hao—C++和Java從編譯到執行的過程區別
以下內容純屬臆測,沒有科學依據,也不想(沒空)翻看權威資料。
一、C++編譯和執行過程
1、C++每個編譯單元整體上看都是各種宣告和定義
C++編譯單元就是指每個cpp檔案,整體上看(全域性的東西,函式內部不算,類定義內部不算)無非就是變數(包括類的例項也算變數)、函式或者類的宣告和定義。其中變數佔用記憶體空間,存放在執行時的“全域性區”,這個記憶體空間的資料一般是可變的,可以隨時被修改;函式(體)不佔用記憶體空間(本質上也佔用,因其編譯完後變成一堆永遠不變的純用來執行的程式碼或稱指令,而且佔用空間較少,哪怕很大的程式編譯完後純程式碼也不大,所以討論時常常認為其不佔用空間),存放在“程式碼區”,其內容永不被改變;類(體)沒有專門的存放區,因為在執行時根本不存在類了(純個人愚見),就像基本型別int一樣,任何型別在執行期都不起作用了,執行時本質(或者說全部的工作)就是“從某塊記憶體讀資料進入cpu,或者把cpu的資料存放入某塊記憶體,或者cpu內部進行運算”,任何型別只在編譯期有用,被編譯器用來進行錯誤檢查等,防止不同型別的變數混雜使用,防止出現一些非常難查詢的異常,所以說類體只在編譯時有用,被編譯器使用,把函式內用到的類的成員翻譯成一個個帶有複姓的長名字,如類名.成員名,其中碰到new 類名時,就翻譯成呼叫類的建構函式(對執行期來說就是一個地址而已),總之類的成員(非靜態,靜態的東西本質就是全域性的)不可能出現在全域性定義的地方,也即不可能存放在全域性區,當然可以在全域性的地方定義一個類的例項,編譯器對待他和對待普通變數沒什麼區別,只不過佔用的記憶體空間稍微大了些而已。
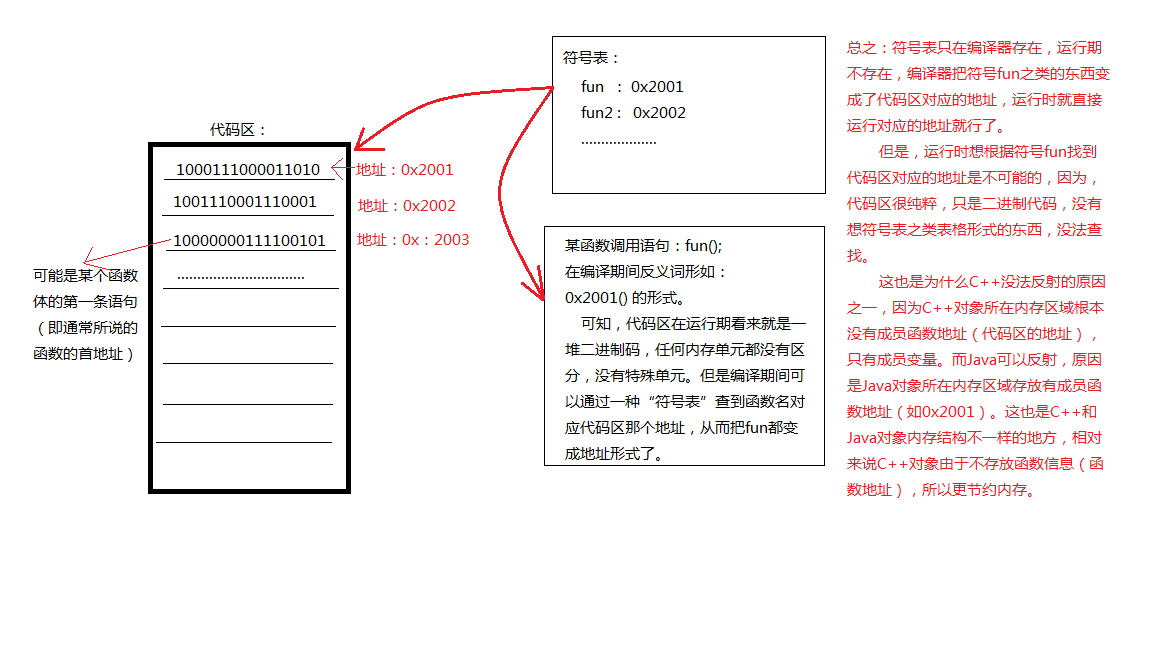
2、符號表的作用(編譯和連結過程)
先看編譯過程,C++編譯器使用符號表,執行時就不用符號表了。符號表簡單理解為具有三列的表格(符號名、型別、內容),只有變數、函式和類能進入符號表中,其中型別列對於變數來說是描述該符號怎麼分配記憶體和初始化,型別列對於類來說就是類裡面含有什麼成員,怎麼進行成員初始化,內容列對於變數來說就是變數存放的具體資料(包括物件變數也是),內容列對於函式來說就是函式程式碼體的首地址,內容列對於類來說是空的,不用的。