sql的程式中,都有除了直譯器外,都會有一個sql優化器,DataFrame也不例外,有一個優化器Catalyst,具體介紹看後面參考的文章。 上面說到的這些RDD的弊端,有一部分就可以使用mapPartitions進行優化,mapPartitions可以同時替代rdd.map,rdd.filter,rdd.flatMap的作用,所以在長操作中,可以在mapPartitons中將RDD大量的操作寫在一起,避免產生大量的中間rdd物件,另外是mapPartitions在一個partition中可以複用可變型別,這也能夠避免頻繁的建立新物件。使用mapPartitions的弊端就是犧牲了程式碼的易讀性。 2.broadcast join和普通join: 在大資料分散式系統中,大量資料的移動對效能的影響也是巨大的。基於這個思想,在兩個RDD進行join操作的時候,如果其中一個RDD相對小很多,可以將小的RDD進行collect操作然後設定為broadcast變數,這樣做之後,另一個RDD就可以使用map操作進行join,這樣能夠有效的減少相對大很多的那個RDD的資料移動。 3.先filter在join: 這個就是謂詞下推,這個很顯然,filter之後再join,shuffle的資料量會減少,這裡提一點是spark-sql的優化器已經對這部分有優化了,不需要使用者顯示的操作,個人實現rdd的計算的時候需要注意這個。 4.partitonBy優化: 5. combineByKey的使用: 這個操作在Map-Reduce中也有,這裡舉個例子:rdd.groupByKey().mapValue(_.sum)比rdd.reduceByKey的效率低,原因如下兩幅圖所示(網上盜來的,侵刪)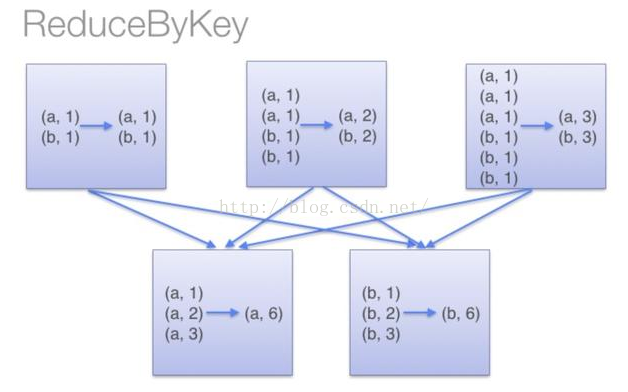
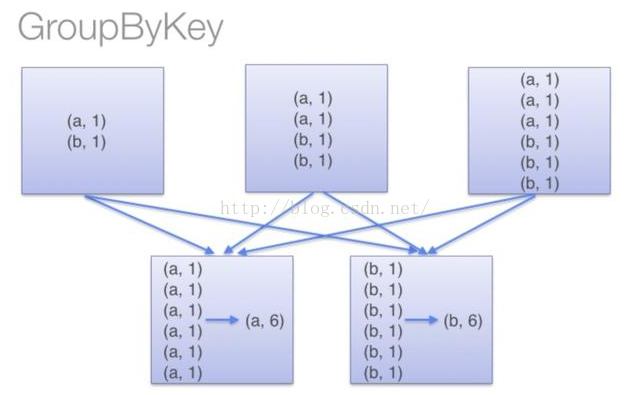
上下兩幅圖的區別就是上面那幅有combineByKey的過程減少了shuffle的資料量,下面的沒有。combineByKey是key-value型rdd自帶的API,可以直接使用。 6. 在記憶體不足的使用,使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache(): rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等價的,在記憶體不足的時候rdd.cache()的資料會丟失,再次使用的時候會重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在記憶體不足的時候會儲存在磁碟,避免重算,只是消耗點IO時間。 7.在spark使用hbase的時候,spark和hbase搭建在同一個叢集: 在spark結合hbase的使用中,spark和hbase最好搭建在同一個叢集上上,或者spark的叢集節點能夠覆蓋hbase的所有節點。hbase中的資料儲存在HFile中,通常單個HFile都會比較大,另外Spark在讀取Hbase的資料的時候,不是按照一個HFile對應一個RDD的分割槽,而是一個region對應一個RDD分割槽。所以在Spark讀取Hbase的資料時,通常單個RDD都會比較大,如果不是搭建在同一個叢集,資料移動會耗費很多的時間。 引數優化部分: 8. spark.driver.memory (default 1g): 這個引數用來設定Driver的記憶體。在Spark程式中,SparkContext,DAGScheduler都是執行在Driver端的。對應rdd的Stage切分也是在Driver端執行,如果使用者自己寫的程式有過多的步驟,切分出過多的Stage,這部分資訊消耗的是Driver的記憶體,這個時候就需要調大Driver的記憶體。 9. spark.rdd.compress (default false) : 這個引數在記憶體吃緊的時候,又需要persist資料有良好的效能,就可以設定這個引數為true,這樣在使用persist(StorageLevel.MEMORY_ONLY_SER)的時候,就能夠壓縮記憶體中的rdd資料。減少記憶體消耗,就是在使用的時候會佔用CPU的解壓時間。 