
hive官方文件翻譯
概念
Hive是什麼
Hive是一個基於Apache Hadoop的資料倉庫。對於資料儲存與處理,Hadoop提供了主要的擴充套件和容錯能力。
Hive設計的初衷是:對於大量的資料,使得資料彙總,查詢和分析更加簡單。它提供了SQL,允許使用者更加簡單地進行查詢,彙總和資料分析。同時,Hive的SQL給予了使用者多種方式來整合自己的功能,然後做定製化的查詢,例如使用者自定義函式(User Defined Functions,UDFs).
Hive不適合做什麼
Hive不是為線上事務處理而設計。它最適合用於傳統的資料倉庫任務。
Getting Started
對於Hive, HiveServer2 和Beeline的設定詳情,請參考指南。
對於學習Hive,這些書單可能對你有所用處。
以下部分提供了一個關於Hive系統功能的教程。先描述資料型別,表和分割槽的概念,然後使用例子來描述Hive的功能。
資料單元
根據顆粒度的順序,Hive資料被組織成:
- 資料庫:名稱空間功能,為了避免表,檢視,分割槽,列等等的命名衝突。資料庫也可以用於加強使用者或使用者組的安全。
-
表:相同資料庫的同類資料單元。例如表
page_views,表的每行包含以下列:- timestamp -這是一個
INT型別,是當頁面被訪問時的UNIX時間戳。 - userid -這是一個
BIGINT型別,用於惟一識別訪問頁面的使用者。 - page_url -這是一個
STRING型別,用於儲存頁面地址。 - referer_url -這是一個
STRING型別,用於儲存使用者是從哪個頁面跳轉到本頁面的地址。 - IP -這是一個
STRING型別,用於儲存頁面請求的IP地址。
- timestamp -這是一個
-
分割槽:每個表可以有一個或多個用於決定資料如何儲存的分割槽鍵。分割槽(除儲存單元之外)也允許使用者有效地識別滿足指定條件的行;例如,
STRING型別的date_partition和STRING的country_partition。這些分割槽鍵的每個惟一的值定義了表的一個分割槽。例如,所有的“2009-12-23”日期的“US”資料是表page_views的一個分割槽。(注意區分,分割槽鍵與分割槽,如果分割槽鍵有兩個,每個分割槽鍵有三個不同的值,則共有6個分割槽)。因此,如果你只在日期為“2009-12-23”的“US”資料上執行分析,你將只會在表的相關資料上執行查詢,這將有效地加速分析。然而要注意,那僅僅是因為有個分割槽叫2009-12-23,並不意味著它包含了所有資料,或者說,這些資料僅僅是那個日期的資料。使用者需要保證分割槽名字與資料內容之間的關係。分割槽列是虛擬列,它們不是資料本身的一部分,而是源於資料載入。 -
桶(Buckets or Clusters):每個分割槽的資料,基於表的一些列的雜湊函式值,又被分割成桶。例如,表
page_views可能通過userid分成桶,userid是表page_view的一個列,不同於分割槽列。這些桶可以被用於有效地抽樣資料。
型別系統
Hive支援原始型別和復要型別,如下所述,檢視Hive Data Types
原始型別
- 型別與表的列相關。支援以下原始型別:
- Integers(整型)
- TINYINT -1位的整型
- SMALLINT -2位的整型
- INT -4位的整型
- BIGINT -8位的整型
- 布林型別
- BOOLEAN -TRUE/FALSE
- 浮點數
- FLOAT -單精度
- DOUBLE -雙精度
- 定點數
-DECIMAL -使用者可以指定範圍和小數點位數 - 字串
-STRING -在特定的字符集中的一個字串序列
-VARCHAR -在特定的字符集中的一個有最大長度限制的字串序列
-CHAR -在特定的字符集中的一個指定長度的字串序列 - 日期和時間
-TIMESTAMP -一個特定的時間點,精確到納秒。
-DATE -一個日期 - 二進位制
-BINARY -一個二進位制位序列
複雜型別
複雜型別可以由原始型別和其他組合型別構建:
- 結構體型別(Stuct): 使用點(.)來訪問型別內部的元素。例如,有一列c,它是一個結構體型別{a INT; b INT},欄位a可以使用表示式c.a來訪問。
- Map(key-value鍵值對):使用['元素名']來訪問元素。例如,有一個MapM,包含'group'->gid的對映,則gid的值可以使用M['group']來訪問。
- 陣列:陣列中的元素是相同的型別。可以使用[n]來訪問陣列元素,n是陣列下標,以0開始。例如有一個數組A,有元素['a','b','c'],則A[1]返回'b'。
內建運算子和函式
Hive所有關鍵詞的大小寫都不敏感,包括Hive運算子和函式的名字。
內建運算
- 關係運算
- 數學運算
- 邏輯運算
- 複雜型別的運算




內建函式
- Hive支援以下內建函式
- Hive支援以下內建聚合函式
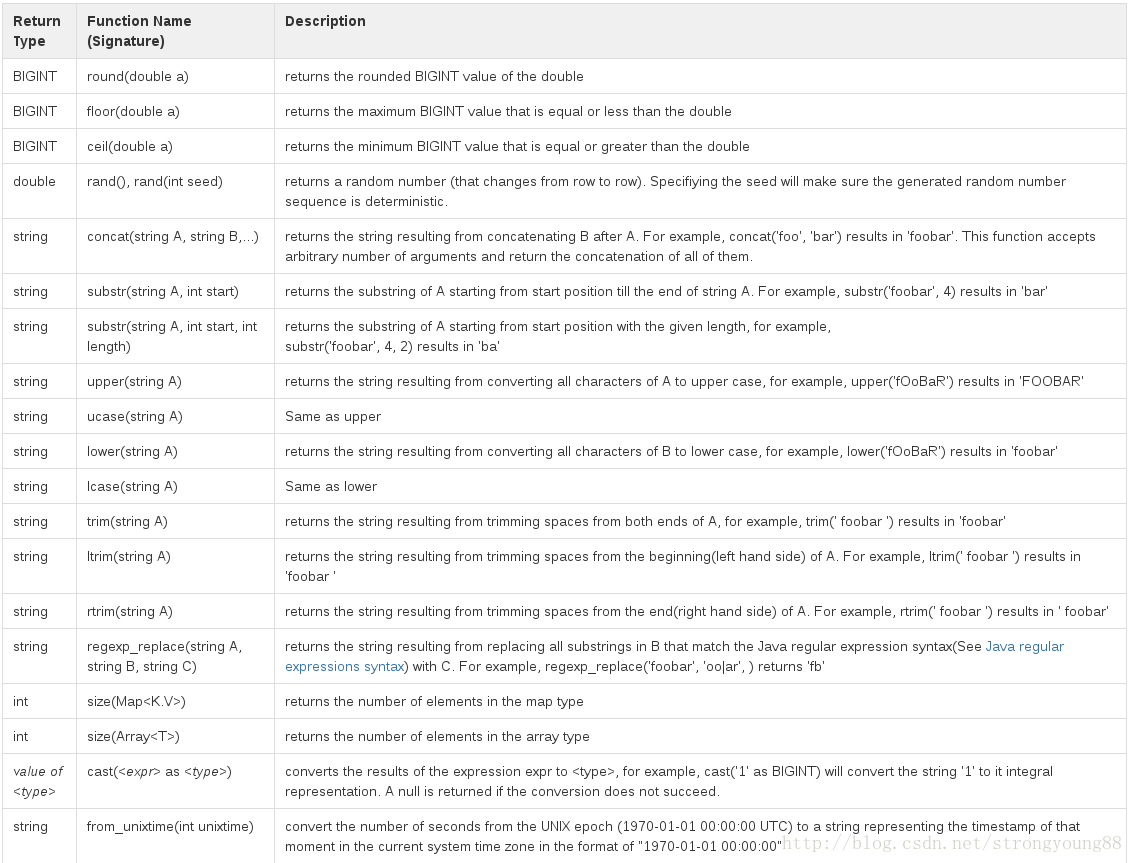


語言能力
Hive’s SQL提供了基本的SQL操作。這些操作工作於表或分割槽上。這些操作是:
- 可以使用WHERE從表中篩選行
- 可以使用SELECT從表中查詢指定的列
- 兩個表之間可以join
- 可以在多個group by的列上使用聚合
- 可以儲存查詢結構到另一個表
- 可以下載表的內容到本地目錄
- 可以儲存查詢結果到hadoop的分散式檔案系統目錄上
- 可以管理表和分割槽(建立,刪除和修改)
- 可以使用自定義的指令碼,來定製map/reduce作業
使用和例項
以下的例子有一些不是最新的,更多最新的資訊,可以參考LanguageManual。
以下的例子強調了Hive系統的顯著特徵。詳細的查詢測試用例和相應的查詢結果可以在Hive Query Test Cases’上找到。
- 建立,顯示,修改,和刪除表
- 載入資料
- 查詢和插入資料
建立,顯示,修改,和刪除表
建立表
以下例子建立表page_view:
- 1
- 2
- 3
- 4
- 5
- 6
在這個例子中,表的列被指定相應的型別。備註(Comments)可以基於列級別,也可以是表級別。另外,使用PARTITIONED關鍵詞定義的分割槽列與資料列是不同的,分割槽列實際上不儲存資料。當使用這種方式建立表的時候,我們假設資料檔案的內容,欄位之間以ASCII 001(ctrl-A)分隔,行之間以換行分隔。
如果資料不是以上述格式組織的,我們也可以指定分隔符,如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
目前,行分隔符不能指定,因為它不是由Hive決定,而是由Hadoop分隔符。
對錶的指定列進行分桶,是一個好的方法,它可以有效地對資料集進行抽樣查詢。如果沒有分桶,則會進行隨機抽樣,由於在查詢的時候,需要掃描所有資料,因此,效率不高。以下例子描述了,在表page_view的userid列上進行分桶的例子:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