C++編譯每個檔案時,第一步從整體上掃描,無非就是宣告和定義,把所有定義的東西都裝進那個.cpp檔案對應的符號表,就產生了符號表;第二步進行區域性掃描,也稱錯誤檢查,首先進行符號檢查,就是掃描函式體和類體,碰到不認識的符號,先看該符號有沒有在本cpp檔案宣告,如果聲明瞭就把當前符號記錄成問號(如 普通變數x和物件變數stu翻譯如下,x = 15翻譯成x? = 15,stu.no =10 0翻譯成stu?.第三個記憶體單元 = 100),如果符號沒事先宣告,也不在本cpp的符號表裡頭,那就報錯;然後對函式體和類體進行語法錯誤檢查,看看有沒有錯誤的地方;第三步是進行翻譯成機器語言,例如把函式名翻譯成地址,變數名也翻譯成地址等;其中最重要的就是可能把一行的文字程式碼翻譯成很多行的機器程式碼,例如碰到函式體內使用到new一個類則查詢建構函式然後翻譯成一堆對物件成員的分配記憶體指令,碰到使用物件成員變數時翻譯成從物件變數首地址開始下移多少個位置才取出具體的資料;另外要注意碰到new的地方都依據符號表的型別列翻譯成具體的分配記憶體和初始化的指令(彙編有具體的指令集,不僅是new,變數定義語句也如此翻譯)。總之經過上面三步過程,編譯就算完了,其最終結果就是產生了一個符號表和一個.obj檔案,其中符號表裡都是該cpp檔案中定義的全域性的東西(變數定義、函式定義或者類定義),obj檔案都是函式體(特別注意只有函式體,沒有類體,類體中的函式本質也是函式體,只不過具有複姓而已,類體的成員變數此時無用了,已經都翻譯成某個物件成員便宜多少位地址形式的東西了,其本質就看成物件變數),該函式體就是所謂的指令,其中函式體裡面可能有一堆的含有問號的符號。
再看連結過程,連結時依然用到符號表,而且強烈依賴符號表,連結時第一步先掃描每個cpp檔案對應的obj檔案,碰到含問號的符號時就在所有的符號表裡查詢,找到後把符號對應的內容代替問號;第二步連結器把所有的obj檔案連結在一起形成一個大的obj(在記憶體中,這裡不考慮連結庫),把所有的符號表中變數的內容連在一起形成一個大的表(在記憶體中,函式和類都不用了);第三步是生存exe檔案,具體過程是先劃分出資料區和程式碼區(exe只有這兩部分),其中資料區存放符號表中定義的各種全域性的變數,程式碼區存放大obj的內容(即所有函式體的集合,注意只有函式體,即所有指令)。
3、執行過程
以後執行exe時,作業系統都是先根據exe的資料部分分配出全域性區(包括常量區),然後根據程式碼部分分配程式碼區,然後系統自己分配棧區和堆區,就可以開始運行了。
二、如何理解靜態聯編和動態聯編中的靜和動?
所謂靜態聯編就是指exe執行前(也稱編譯期)會起作用的語句,動態聯編實在執行期(main執行後開始算起)會起作用的語句。例如變數定義語句分兩種,全域性變數就是編譯器就起作用的語句,因為全域性變數在生成的exe檔案中已經被描述成全域性的東西了,exe檔案執行成程序的開始就會先產生全域性區,然後給全域性表裡分配記憶體,也就可以看出全域性變數定義語句在真正執行前(main函式執行前)就起作用了;而對於函式內的區域性變數,則屬於執行前起作用的語句。因此我們說函式過載都是靜態聯編,因為過載在編譯時就確定是哪個函數了,也即編譯時就翻譯成具體的確定了的函式地址了;而執行時的多型如Father *p=new children(); p.fun(); 中的fun函式執行的是子類的函式,原因是p.fun語句在編譯器僅僅進行語法錯誤檢查,根本就沒有真正執行(函式體裡的語句除了靜態變數定義外,全部都在執行期才起作用),而在執行期才真正起作用,所以是動態聯編。
三、宣告性語句、定義性語句和執行性語句
你會發現除了函式體內部的語句外,都是宣告性語句或定義性語句,所以我把整個程式碼分成這三類,其中函式體內部除了靜態變數定義外,都是執行性語句,而且執行性語句只會在函式體內部出現(包括類的成員函式體)。這裡說的執行性語句是指main函式開始後真正起作用的語句。需要注意的是函式裡面出現的new一個物件或者定義一個變數的語句早在編譯器就依據符號表的型別列翻譯成一堆分配記憶體和初始化指令了(彙編有具體的指令集),但是編譯器僅僅是把其翻譯成一堆機器指令,並明確了怎麼分配和初始化(任何變數包括類一定都是在編譯器就明確怎麼分配記憶體和初始化),並沒有真正在記憶體中分配記憶體,真正分配記憶體實在man執行後,執行到該程式碼時才起作用的,所以我也常常認為函式體內的變數定義性語句(包括new)是“半執行性語句”,因為好像彙編期間其也起了一點作用(雖然只是起到明確怎麼幹,但沒有真正幹)。
四、分析類在編譯器和執行期的作用
類在編譯器作用就看成是個模板,他本身自己不起任何作用,有用的是依據他建立的一個個物件的成員,編譯完成後,就完全不需要類了,而且編譯完成後的程式碼裡面沒有類,所有的物件都翻譯成一個變數的首地址,物件的成員都翻譯成相對於首地址的偏移地址。尤其是執行期起作用的僅僅是函式體內的程式碼,類就更不可能用到了,類的成員函式也早翻譯成複姓函式,跟類沒有關係,就跟普通函式一模一樣。所以類本質就是個模板,用來方便組織資料和行為,沒有他也一樣能做到,只不過有了它能使人不用考慮具體組織細節,而且更方便人們用面向物件思維思考問題,所以類是面向物件思維的一個實現工具,沒有類,一樣可以用別的方法實現面向物件思維。
五、java編譯和執行過程
1、java編譯和執行
Java編譯期和C++完全不一樣,他比C++簡單得多,也不會使用C++中的用於連線多個obj的符號表(填充多個obj中的問號符號)。java不存在連結,只有編譯,而且編譯也僅僅是把文字程式碼翻譯成位元組碼,其中最需要注意的就是,碰到import語句時,會把下面對於的類的前面加上包名,形成類的全名形式。
Java執行時先執行含有main函式的那個class位元組碼檔案,碰到第一次使用的類時,Java虛擬機器的類載入器才去載入那個類到記憶體中執行。
C++可不是這樣,C++執行時早就沒有類的概念了,所有的東西都變成和普通變數和普通函式沒什麼區別的東西了,而且類函式早就變成普通函式進入exe的程式碼區了,所以從程式碼量來看,C++中的類的程式碼即使沒執行到跟C++類有任何關聯的程式碼,C++類的程式碼也依然佔用記憶體(例如exe的程式碼區就包括了在類函式體裡定義的指令)。當然我們這裡討論的東西不包括C++的動態連結庫,實際上C++的動態連結庫使用了別的技術(從行為上來看動態連結庫更像java中的類載入器動態載入類的技術)。
2、Java類載入器作用(怎麼查詢類,涉及.java檔案中public 類原則)
Java類載入器(虛擬機器類載入器)在兩個階段分別起作用,在編譯階段或者執行階段,第一次碰到使用某個類時(注意不是import,import只是說明把一些符號加上覆姓而已),例如new一個類例項,或者宣告一個類例項等等,類載入器起作用,把該類載入進入記憶體,具體過程是根據父包名.子包名.類名,把其中的點號都變成斜槓,然後形成一個子目錄,附加到classpath父目錄後面,然後根據這個目錄查詢到類檔案並載入到記憶體中,一旦一個類已經載入到記憶體中,以後再用到該類時就不重複查詢和載入,直接使用記憶體中的類就可以了。
這也解釋了為什麼.java檔案中定義的每個類(包括內部類)都會生成一個以該類名作為檔名的.class檔案。這是因為便於類載入器查詢到這個類的具體定義,否則想想看,如果檔名不和類名一致,類載入器定位都類所在目錄後,由於不知道類在哪個檔案中,就需要把所有的檔案都開啟然後在每個檔案中查詢,效率肯定非常低下。