10. spark.serializer (default org.apache.spark.serializer.JavaSerializer ) 建議設定為 org.apache.spark.serializer.KryoSerializer,因為KryoSerializer比JavaSerializer快,但是有可能會有些Object會序列化失敗,這個時候就需要顯示的對序列化失敗的類進行KryoSerializer的註冊,這個時候要配置spark.kryo.registrator引數或者使用參照如下程式碼: valconf=newSparkConf().setMaster(...).setAppName(...)
conf.registerKryoClasses(Array(classOf[MyClass1],classOf[MyClass2]))
valsc =newSparkContext(conf) 11. spark.memory.storageFraction (default 0.5) 這個引數設定記憶體表示 Executor記憶體中 storage/(storage+execution),雖然spark-1.6.0+的版本記憶體storage和execution的記憶體已經是可以互相借用的了,但是借用和贖回也是需要消耗效能的,所以如果明知道程式中storage是多是少就可以調節一下這個引數。 12.spark.locality.wait (default 3s): spark中有4中本地化執行level,PROCESS_LOCAL->NODE_LOCAL->RACK_LOCAL->ANY,一個task執行完,等待spark.locality.wait時間如果,第一次等待PROCESS的Task到達,如果沒有,等待任務的等級下調到NODE再等待spark.locality.wait時間,依次類推,直到ANY。分散式系統是否能夠很好的執行本地檔案對效能的影響也是很大的。如果RDD的每個分割槽資料比較多,每個分割槽處理時間過長,就應該把 spark.locality.wait 適當調大一點,讓Task能夠有更多的時間等待本地資料。特別是在使用persist或者cache後,這兩個操作過後,在本地機器呼叫記憶體中儲存的資料效率會很高,但是如果需要跨機器傳輸記憶體中的資料,效率就會很低。 13. spark.speculation (default false): 一個大的叢集中,每個節點的效能會有差異,spark.speculation這個引數表示空閒的資源節點會不會嘗試執行還在執行,並且執行時間過長的Task,避免單個節點執行速度過慢導致整個任務卡在一個節點上。這個引數最好設定為true。與之相配合可以一起設定的引數有spark.speculation.×開頭的引數。參考中有文章詳細說明這個引數。 以後有遇到新的內容再補充。 參考:
- map執行中記憶體溢位
- shuffle後記憶體溢位
- execution記憶體是執行記憶體,文件中說join,aggregate都在這部分記憶體中執行,shuffle的資料也會先快取在這個記憶體中,滿了再寫入磁碟,能夠減少IO。其實map過程也是在這個記憶體中執行的。
- storage記憶體是儲存broadcast,cache,persist資料的地方。
- other記憶體是程式執行時預留給自己的記憶體。
1. map過程產生大量物件導致記憶體溢位: 這種溢位的原因是在單個map中產生了大量的物件導致的,例如:rdd.map(x=>for(i <- 1 to 10000) yield i.toString),這個操作在rdd中,每個物件都產生了10000個物件,這肯定很容易產生記憶體溢位的問題。針對這種問題,在不增加記憶體的情況下,可以通過減少每個Task的大小,以便達到每個Task即使產生大量的物件Executor的記憶體也能夠裝得下。具體做法可以在會產生大量物件的map操作之前呼叫repartition方法,分割槽成更小的塊傳入map。例如:rdd.repartition(10000).map(x=>for(i <- 1 to 10000) yield i.toString)。 面對這種問題注意,不能使用rdd.coalesce方法,這個方法只能減少分割槽,不能增加分割槽,不會有shuffle的過程。 2.資料不平衡導致記憶體溢位:
