
solr億萬級索引優化實踐(四)
本篇是這個系類的最後一篇,但優化方案不僅於此,需要後續的研究與學習,本篇主要從schema設計的角度來做一些實踐。
schema.xml 這個檔案的作用是定義索引資料中的域的,包括域名稱,域型別,域是否索引,是否分詞,是否儲存,是否標準化,是否儲存項向量等等。在solr6中這個檔案是存放在zookeeper的/configs節點之下的,在建立新的collection時,solr會根據此節點下的資訊生成相應的索引庫,其相關的配置資訊會同步到solrhome/core目錄下的core.properties檔案中。同步schema檔案的指令語句樣例為:
bin/solr zk -upconfig -z 127.0.01:2181 -n conf -d /solrhome/configsets/sample_techproducts_configs/conf
為了改進效能,可以從以下幾個方面來著手:
1、對於field元素,我們將所有隻用於搜尋的,而不需要作為查詢結果的field(特別是一些比較大的field)的stored設定為false,這樣這個欄位的值將不會被儲存,但可以被檢索,會減少不小的IO開銷。我們設計了一個利用solr來做hbase的二級索引架構,可以利用hbase來儲存欄位資訊,充分利用hadoop的大資料特性。
2、能不用copyfield這個元素就不用,這個屬性會對欄位做雙倍儲存,顯然非常耗效能,好處就是在查詢的時候,想要對多個欄位進行檢索只需要檢索一個欄位。
3、將一些不需要被檢索的欄位的index屬性,設定成false,這樣solr就不會對這個欄位進行索引。
5、不使用中文分詞器或者使用高亮功能。termPositions termOffsets的值全都設定成false。
6、在測試中發現solr在處理小報文(1K以下)的情況下吞吐量並不理想,當適當增大報文,發現速度可以得到大幅度提高,可以從之前的每個節點10M/S暴漲到30M/S。
但是在很多情況下,我們並不能人為控制報文長度,這個時候,可以通過solr的欄位多值來達到目的,即將將多條訊息的每個欄位的值放到一起,在schema中配置multValued為true。儲存到solr中是這個樣子的:
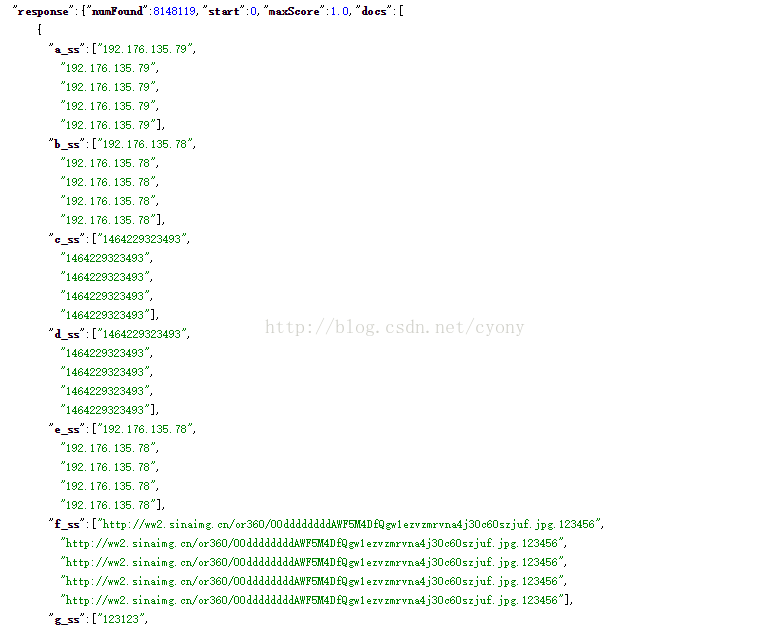
這樣速度是可以單臺節點達到30M/S甚至更高,但是帶來的問題就是查詢會變得很複雜,在命中多值中任意一條記錄,結果集會帶出所有值,在solr中認為這一組資料是一個文件,我們想了很多方案來解決這個問題,比較簡單的方法是,在生成文件的時候控制多值欄位中,沒有重複的值,這樣檢索結果則會變得精確,缺點就是靈活性太低。另一個方案,是通過對資料做預聚合,管理快照,由於其實現比較複雜,效果也不是很理想,在此就不做過多描述了。
在不追求檢索精確度,或者對資料可控的情況下,對於索引速度真的可以帶來很大的驚喜。
尾言:solr由於是利用lucene為底層,lucene本身是單機的無法分散式,solr的核心就是引入了分片的機制,在資料規模變得特別龐大的時候各種弊端就顯示出來了,無論是建立索引還是查詢效能都不盡人意。但通過各種方法的優化與捨棄之後,差不多可以做到水平拓展,線性增長,能夠滿足大多數的業務場景。但是如果是要對歷史資料進行檢索的時候,這個歷史資料規模又是極其巨量時,solr恐怕是無法承受的。現在興起了很多列式儲存結構以及時間序列的資料庫以及倉庫,比如driud和tsdb,他們在巨量資料檢索時可以帶來極高的效能體驗。