
深度學習經典目標檢測例項分割語義分割網路的理解之二 RCNN
本篇主要剖析R-CNN網路架構,參考了幾篇優秀的博文!特別是@shenxiaolu1984 的目標檢測系列博文。
流程:
RCNN演算法分為4個步驟
- 一張影象生成1K~2K個候選區域
- 對每個候選區域,使用深度網路提取特徵
- 特徵送入每一類的SVM 分類器,判別是否屬於該類
- 使用迴歸器精細修正候選框位置
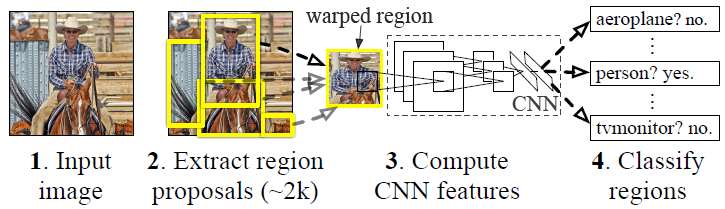
候選區域生成
這部分還參考了@guoyunfei20的一篇專門介紹selective search 的博文,非常棒:
使用了Selective Search1方法從一張影象生成約2000-3000個候選區域。
其步驟如下:

step1:計算區域集R裡每個相鄰區域的相似度S={s1,s2,…}
step2:找出相似度最高的兩個區域,將其合併為新集,新增進R
step3:從S中移除所有與step2中有關的子集
step4:計算新集與所有子集的相似度
step5:跳至step2,直至S為空
換句話說就是先使用一種過分割手段將影象分割成小區域,再合併可能性最高的兩個區域。重複直到整張影象合併成一個區域位置 輸出所有曾經存在過的區域,所謂候選區域候選區域生成和後續步驟相對獨立,實際可以使用任意演算法進行。
相似度計算
顏色、紋理、尺寸和空間交疊這4個引數。
顏色相似度(color similarity)
將色彩空間轉為HSV,每個通道下以bins=25計算直方圖,這樣每個區域的顏色直方圖有25*3=75個區間。 對直方圖除以區域尺寸做歸一化後使用下式計算相似度:
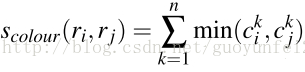
紋理相似度(texture similarity)
論文采用方差為1的高斯分佈在8個方向做梯度統計,然後將統計結果(尺寸與區域大小一致)以bins=10計算直方圖。直方圖區間數為8*3*10=240(使用RGB色彩空間)。

其中, 是直方圖中第
是直方圖中第 個bin的值。
個bin的值。
尺寸相似度(size similarity)

保證合併操作的尺度較為均勻,避免一個大區域陸續“吃掉”其他小區域。
例:設有區域a-b-c-d-e-f-g-h。較好的合併方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合併方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh。
交疊相似度(shape compatibility measure)


3.5、最終的相似度

多樣化與後處理
為儘可能不遺漏候選區域,上述操作在多個顏色空間中同時進行(RGB,HSV,Lab等)。在一個顏色空間中,使用上述四條規則的不同組合進行合併。所有顏色空間與所有規則的全部結果,在去除重複後,都作為候選區域輸出。
作者提供了Selective Search的原始碼,內含較多.p檔案和.mex檔案,難以細查具體實現。
最後的資料結構
一張輸入圖片,得到大概2K個候選框,有重疊的情況。結構維度(2000,x,y,w,h)
特徵提取
候選樣本預處理
使用深度網路提取特徵之前,首先把候選區域歸一化成同一尺寸227×227(Alexnet的輸入尺寸)。
此處有一些細節可做變化:外擴的尺寸大小,形變時是否保持原比例,對框外區域直接擷取還是補灰。會輕微影響效能。
預訓練
網路結構
基本借鑑Hinton 2012年在Image Net上的分類網路2,略作簡化3。 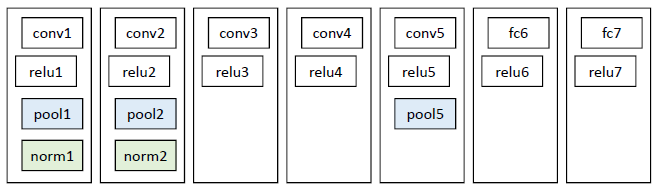
此網路提取的特徵為4096維,之後送入一個4096->1000的全連線(fc)層進行分類。
學習率0.01。
訓練資料
使用ILVCR 2012的全部資料進行訓練,輸入一張圖片,輸出1000維的類別標號。
調優訓練(fine turning)
網路結構
同樣使用上述網路,最後一層換成4096->21的全連線網路。
學習率0.001,每一個batch包含32個正樣本(屬於20類)和96個背景。
訓練資料
使用PASCAL VOC 2007的訓練集,輸入一張圖片,輸出21維的類別標號,表示20類+背景。
考察一個候選框和當前影象上所有標定框重疊面積最大的一個。如果重疊比例大於0.5,則認為此候選框為此標定的類別;否則認為此候選框為背景。
類別判斷
分類器
對每一類目標,使用一個線性SVM二類分類器進行判別。輸入為深度網路輸出的4096維特徵,輸出是否屬於此類。
由於負樣本很多,使用hard negative mining方法。 即大多數選擇出來的候選框都是背景其實。
正樣本
本類的真值標定框。
負樣本
考察每一個候選框,如果和本類所有標定框的重疊都小於0.3,認定其為負樣本
位置精修
目標檢測問題的衡量標準是重疊面積:許多看似準確的檢測結果,往往因為候選框不夠準確,重疊面積很小。故需要一個位置精修步驟。
迴歸器
對每一類目標,使用一個線性脊迴歸器進行精修。加入一個l2_norm的懲罰項(這部分我也不確定。。。正則項λ=10000λ=10000。 )
輸入為深度網路pool5層的4096維特徵,輸出為xy方向的縮放和平移。訓練樣本
判定為本類的候選框中,和真值重疊面積大於0.6的候選框。
這裡找到一個github的程式碼:https://github.com/broadinstitute/keras-rcnn 用Keras復現的。
參考文獻:- J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search for object recognition. IJCV, 2013. ↩
- A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012 ↩
- 所有層都是序列的。relu層為in-place操作,偏左繪製。 ↩
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩
- Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information Processing Systems. 2015. ↩