以上例子,通過一個userid的雜湊函式,表被分成32個桶。在每個桶中的資料,是以viewTime升序進行儲存。這樣組織資料允許使用者有效地在這n個桶上進行抽樣。合適的排序使得內部操作充分利用熟悉的資料結構來進行更加有效的查詢。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在這個例子,CLUSTERED BY指定列進行分桶,以及建立多少個桶。行格式分隔符指定在hive表中,行如何儲存。在這種分隔符情況下,指定了欄位是如何結束,集合項(陣列和map)如何結束,以及map的key是如何結束的。STORED
AS SEQUENCEFILE表示這個資料是以二進位制格式進行儲存資料在hdfs上。對於以上例子的ROW FORMAT的值和STORED
AS表示系統預設值。
表名和列名不區分大小寫。
瀏覽表和分割槽
- 1
列出資料庫裡的所有的表,也可以這麼瀏覽:
- 1
這樣將會列出以page開頭的表,模式遵循Java正則表示式語法。
- 1
列出表的分割槽。如果表沒有分割槽,則丟擲錯誤。
- 1
列出表的列和列的型別。
- 1
列出表的列和表的其他屬性。這會列印很多資訊,且輸出的風格不是很友好,通常用於除錯。
- 1
列出列和分割槽的所有屬性。這也會打印出許多資訊,通常也是用於除錯。
修改表
對已有的表進行重新命名。如果表的新名字存在,則報錯:
- 1
對已有表的列名進行重新命名。要確保使用相同的列型別,且要包含對每個已存在列的一個入口(也就是說,就算不修改其他列的列名,也要把此列另上,否則,此列會丟失)。
- 1
對已有表增加列:
- 1
注意:
模式的改變(例如增加列),保留了表的老分割槽,以免它是一個分割槽表。所有對這些列或老分割槽的查詢都會隱式地返回一個null值或這些列指定的預設值。
刪除表和分割槽
刪除表是相當,表的刪除會刪除已經建立在表上的任意索引。相關命令是:
- 1
要刪除分割槽。修改表刪除分割槽:
- 1
注意:此表或分割槽的任意資料都將被刪除,而且可能無法恢復。
載入資料
要載入資料到Hive表有許多種方式。使用者可以建立一個“外部表”來指向一個特定的HDFS路徑。用這種方法,使用者可以使用HDFSput或copy命令,複製一個檔案到指定的位置,並且附上相應的行格式資訊建立一個表指定這個位置。一旦完成,使用者就可以轉換資料和插入他們到任意其他的Hive表中。例如,如果檔案/tmp/pv_2016-06-08.txt包含逗號分隔的頁面訪問記錄。這需要以合適的分割槽載入到表page_view,以下命令可以完成這個目標:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
其中,‘44’是逗號的ASCII碼,‘12’是換頁符(NP from feed,new page)。null是作為目標表中的陣列和map型別插入,如果指定了合適的行格式,這些值也可以來自外部表。
如果在HDFS上有一些歷史資料,使用者想增加一些元資料,以便於可以使用Hive來查詢和操縱這些資料,這個方法是很有用的。
另外,系統也支援直接從本地檔案系統上載入資料到Hive表。表的格式與輸入檔案的格式需要相同。如果檔案/tmp/pv_2016-06-08包含了US資料,然後我們不需要像前面例子那樣的任何篩選,這種情況的載入可以使用以下語法完成:
- 1
路徑引數可以是一個目錄(這種情況下,目錄下的所有檔案將被載入),一個檔案,或一個萬用字元(這種情況下,所有匹配的檔案會上傳)。如果引數是目錄,它不能包含子目錄。同樣,萬用字元只匹配