
[052]TensorFlow Layers指南:基於CNN的手寫數字識別
TensorFlow Layers module 為容易的建立一個神經網路提供了高水平的API介面。它提供了很多方法幫助建立dense(全連線)層和卷積層,增加啟用函式和應用dropout做歸一化。在這個教程中,你會學到如何用layers構建一個卷積神經網路用於識別手寫體數字,基於MNIST資料集。

MNIST 資料集包括手寫體數字0~9的6萬個訓練資料和1萬個測試資料,並格式化為28*28畫素單色圖片。
開端
讓我們先建立一個TensorFlow程式 的主框架。建立一個檔案命名為:cnn_mnist.py,並書寫如下程式碼:
from __future__ import 閱讀完這段教程,學習相應程式碼就能完成構建,訓練和驗證一個卷積神經網路,完成程式碼可以從這裡獲取
卷積神經網路介紹
卷積神經網路(CNNs)介紹是現在圖片分類任務的一個理想模型。CNN通過一系列的過濾器從圖片的原始畫素資料上抽取和學習更高層次的特徵,這些特徵用於模型進行分類。CNN包含三部分:
- 卷積層(Convolutional layers):這層會應用一定數量的卷積器到圖片上。對於每個子區域,該層用一套數學運算產生一個單獨的值在輸出特徵對映中。卷積層特別的應用了一個ReLU activation function到輸出資料上用於引用非線性到模型中。
- 池化層(Pooling layers):這層下采樣圖片資料抽取操作,來減少特徵維度以減少處理時間。池演算法中最大池演算法通常被使用,最大池演算法抽取特徵圖的子區域(例如:2*2畫素塊)
- 全連線層(Dense (fully connected) layers):Fully Connected 也叫 Dense,因為全連線權重密度很大。其實就是個卷積核寬高等於輸入資料寬高的特殊卷積層。卷積層和全連線層可以等效轉換。該層用於前面卷積層和池化層的下采樣進行 的特徵抽取後的分類任務。這層的每個節點都被前一層的每個節點連線。
通常,一個CNN由一系列的卷積模組組成,這些模組完成每步的特徵抽取。每個模組由一個卷積層和緊跟的一個池化層組成,最後一個卷積模組由一個或多個全連線層組成,完成分類任務。在CNN的最後一個全連線層對模型的的每個目標類別(模型預測的所有可能類別)都包含著一個單獨的節點,這個全連線層有一個softmax啟用函式用於為每個節點產生一個0-1之間的值(所有這些softmax值的總和等於1)。我們能夠把softmax值對應到一個給定的圖片,而這些圖片都是對應每個目標類別。CNN網路示例如下:
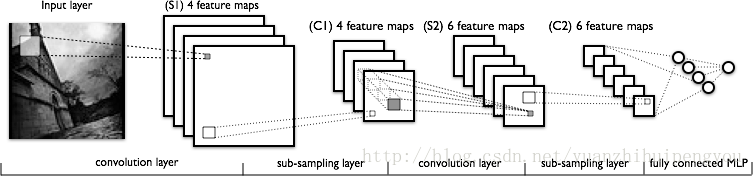
- 想更全面的瞭解CNN的架構,可以看斯坦福的CNN用於視覺識別課程材料
構建CNN的MNIST分類器
讓我們用下面的CNN架構構建一個模型用於對MNIST資料集圖片進行分類。
1. 卷積層1:用32個 的5*5的卷積核(抽取5*5畫素的子區域),使用ReLu啟用函式。
2. 池化層1:用一個2*2的過濾器進行最大池化,步長為2(保證池化區域不重疊)。
3. 卷積層2:用於64個 的5*5的卷積核,使用ReLu啟用函式。
4. 池化層2:再次用一個2*2的過濾器進行最大池化,步長為2
5. 全連線層1:1024個神經元節點,每個節點有0.4的的概率會正則化丟棄(每個給定的元素點在訓練時有0.4的概率被丟棄,防止過擬合)。
6. 全連線層2:10個神經元節點,每一個對應一個數字目標類(0-9)
tf.layers模組包含了建立上面三種層的方法:
- conv2d():構建一個二維的卷積層。引數有:卷積核數(filters)、卷積和尺寸、填充(padding)、啟用函式。
- max_pooling2d():構建一個二維的池化層,使用最大池演算法。引數有:池化核尺寸,步長。
- dense():構建一個全連線層。引數有:神經元節點數、啟用函式。
上面的每一個函式都接收一個張量(tensor)作為輸入,並且返回一個變換過的張量作為輸出。這樣能夠容易的連線一層到另一層:某一層的輸出作為下一層的輸入。
將下面的cnn_model_fn函式新增到cnn_mnist.py中,這符合TensorFlow’s Estimator API期待的介面。cnn_mnist.py將MNIST特徵資料,標籤集合模型模式(TRAIN, EVAL, INFER)作為引數。配置CNN網路,並且返回預測值,損失值和訓練操作。
def cnn_model_fn(features, labels, mode):
"""Model function for CNN."""
# Input Layer
input_layer = tf.reshape(features, [-1, 28, 28, 1])
# Convolutional Layer #1
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer #1
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# Convolutional Layer #2 and Pooling Layer #2
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# Dense Layer
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == learn.ModeKeys.TRAIN)
# Logits Layer
logits = tf.layers.dense(inputs=dropout, units=10)
loss = None
train_op = None
# Calculate Loss (for both TRAIN and EVAL modes)
if mode != learn.ModeKeys.INFER:
onehot_labels = tf.one_hot(indices=tf.cast(labels, tf.int32), depth=10)
loss = tf.losses.softmax_cross_entropy(
onehot_labels=onehot_labels, logits=logits)
# Configure the Training Op (for TRAIN mode)
if mode == learn.ModeKeys.TRAIN:
train_op = tf.contrib.layers.optimize_loss(
loss=loss,
global_step=tf.contrib.framework.get_global_step(),
learning_rate=0.001,
optimizer="SGD")
# Generate Predictions
predictions = {
"classes": tf.argmax(
input=logits, axis=1),
"probabilities": tf.nn.softmax(
logits, name="softmax_tensor")
}
# Return a ModelFnOps object
return model_fn_lib.ModelFnOps(
mode=mode, predictions=predictions, loss=loss, train_op=train_op)下面的部分(對應上面每塊程式碼塊的頭部)深入到tf.layers程式碼中,瞭解如何建立每層網路結構、如何計算損失(loss)、配置訓練操作過程和進行預測。如果你已經對CNNs和TensorFlow Estimators非常熟悉了,能夠直觀的明白上述程式碼,你可以跳過這一部分或直接跳到"Training and Evaluating the CNN MNIST Classifier"
輸入層(Input Layer)
在layers模組中用於建立用於二維圖片資料的卷積層和池化層的方法期待的張量(tensors)有一個結構(shape):[batch_size, image_width, image_height, channels],定義如下:
- batch_size:子集的個數,例如在訓練時,當執行梯度下降(gradient descent)時被用到。
- image_width:樣例圖片的寬度。
- image_height:樣例圖片的高度。
- channels:用例圖片的顏色通道數。對於彩色圖片,通道數為3(紅,綠,藍),對於單色圖片,僅有一個通道(黑)
這裡,我們的MNIST資料集由單色28*28畫素的圖片組成,因此對於我們的輸入層理想的結構是[batch_size, 28, 28, 1]。
為了修正我們的輸入特徵對映到這個結構,我們可以執行下面的reshape運算:
input_layer = tf.reshape(features, [-1, 28, 28, 1])
注意到這裡我們指定batch size為-1,這是個特殊值,指這個維度應該基於在特徵集features中輸入值的數量,保持所有其它維度尺寸固定。
卷積層1(Convolutional Layer1):
