
深入學習python解析並讀取PDF檔案內容的方法
這篇文章主要學習了python解析並讀取PDF檔案內容的方法,包括對學習庫的應用,python2.7和python3.6中python解析PDF檔案內容庫的更新,包括對pdfminer庫的詳細解釋和應用。主要參考了一些已有的部落格內容,程式碼。
主要思路是首先利用一個做專案的形式,描述所做的問題,執行環境,和需要安裝的庫,然後寫程式碼,此程式碼是在python2.7中執行,然後寫出在python3.6中執行的程式碼,並詳細解釋python2.7和python3.6中python庫的一些不同之處,最後詳細的解釋了程式碼的意思,和庫的思路,最終的目的就讓我們理解,並學會應用python解析並讀取PDF檔案內容的方法。
一,問題描述
利用python讀取PDF文字內容
二,執行環境
python 3.6
三, 需要安裝的庫
|
1 |
|
四,實現原始碼(其中程式碼1和程式碼2都是python2.7實現的)
程式碼1(win64)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
|
程式碼2(win32)
五,python3.6中如何改進python2.7實現的程式碼
問題一,reload的改進
|
1 2 3 |
|
以上是python2的寫法,但是在python3中這個需要已經不存在了,這麼做也不會什麼實際意義。
在Python2.x中由於str和byte之間沒有明顯區別,經常要依賴於defaultencoding來做轉換。
在python3中有了明確的str和byte型別區別,從一種型別轉換成另一種型別要顯式指定encoding。
但是仍然可以使用這個方法代替
|
1 2 |
|
問題二,pdfminer模組的安裝
在python2.7中可以直接安裝
|
1 |
|
在python3.6中就需要安裝
|
1 |
|
六 python3.6的原始碼
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
|
七 python讀取PDF文件程式碼分析
PDF格式不是規範格式. 儘管它被叫做"PDF文件", 但並不像word或者html文件。PDF的表現更像一張圖片。PDF更像是在一張紙的各個準確的位置上把內容都擺放出來。大部分情況下,沒有邏輯結構,比如句子或段落,並且不能自適應頁面大小的調整。PDFMiner嘗試通過猜測它們的佈局來重建它們的結構,但是不保證一定能工作。我知道這樣很難看,但是,PDF確實不夠規範。
下面這個圖片是使用流程說明,我們將其分解來看
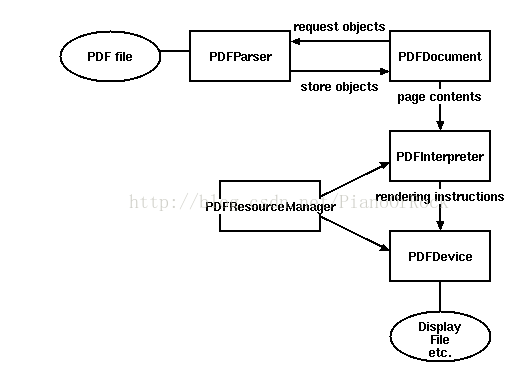
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
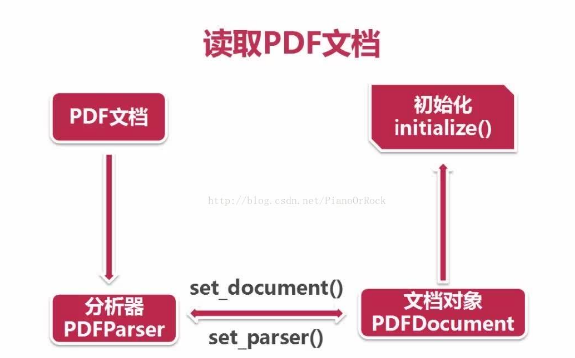
首先使用 open 方法或者 urlopen 開啟本場文件或者網路文件(一般會這麼做因為考慮到文件太大,對網路伺服器負擔也很大)生成文件物件,以下的方法之中的網路連結已經存在了。
|
1 2 3 |
|
然後建立 文件解析器 和 PDF文件物件 並將他們相互關聯
|
1 2 3 4 5 6 7 8 9 |
|
對 PDF文件物件 進行初始化,如果文件本身進行了加密,則需要在加入 password 引數
|
1 2 |
|
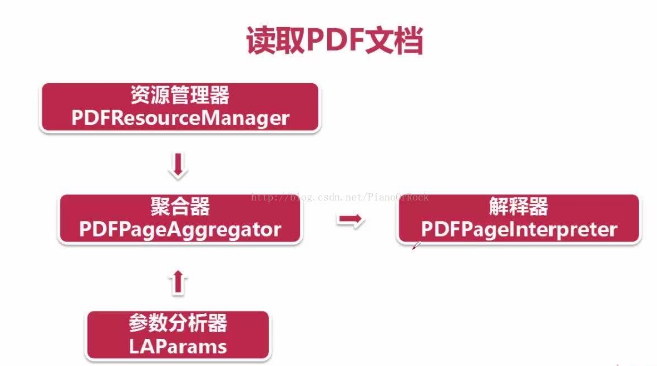
先建立 PDF資源管理器 和 引數分析器
|
1 2 3 4 5 |
|
再建立一個 聚合器 ,並接收 PDF資源管理器 引數分析器 作為引數
|
1 2 |
|
最後建立一個 頁面直譯器 ,將 PDF資源管理器 和 聚合器 作為引數
|
1 2 |
|
這樣 頁面直譯器 就具有對PDF文件進行編碼,解釋成Python能夠識別的格式
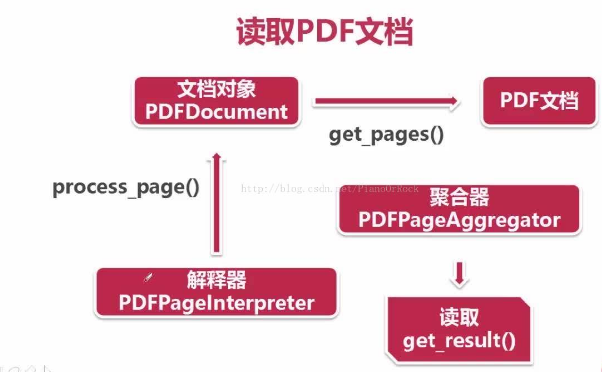
最後呢,使用 PDF文件物件 的 get_pages()方法 從PDF文件中讀取出頁面集合,接著使用 頁面直譯器 對頁面集合逐一讀取,再呼叫 聚合器 的 get_result()方法 將頁面逐一放置到 layout 之中,最後商用 layout 的 get_text()方法 獲取每一頁的 text。
|
1 2 3 4 5 6 7 8 9 |
|
需要注意的是在PDF文件中不只有 text 還可能有圖片等等,為了確保不出錯先判斷物件是否具有 get_text()方法
八,結果分析
如果PDF檔案中僅僅是文字,那麼會完全解析出來,讀出文字,存在一個TXT文件裡面,但是要是出現了圖片等東西,則不會讀取到東西。
本文做了三個實驗,分別是PDF文件裡面只存在文字,只存在圖片,存在文字和圖片。
結果顯示:
| 只存在文字的PDF | 此程式會全部讀取出文字 |
| 只存在圖片的PDF | 此程式不會讀取出任何東西 |
| 存在圖片和文字 | 此程式只會讀出文字,不會識別圖片 |
所以說,圖片的文字識別,不能只單純的使用pdfminer這個庫,還需要圖片處理等相關技術。
不經一番徹骨寒 怎得梅花撲鼻香