
selenium模擬登陸豆瓣並獲取cookies
驗證碼處理與模擬登陸豆瓣,首先我們看到豆瓣沒有cookies,我們需要用程式來模擬登陸獲取cookies(當前有些情況下自己手動登陸後複製貼上cookies也能登陸),該文主要講方法,如何用selenium模擬登陸獲取cookies

1、輸入使用者名稱、密碼點選登入,點選登入後跳轉到另外一個驗證碼頁面,並通過雲打碼進行驗證碼返回


2、驗證碼返回後輸入後通過字典推導式獲取每個domain中的name和value,即使cookies
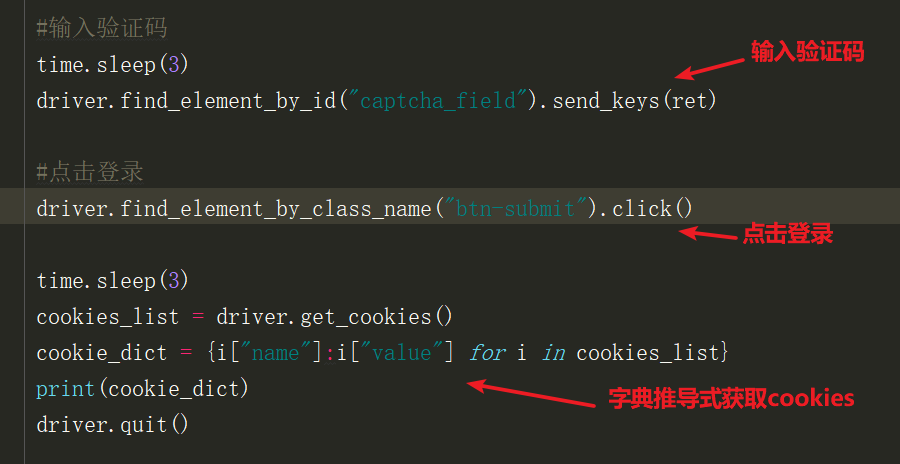
列印獲取的cookies