在我們第一個卷積層,我們應用32個5*5畫素的過濾器到輸入層,用ReLU啟用函式,我們用layers中的conv2d()方法建立這個層,如下:
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)inputs引數必須是我們的輸入張量,必須是[batch_size, image_width, image_height, channels]結構。filters引數指定是應用的過濾器個數(這裡是32),kernel_size只每個過濾器的維度[width, height](這裡[5, 5])。
說明:如果過濾器的寬度和高度有相同的值,可以指定一個單獨的整數,如:kernel_size=5padding引數為兩個列舉型別中的一個:valid(預設值)或者same。如果我們想輸出張量的寬度和高度跟輸入一致,我們可以設padding=same,這會指示TensorFlow在輸出張量的邊界加0值,來滿足28的寬和高度(如果沒有padding,一個5*5的卷積作用在28*28的張量上將會產生一個24*24的張量,有24*24個位置去提取5*5的區域從28*28的格子上)。activation引數指定應用到卷積輸出的的啟用函式,這裡指定ReLU啟用函式tf.nn.relu。
這裡通過conv2d()產生的輸出張量有一個結構[batch_size, 28, 28, 32]:與輸入有相同的寬度和高度維度,但是每一個過濾器輸出有32個通道。
池化層1(Pooling Layer1):
下面,我們連線第一個池化層到我們剛剛建立的卷積層。我們能夠用layers裡的max_pooling2d()方法構建一個層,這個層用2*2的過濾器和步長2來進行最大池化:
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
inputs引數指定結構是[batch_size, image_width, image_height, channels]的輸入張量。這裡我們的輸入張量是conv1,第一個卷積層的輸出,輸出張量有結構[batch_size, 28, 28, 32]。pool_size引數指定最大池化過濾器的尺寸[width, height](這裡是,[2,2]),如果兩個維度有相同的值,可以用一個單獨的整數值代替(pool_size=2)。strides引數指定步長的值,這裡為2,如果想在兩個維度指定不同 的步長值,可以設如:stride=[3, 6]
max_pooling2d()函式產生的輸出張量(pool1)結構為:[batch_size, 14, 14, 32]:2*2的過濾器會減少寬和高的50%。
卷積層2和池化層2
我們能夠像前面一樣,用conv2d()和max_pooling2d()函式連線第二個卷積和池化層到CNN網路,對於卷積層2,我們配置64個5*5的過濾器和ReLu啟用函式,並且對於池化層2,我們使用相同的空間,如池化層1(一個2*2的最大池化過濾器和步長2):
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)註釋:卷積層2把第一個池化層的輸出(pool1)作為輸入,並且產生輸出張量conv2,架構為:[batch_size, 14, 14, 64],與pool1有相同的寬度和高度,並且64個通道對應應用的64個過濾器。
池化層2把conv2作為輸入,產生pool2作為輸出,pool2結構為[batch_size, 7, 7, 64]
全連線層(Dense Layer):
下面,我們增加一個全連線層(1024個神經單元和Relu啟用函式)到CNN網路上,來通過卷積層和池化層抽取的特徵執行分類任務。然而,在連線到網路上前,我們需要格式化我們的特徵對映到結構[batch_size, features],如此,我們的張量就只有二維了:
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
在上面的reshape()運算,-1指batch_size維度將被動態計算,根據我們輸入資料樣例的數量。每個樣例都有7(pool2寬)*7(pool2高)*64(pool2通道)個特徵,因此特徵維度為:7*7*64(3136總共)。輸出張量pool2_flat有結構[batch_size, 3136].
現在我們可以用layers中的dense()方法連線我們的全連線層,如下:
dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu)
- inputs引數指定輸入張量:我們格式化的特徵對映pool2_flat.