這個例子說明("key","value")和("key","value")在記憶體中是存在不同位置的,也就是存了兩份,但是"key"+"value"雖然出現了兩次,但是隻存了一份,在同一個地址,這用到了JVM常量池的知識.於是乎,如果RDD中有大量的重複資料,或者Array中需要存大量重複資料的時候我們都可以將重複資料轉化為String,能夠有效的減少記憶體使用. 優化: 這一部分主要記錄一下到spark-1.6.1版本,筆者覺得有優化效能作用的一些引數配置和一些程式碼優化技巧,在引數優化部分,如果筆者覺得預設值是最優的了,這裡就不再記錄。 程式碼優化技巧: 1.使用mapPartitions代替大部分map操作,或者連續使用的map操作: 這裡需要稍微講一下RDD和DataFrame的區別。RDD強調的是不可變物件,每個RDD都是不可變的,當呼叫RDD的map型別操作的時候,都是產生一個新的物件,這就導致了一個問題,如果對一個RDD呼叫大量的map型別操作的話,每個map操作會產生一個到多個RDD物件,這雖然不一定會導致記憶體溢位,但是會產生大量的中間資料,增加了gc操作。另外RDD在呼叫action操作的時候,會出發Stage的劃分,但是在每個Stage內部可優化的部分是不會進行優化的,例如rdd.map(_+1).map(_+1),這個操作在數值型RDD中是等價於rdd.map(_+2)的,但是RDD內部不會對這個過程進行優化。DataFrame則不同,DataFrame由於有型別資訊所以是可變的,並且在可以使用sql的程式中,都有除了直譯器外,都會有一個sql優化器,DataFrame也不例外,有一個優化器Catalyst,具體介紹看後面參考的文章。 上面說到的這些RDD的弊端,有一部分就可以使用mapPartitions進行優化,mapPartitions可以同時替代rdd.map,rdd.filter,rdd.flatMap的作用,所以在長操作中,可以在mapPartitons中將RDD大量的操作寫在一起,避免產生大量的中間rdd物件,另外是mapPartitions在一個partition中可以複用可變型別,這也能夠避免頻繁的建立新物件。使用mapPartitions的弊端就是犧牲了程式碼的易讀性。 2.broadcast join和普通join: 在大資料分散式系統中,大量資料的移動對效能的影響也是巨大的。基於這個思想,在兩個RDD進行join操作的時候,如果其中一個RDD相對小很多,可以將小的RDD進行collect操作然後設定為broadcast變數,這樣做之後,另一個RDD就可以使用map操作進行join,這樣能夠有效的減少相對大很多的那個RDD的資料移動。 3.先filter在join: 這個就是謂詞下推,這個很顯然,filter之後再join,shuffle的資料量會減少,這裡提一點是spark-sql的優化器已經對這部分有優化了,不需要使用者顯示的操作,個人實現rdd的計算的時候需要注意這個。 4.partitonBy優化: 5. combineByKey的使用: 這個操作在Map-Reduce中也有,這裡舉個例子:rdd.groupByKey().mapValue(_.sum)比rdd.reduceByKey的效率低,原因如下兩幅圖所示(網上盜來的,侵刪)
上下兩幅圖的區別就是上面那幅有combineByKey的過程減少了shuffle的資料量,下面的沒有。combineByKey是key-value型rdd自帶的API,可以直接使用。 6. 在記憶體不足的使用,使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache(): rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等價的,在記憶體不足的時候rdd.cache()的資料會丟失,再次使用的時候會重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在記憶體不足的時候會儲存在磁碟,避免重算,只是消耗點IO時間。 7.在spark使用hbase的時候,spark和hbase搭建在同一個叢集: 在spark結合hbase的使用中,spark和hbase最好搭建在同一個叢集上上,或者spark的叢集節點能夠覆蓋hbase的所有節點。hbase中的資料儲存在HFile中,通常單個HFile都會比較大,另外Spark在讀取Hbase的資料的時候,不是按照一個HFile對應一個RDD的分割槽,而是一個region對應一個RDD分割槽。所以在Spark讀取Hbase的資料時,通常單個RDD都會比較大,如果不是搭建在同一個叢集,資料移動會耗費很多的時間。 引數優化部分: 8. spark.driver.memory (default 1g): 這個引數用來設定Driver的記憶體。在Spark程式中,SparkContext,DAGScheduler都是執行在Driver端的。對應rdd的Stage切分也是在Driver端執行,如果使用者自己寫的程式有過多的步驟,切分出過多的Stage,這部分資訊消耗的是Driver的記憶體,這個時候就需要調大Driver的記憶體。 9. spark.rdd.compress (default false) : 這個引數在記憶體吃緊的時候,又需要persist資料有良好的效能,就可以設定這個引數為true,這樣在使用persist(StorageLevel.MEMORY_ONLY_SER)的時候,就能夠壓縮記憶體中的rdd資料。減少記憶體消耗,就是在使用的時候會佔用CPU的解壓時間。 10. spark.serializer (default org.apache.spark.serializer.JavaSerializer ) 建議設定為 org.apache.spark.serializer.KryoSerializer,因為KryoSerializer比JavaSerializer快,但是有可能會有些Object會序列化失敗,這個時候就需要顯示的對序列化失敗的類進行KryoSerializer的註冊,這個時候要配置spark.kryo.registrator引數或者使用參照如下程式碼: valconf=newSparkConf().setMaster(...).setAppName(...)
conf.registerKryoClasses(Array(classOf[MyClass1],classOf[MyClass2]))
valsc =newSparkContext(conf) 11. spark.memory.storageFraction (default 0.5) 這個引數設定記憶體表示 Executor記憶體中 storage/(storage+execution),雖然spark-1.6.0+的版本記憶體storage和execution的記憶體已經是可以互相借用的了,但是借用和贖回也是需要消耗效能的,所以如果明知道程式中storage是多是少就可以調節一下這個引數。 12.spark.locality.wait (default 3s): spark中有4中本地化執行level,PROCESS_LOCAL->NODE_LOCAL->RACK_LOCAL->ANY,一個task執行完,等待spark.locality.wait時間如果,第一次等待PROCESS的Task到達,如果沒有,等待任務的等級下調到NODE再等待spark.locality.wait時間,依次類推,直到ANY。分散式系統是否能夠很好的執行本地檔案對效能的影響也是很大的。如果RDD的每個分割槽資料比較多,每個分割槽處理時間過長,就應該把 spark.locality.wait 適當調大一點,讓Task能夠有更多的時間等待本地資料。特別是在使用persist或者cache後,這兩個操作過後,在本地機器呼叫記憶體中儲存的資料效率會很高,但是如果需要跨機器傳輸記憶體中的資料,效率就會很低。 13. spark.speculation (default false): 一個大的叢集中,每個節點的效能會有差異,spark.speculation這個引數表示空閒的資源節點會不會嘗試執行還在執行,並且執行時間過長的Task,避免單個節點執行速度過慢導致整個任務卡在一個節點上。這個引數最好設定為true。與之相配合可以一起設定的引數有spark.speculation.×開頭的引數。參考中有文章詳細說明這個引數。 以後有遇到新的內容再補充。 參考: