
機器學習Tensorflow基本操作:執行緒佇列影象
二、讀取資料
小數量資料讀取
這僅用於可以完全載入到儲存器中的小的資料集有兩種方法:
- 儲存在常數中。
- 儲存在變數中,初始化後,永遠不要改變它的值。
使用常數更簡單一些,但是會使用更多的記憶體,因為常數會內聯的儲存在資料流圖資料結構中,這個結構體可能會被複制幾次。
training_data = ...
training_labels = ...
with tf.Session():
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
要改為使用變數的方式,您就需要在資料流圖建立後初始化這個變數。
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initalizer, trainable=False 設定trainable=False可以防止該變數被資料流圖的GraphKeys.TRAINABLE_VARIABLES收集,這樣我們就不會在訓練的時候嘗試更新它的值;設定collections=[]可以防止GraphKeys.VARIABLES收集後做為儲存和恢復的中斷點。設定這些標誌,是為了減少額外的開銷
檔案讀取
先看下檔案讀取以及讀取資料處理成張量結果的過程:
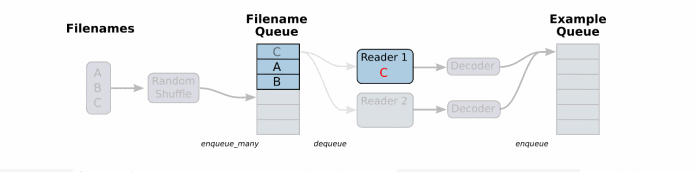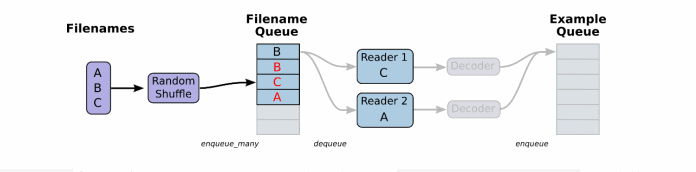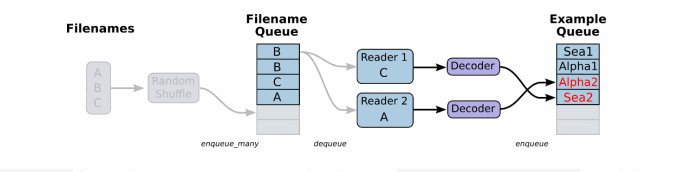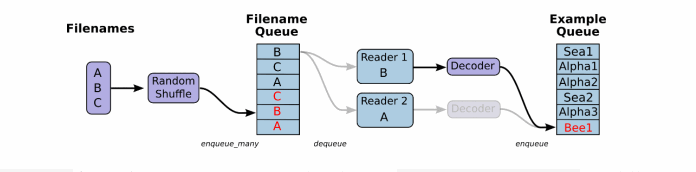
一般資料檔案格式有文字、excel和圖片資料。那麼TensorFlow都有對應的解析函式,除了這幾種。還有TensorFlow指定的檔案格式。
標準TensorFlow格式
TensorFlow還提供了一種內建檔案格式TFRecord,二進位制資料和訓練類別標籤資料儲存在同一檔案。模型訓練前影象等文字資訊轉換為TFRecord格式。TFRecord檔案是protobuf格式。資料不壓縮,可快速載入到記憶體。TFRecords檔案包含 tf.train.Example protobuf,需要將Example填充到協議緩衝區,將協議緩衝區序列化為字串,然後使用該檔案將該字串寫入TFRecords檔案。在影象操作我們會介紹整個過程以及詳細引數。
資料讀取實現
檔案佇列生成函式
- tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, name=None)
產生指定檔案張量
檔案閱讀器類
- class tf.TextLineReader
閱讀文字檔案逗號分隔值(CSV)格式
- tf.FixedLengthRecordReader
要讀取每個記錄是固定數量位元組的二進位制檔案
- tf.TFRecordReader
讀取TfRecords檔案
解碼
由於從檔案中讀取的是字串,需要函式去解析這些字串到張量
tf.decode_csv(records,record_defaults,field_delim = None,name = None)將CSV轉換為張量,與tf.TextLineReader搭配使用
tf.decode_raw(bytes,out_type,little_endian = None,name = None) 將位元組轉換為一個數字向量表示,位元組為一字串型別的張量,與函式tf.FixedLengthRecordReader搭配使用
生成檔案佇列
將檔名列表交給tf.train.string_input_producer函式。string_input_producer來生成一個先入先出的佇列,檔案閱讀器會需要它們來取資料。string_input_producer提供的可配置引數來設定檔名亂序和最大的訓練迭代數,QueueRunner會為每次迭代(epoch)將所有的檔名加入檔名佇列中,如果shuffle=True的話,會對檔名進行亂序處理。一過程是比較均勻的,因此它可以產生均衡的檔名佇列。
這個QueueRunner工作執行緒是獨立於檔案閱讀器的執行緒,因此亂序和將檔名推入到檔名佇列這些過程不會阻塞檔案閱讀器執行。根據你的檔案格式,選擇對應的檔案閱讀器,然後將檔名佇列提供給閱讀器的 read 方法。閱讀器的read方法會輸出一個鍵來表徵輸入的檔案和其中紀錄(對於除錯非常有用),同時得到一個字串標量,這個字串標量可以被一個或多個解析器,或者轉換操作將其解碼為張量並且構造成為樣本。
# 讀取CSV格式檔案
# 1、構建檔案佇列
# 2、構建讀取器,讀取內容
# 3、解碼內容
# 4、現讀取一個內容,如果有需要,就批處理內容
import tensorflow as tf
import os
def readcsv_decode(filelist):
"""
讀取並解析檔案內容
:param filelist: 檔案列表
:return: None
"""
# 把檔案目錄和檔名合併
flist = [os.path.join("./csvdata/",file) for file in filelist]
# 構建檔案佇列
file_queue = tf.train.string_input_producer(flist,shuffle=False)
# 構建閱讀器,讀取檔案內容
reader = tf.TextLineReader()
key,value = reader.read(file_queue)
record_defaults = [["null"],["null"]] # [[0],[0],[0],[0]]
# 解碼內容,按行解析,返回的是每行的列資料
example,label = tf.decode_csv(value,record_defaults=record_defaults)
# 通過tf.train.batch來批處理資料
example_batch,label_batch = tf.train.batch([example,label],batch_size=9,num_threads=1,capacity=9)
with tf.Session() as sess:
# 執行緒協調員
coord = tf.train.Coordinator()
# 啟動工作執行緒
threads = tf.train.start_queue_runners(sess,coord=coord)
# 這種方法不可取
# for i in range(9):
# print(sess.run([example,label]))
# 列印批處理的資料
print(sess.run([example_batch,label_batch]))
coord.request_stop()
coord.join(threads)
return None
if __name__=="__main__":
filename_list = os.listdir("./csvdata")
readcsv_decode(filename_list)
每次read的執行都會從檔案中讀取一行內容,注意,(這與後面的圖片和TfRecords讀取不一樣),decode_csv操作會解析這一行內容並將其轉為張量列表。如果輸入的引數有缺失,record_default引數可以根據張量的型別來設定預設值。在呼叫run或者eval去執行read之前,你必須呼叫tf.train.start_queue_runners來將檔名填充到佇列。否則read操作會被阻塞到檔名佇列中有值為止。