模擬登陸後獲取的cookies和程式提取列印的cookies對吧,一模一樣,就可以用程式攜帶該cookies進行訪問

相關推薦
selenium模擬登陸豆瓣並獲取cookies
驗證碼處理與模擬登陸豆瓣,首先我們看到豆瓣沒有cookies,我們需要用程式來模擬登陸獲取cookies(當前有些情況下自己手動登陸後複製貼上cookies也能登陸),該文主要講方法,如何用selenium模擬登陸獲取cookies1、輸入使用者名稱、密碼點選登入,點選登入後
使用selenium進行模擬登陸豆瓣
輸入email 和密碼 email = input(‘E-mail:’) password = input(‘Password:’) 獲取輸入框並且輸入賬號和密碼 driver.find_element_by_name(‘form_email’).send_keys(email) dri
selenium栗子之登陸網站並獲取cookie
測試網站(航天雲網): http://cas.casicloud.com/loginservice=http%3A%2F%2Fin.casicloud.com%2Floginc%3Fservice%3D%252Fsso%252Flogin.jsp%253Fredirect%
方案優化:網站實現掃描二維碼關註微信公眾號,自動登陸網站並獲取其信息
用戶 class his onerror 就會 openid display 要點 rac 上一篇 《網站實現掃描二維碼關註微信公眾號,自動登陸網站並獲取其信息》 中已經實現用戶掃碼登陸網站並獲取其信息 但是上一篇方案中存在一個問題,也就是文章末尾指出的可以優化的地方(可
實例:模擬登陸豆瓣
保存 TP spider orm utf attr sta com parse # -*- coding: utf-8 -*-import scrapyimport urllib.request # https://accounts.douban.com/login cla
模擬登陸京東並訪問我的訂單
key service .net org quick window .text login 模擬登陸 第一個出現錯誤 # -*- coding: utf-8 -*- import requests url = ‘https://passport.jd.com/u
selenium模擬登陸淘寶網並且將‘衣服’相關資訊下載儲存在mysql資料庫
import re import pymysql from lxml import etree from selenium import webdriver #一下三行用於等待判斷頁面是否載入完畢 from selenium.webdriver.common.by import By fro
[Demo實踐]模擬登入豆瓣FM獲取個人收藏歌曲“紅心列表”
背景 我很喜歡豆瓣FM的風格,然而它無法滿足我日常的需求,手機上用網易雲音樂,家裡海信電視用QQ音樂、天貓放糖好像是蝦米。好累啊,捨不得豆瓣的歌,想把我收藏的“紅心歌曲”清單都下載下來。 步驟一 模擬登陸豆瓣,使用Fiddler攔截http協議,檢視登入請求。 步驟二 分析http請
python3 使用selenium模擬登陸天眼查抓取資料
由於之前用Scrapy 抓了一些公司的名稱,但是沒有準確的聯絡方式,所以就自己就學習了一下使用selenium自動化工具,速度比較慢,網上也有很多這方面的程式碼,但是大部分的網頁解析部分都出錯了,可能是這種網站定時會更改一下網頁的固定幾個標籤。 網上也有很多說如果遇到一些防爬蟲特別強的網站,比如企查
python 爬蟲 如何通過scrapy簡單模擬登陸豆瓣網,手動進行圖形驗證碼的驗證
1.建立scrapy爬蟲程式,在terminal命令列輸入’scrapy startproject douban_login’ 2.建立爬蟲主程式,主要步驟都在這裡實現,以douban_login.py命名 程式程式碼如下: import scrapy from
Python爬蟲(二十二)_selenium案例:模擬登陸豆瓣
本篇部落格主要用於介紹如何使用selenium+phantomJS模擬登陸豆瓣,沒有考慮驗證碼的問題,更多內容,請參考:Python學習指南 #-*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.
scrapy 模擬登陸豆瓣
參考: https://blog.csdn.net/qq_37616069/article/details/80376807 # coding=utf-8 import scrapy class DoubanLogin(scrapy.Spider): name = 'douban'
Python利用requests模擬登陸豆瓣
要抓取豆瓣電影的評論,我們需要登入自己的賬戶,才能爬取到所有的評論,豆瓣模擬登陸相對而言比較簡單,這裡我簡單分析一下,希望能夠對大家理解模擬登陸有所啟發。 Chorme瀏覽器輸入:https://www.douban.com,按下F12,點選Network選項,如下圖所示: 按下F12
使用selenium模擬登陸oschina
Selenium把元素定位介面封裝得更簡單易用了,支援Xpath、CSS選擇器、以及標籤名、標籤屬性和標籤文字查詢。 from selenium.webdriver import PhantomJS from random import randint import time from selenium.w
打碼平臺-模擬登陸豆瓣網
from selenium import webdriver import time import requests from yundama.dama import indetify #實列化driver driver=webdriver.Chrome() driver.get("http://
Java模擬httpGet請求並獲取返回的資料
1.程式碼例項如下: public class HttpgetUtils { public static String sendGETRequest(String path, Map param
webmagic是個神奇的爬蟲【三】—— 使用selenium模擬登陸
selenium本身是一種自動化測試工具,可以模擬瀏覽器進行頁面的載入,好處在於能通過程式,自動的完成例如頁面登入、AJAX內容獲取的的操作。 尤其是獲取AJAX生成的動態資訊方面,一般爬蟲只會獲取當前頁面的靜態資訊,不會載入動態生成的內容,但是selenium則完美的幫我們實現了這一功能。
爬蟲知識點(ajax非同步載入,JavaScript 動態重新整理,phantomjs + selenium模擬登陸)
JavaScript JavaScript 是網路上最常用也是支持者最多的客戶端指令碼語言。它可以收集 使用者的跟蹤資料,不需要過載頁面直接提交表單,在頁面嵌入多媒體檔案,甚至執行網頁遊戲。 Ajax 當你訪問一個網頁時 滑鼠向下滑 資料不斷的更新而http網址沒有變
最新,最新!selenium模擬登陸知乎
md知乎的程式猿是幹什麼的我不知道,反爬真不一般,深受其害!!! 試了一千萬種方法,哎,終於呀(千萬不要被知乎的程式猿看到了,要不然就又要涼涼了),其他方法特別是用request的好像都失效了(哪位大神要是還能用告訴兄弟一聲) 算是半手動吧,selenium裡面的js模組
安卓HttpClient+Jsoup+Httpwatch模擬登陸正方教務獲取資訊
public static List<NameValuePair> paramsgra1 = new ArrayList<NameValuePair>(); //可以發現這是第一種情況值的傳遞,雖然兩種情況不一樣,但是放心只要是你們學校的學生,登陸的時候值的情況都是兩種,且值都是相同的