- units引數為全連線層神經元節點的個數(1024)。
- activation,我們依然使用ReLU啟用函式。
為了提高模型的結果,我們應用dropout把我們的全連線層歸一化:
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == learn.ModeKeys.TRAIN)
inputs引數,輸入張量,為我們全連線層的輸出張量。rate引數指定丟棄率,我們指定0.4,意思為在訓練期間,將會隨機丟棄40%的元素。training引數是一個布林值,指模型現在是否在訓練模式。dropout將只有training是True時才執行。
我們的輸出張量dropout結構為:[batch_size, 1024]。
邏輯層(Logits Layer)
我們神經網路的最後一層是邏輯層,這層會返回我們的預測原始結果值。我們建立一個10個神經元(每一個對應0-9的每個目標類)的全連線層,使用線性啟用函式(預設):
logits = tf.layers.dense(inputs=dropout, units=10)
CNN的最後的輸出張量,logits結構為:[batch_size, 10]
計算損失率(Loss)
對於訓練和驗證,我們都需要定義一個損失函式來測量預測結果與目標類的匹配度。對於像MNIST這樣的多分類問題,交叉熵(cross entropy)通常被用在損失測量中。下面程式碼計算當執行模式為TRAIN或EVAL時的交叉熵。
loss = None
train_op = None
# Calculate loss for both TRAIN and EVAL modes
if mode != learn.ModeKeys.INFER:
onehot_labels = tf.one_hot(indices=tf.cast(labels, tf.int32), depth=10)
loss = tf.losses.softmax_cross_entropy(
onehot_labels=onehot_labels, logits=logits)我們的labels張量包含了我們樣例的預測列表,例如:[1, 9, ...],為了計算交叉熵,首先,我們需要轉換labels為相應的one-hot編碼。
[[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
...]我們使用tf.one_hot函式執行轉換操作,有兩個必須的引數:
- indices:在one-hot張量中有值的位置。–例如上述1值的位置。
- depth:one-hot張量的深度。–例如目標類的數量,這裡我們是10。
下面的程式碼建立一個one-hot張量為我們的labels
onehot_labels = tf.one_hot(indices=tf.cast(labels, tf.int32), depth=10)
tf.losses.softmax_cross_entropy()把onehot_labels和logits作為引數,在logits上執行softmax啟用,計算交叉熵,並且返回我們的損失,為一個scalar張量:
loss = tf.losses.softmax_cross_entropy(
onehot_labels=onehot_labels, logits=logits)
配置訓練引數
在上面部分,我們定義CNN的損失為logits層和標籤(Labels)的softmax交叉熵。讓我們配置我們的模型在訓練期間讓損失值可選,使用tf.contrib.layers中的tf.contrib.layers.optimize_loss函式,我們將用一個0.001的學習率和隨機梯度下降(stochastic gradient descent ) 作為選擇演算法:
# Configure the Training Op (for TRAIN mode)
if mode == learn.ModeKeys.TRAIN:
train_op = tf.contrib.layers.optimize_loss(
loss=loss,
global_step=tf.contrib.framework.get_global_step(),
learning_rate=0.001,
optimizer="SGD")產生預測結果
我們模型的邏輯層( logits layer)返回預測結果原始值張量,結構為:[batch_size, 10]。讓我們轉換這些原始結果為兩種我們的模型函式能夠返回的不同的格式:
- 每個樣例的預測類別:0-9間的一個數字
- 每個樣例的每個可能的目標類的概率。
對於每一個給定的樣例,我們的預測類別是在logits張量相應行的最高原始值的元素。我們能夠知道這個元素的索引,用如下的函式:
tf.argmax(input=logits, axis=1)
input引數指從張量中抽取的最大值,這裡是logits。axis引數指沿著input張量找到的最大值的軸,這裡我們最大值的維度是1,這對應於我們的預測
我們能夠從我們的邏輯層匯出概率值,通過應用softmax 啟用 tf.nn.softmax:
tf.nn.softmax(logits, name="softmax_tensor")
我們在字典中編譯我們的預測,如下:
predictions = {
"classes": tf.argmax(
input=logits, axis=1),
"probabilities": tf.nn.softmax(
logits, name="softmax_tensor")
}# Return a ModelFnOps object
return model_fn_lib.ModelFnOps(
mode=mode, predictions=predictions, loss=loss, train_op=train_op)
訓練和驗證CNN MNIST 分類器
我們已經編寫好我們的MNIST CNN模型函式,現在我們可以訓練並驗證它。
載入訓練和測試資料
首先我們載入訓練和測試資料,增加main()函式到cnn_mnist.py:
def main(unused_argv):
# Load training and eval data
mnist = learn.datasets.load_dataset("mnist")
train_data = mnist.train.images # Returns np.array
train_labels = np.asarray(mnist.train.labels, dtype=np.int32)
eval_data = mnist.test.images # Returns np.array
eval_labels = np.asarray(mnist.test.labels, dtype=np.int32)我們儲存訓練特徵資料(55000張圖片的手寫數字的原畫素值)和訓練標籤(每張圖片對應0-9中的一個值)作為numpy arrays在train_data和train_labels中。同樣,我們儲存驗證特徵資料(1000張圖片)和驗證標籤ineval_data和eval_labels。
建立Estimator
讓我們建立一個Estimator(一個TensorFlow的類,用於執行高維模型訓練,驗證,和介面),對於我們的模型,增加如下程式碼到main():
# Create the Estimator
mnist_classifier = learn.Estimator(
model_fn=cnn_model_fn, model_dir="/tmp/mnist_convnet_model")model_fn引數指用於訓練、驗證、介面的模型函式,我們傳遞在”Building the CNN MNIST Classifier”中建立的cnn_model_fn給它。model_dir引數指定模型資料(checkpoints)將被儲存的目錄(根據需要更換自己的目錄)
設定日誌
CNNs需要花費一段時間來訓練,在訓練時我們可以設定一些日誌用於我們跟蹤程式執行。我們可以用tf.train.SessionRunHook來建立一個tf.train.LoggingTensorHook,它能夠記錄我們CNN的softmax層的可能值。增加如下程式碼到main():
# Set up logging for predictions
tensors_to_log = {"probabilities": "softmax_tensor"}
logging_hook = tf.train.LoggingTensorHook(
tensors=tensors_to_log, every_n_iter=50)我們建立了一個記錄張量的字典在tensors_to_log。每一個key都是我們選擇的標籤,這些標籤將被列印在log輸出裡。並且相應的標籤是TensorFlow圖中一個張量的名字。這裡,我們的probabilities能夠被找到在softmax_tensor中,我們給softmax運算的名字要在我們生成概率之前。
接著,我們建立LoggingTensorHook,傳遞tensors_to_log給tensors引數。我們設定every_n_iter=50,這個值指訓練每50步記錄一下概率值。
訓練模型
下面呼叫fit函式來訓練我們的模型,新增如下程式碼到main:
# Train the model
mnist_classifier.fit(
x=train_data,
y=train_labels,
batch_size=100,
steps=20000,
monitors=[logging_hook])在fit呼叫中,我們傳遞訓練特徵資料給標籤x和y。
- batch_size=100:指模型每步將會在100個樣例的小集合上訓練
- steps=20000:模型總共訓練20000步。
- monitors:我們傳遞logging_hook給它,以便在訓練時能夠觸發。
驗證模型
訓練完成,我們想驗證我們模型在測試集上的準確率,我們需要建立一個指標詞典,用tf.contrib.learn.MetricSpec,它能計算準確率,增加下面程式碼到main:
# Configure the accuracy metric for evaluation
metrics = {
"accuracy":
learn.MetricSpec(
metric_fn=tf.metrics.accuracy, prediction_key="classes"),
}metric_fn引數,計算並返回指標的函式。這裡我們用在tf.metrics模組中的accuracy函式。prediction_key引數,張量的key,這個張量是模型函式返回的預測值,這裡,我們用前面建立的分類模型的預測keyclasses。
下面我們可以驗證我們的模型了,增加如下程式碼,會驗證並列印結果:
# Evaluate the model and print results
eval_results = mnist_classifier.evaluate(
x=eval_data, y=eval_labels, metrics=metrics)
print(eval_results)執行模型
我們已經編寫完CNN的模型函式、Estimator和訓練驗證邏輯,讓我們看結果,執行cnn_mnist.py
模型訓練後,我們將會看到到日誌輸出如下所示:
INFO:tensorflow:loss = 2.36026, step = 1
INFO:tensorflow:probabilities = [[ 0.07722801 0.08618255 0.09256398, ...]]
...
INFO:tensorflow:loss = 2.13119, step = 101
INFO:tensorflow:global_step/sec: 5.44132
...
INFO:tensorflow:Loss for final step: 0.553216.
INFO:tensorflow:Restored model from /tmp/mnist_convnet_model
INFO:tensorflow:Eval steps [0,inf) for training step 20000.
INFO:tensorflow:Input iterator is exhausted.
INFO:tensorflow:Saving evaluation summary for step 20000: accuracy = 0.9733, loss = 0.0902271
{'loss': 0.090227105, 'global_step': 20000, 'accuracy': 0.97329998}這裡我們在測試集上達到了97.3%的準確率。
額外資料
想學習更多的TensorFlow Estimators and CNNs,可以看如下連結:
- Creating Estimators in tf.contrib.learn.: TensorFlow Estimator API的引言,我們會學習到如何配置一個Estimator,寫一個模型函式,計算loss,定義一個訓練過程。
- Deep MNIST for Experts: Building a Multilayer CNN.:學習如何構建一個MNIST CNN分類模型,沒有layers ,使用低水平的TensorFlow 運算。