而且之所以Java規定一個.java檔案中最多隻能有一個public類,並且一旦含有public類,則該.java檔名必須和public類名一致(包括大小寫)是因為,只有public的類才會對其他包輸出並且很可能被多次用到(被多個其他包的類檔案用到),假設編譯A.java檔案,裡面含有public A類,而A類中有成員變數b,b是Class B型別的,那麼在編譯A.java檔案中的A類時就必須先編譯Class B才行,而此時還沒有形成B.class檔案,上哪檢視B類資訊呢,就必須查詢到某個.java檔案中的B類,對B類進行編譯,如果一個個開啟.java檔案查詢效率非常低下,而有了上述規定,就可以通過檔名B.java直接查詢到B類,效率就高了,而那些非public的類檔案由於一般只被本包中的類檔案用到,不會被其他包中類檔案用的,所以就不太可能經常去查詢它。
六、include和import的區別
有了上面的知識就容易分析兩者的區別了,include作用是在原地展開,import的作用僅僅是起到複姓的作用。c++中碰到include就會把標頭檔案內容原地展開,等於程式碼長度增加了。java中碰到import則表示下面的程式碼碰到某個符號時,在起前面加上覆姓,變成包.類名的形式。我認為import根本沒有起到目錄查詢的作用,因為import使得每個類都有複姓的形式,以後第一次載入該類的時候通過複姓在目錄中查詢就行了,所以import語句時根本就沒有查詢,只是在第一次載入類的時候才查詢。
七、怎麼理解類(本質)
無論是c++還是java,理解類時都把他看成一個型別,定義一個類時是產生了一個模板,通過類例項化時是產生了一堆成員,只不過這些成員在記憶體上是緊挨著的並且都具有複姓。總之,類就可以看成具有複姓的一堆成員而已。
八、C++動態連結庫
至於靜態連結庫,就理解為完全和cpp無任何區別,只不過提前把cpp編譯成二級制程式碼而已。
至於動態連結庫,本質就是一堆共享的變數和函式(注意沒有類,動態連結庫中到處的類本質是匯出加了複姓的變數和函式而已)。要輸出整個的類,對類使用_declspec(_dllexpot);要輸出類的成員函式,則對該函式使用_declspec(_dllexport)。其中匯出類就相當於在類的所有成員前面加上_declspec(_dllexport)。所以本質上根本沒有匯出類,匯出的都是成員,即使是例項化一個類例項,也是使用了匯出的構造方法而已。
所以可以推測動態連結庫實現方法大致如下:在原始檔中用的變數或函式或者類例項都在原始檔中留下了編譯成特定地址的符號,而在dll庫中含有相同的編譯成特定地址的符號,執行時碰到該地址就知道在dll的那個位置執行即可。
有關c++動態連結庫匯出類的詳細過程參加文章:http://blog.csdn.net/clever101/article/details/3034743
九、Java、C#與C++的區別(主要體現在執行時對類的處理上)
Java和C#都有執行時的類載入器,當執行時第一次用到某個類時,類載入器就會把該類載入進記憶體,所以使用起來非常簡單,類甚至也可以看成一個具體的物件或變數,對其進行處理,但是C++執行時根本就不存在類了,所以無法直接處理類,所以根本不存在反射機制等。
另外Java和C#在第一次載入類進記憶體時還是有區別的,在Java中類存在一個個的.class位元組碼檔案中,並且載入器根據類名的複姓查詢到位置並載入該類。而在C#中,沒對每個類生產單個類檔案(這是C#先進之處,避免產生大量的檔案),而是把多個類防止一個dll檔案中(此dll檔案稱為程式集),使用時在編譯器需要提前把用到的程式集引入到工程中(我猜測就是在生成的exe檔案中寫上用了哪些程式集),編譯時碰到不認識的符號就從引入的哪些程式集裡查詢,一旦找到就把對於的符號寫成“程式集名.名稱空間名.符號名”的形式,以後在執行期間第一次碰到“程式集名.名稱空間名.符號名”時就根據程式集名字在工作目錄中或System32目錄中動態載入該程式集進入記憶體,並從程式集中找到類資訊供類載入器使用。總之,Java是通過“名稱空間名.類名”來動態載入類(Java的包名就完全等價於名稱空間名,因為包名唯一作用就是複姓作用),而C#是通過“程式集名.名稱空間名.符號名”來動態載入類(就好像java中的一部分類打包成一個程式集並起個模組名,然後根據模組名.名稱空間名.類名訪問一樣,這樣加個層級可更好的分門別類的管理大量的類)。
最後補充一點,C#中的using 名稱空間名和Java的import作用是完全一模一樣的,都是僅僅起到複姓的作用,沒有其他任何作用,不要想複雜了。只不過import ss是在代表以下程式碼中出現的類名全部替換成ss,而using ss是代表下面程式碼不認識的符號前面自動加上ss作為姓。
十、【重要】C++和Java物件記憶體結構圖區別(有助於理解編譯過程和反射機制)
圖1,C++物件和Java物件記憶體佈局區別以及編譯和彙編表示如下:

圖2,C++物件和Java物件記憶體佈局區別(有無反射機制)如下: