
重新理解SQL Server的聚集索引表與堆表
目錄
簡述SQL Server表的型別
由於當前關係型資料庫(RDBMS)種類繁多,存在對標準SQL(結構化查詢語言)實現上存在差異,對錶、索引的實現也各有不同,造成了大家對很多概念在理解上存在誤差。如下將描述MS SQL Server的聚集索引表與堆表,以便大家重新理解。
SQL Server只存在2種表:
聚集索引表(Clustered table)
堆表(Heap)
簡單的說,含有聚集索引(clustered index)的表即為聚集索引表,而堆表則是不含聚集索引的表。
注意:僅含有非聚集索引(Nonclustered index),而沒有聚集索引(clustered index)的表是堆表
如何區分聚集索引表與堆表
通過目錄檢視(catalog views)sys.partitions或sys.indexes可查詢表的型別:
--通過判斷index_id的值,區分表的型別
--當index_id為0時,則為堆表
--當index_id為1時,則為聚集索引表
SELECT
OBJECT_NAME(s.object_id) talbe_name
,CASE s.index_id
WHEN 0 THEN 'heap'
WHEN 1 THEN 'clustered table'
END table_type
FROM sys.partitions s
WHERE 使用目錄檢視sys.indexes查詢表的型別:
--注意:當表為堆表時,name為NULL
SELECT
OBJECT_NAME(object_id) table_name,
name,
type_desc
FROM sys.indexes
WHERE index_id <2注意:上述sql適用於所有的表。換言之,分割槽表也可使用上述sql進行判斷。
你可能好奇為何上述2個目錄檢視(sys.partitions或sys.indexes)可查詢所有表的型別(聚集索引表或堆表),那麼我們需簡單描述表與索引的組織結構,見下圖(圖片取自《Microsoft SQL Server 2008 Internals》)
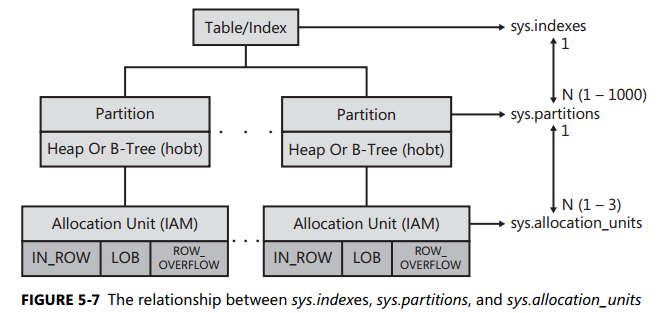
SQL Server是通過分割槽去管理與組織資料記錄的,且每個表至少存在一個分割槽,每個分割槽可對應一個檔案組(系統預設檔案組為PRIMARY)。換言之,可認為表的預設分割槽為PRIMARY。
聚集索引表與堆表的最大區別是:聚集索引表的資料在組織上是有序的,即聚集索引的有序性。而堆表是不含聚集索引的表。
注意:上述的組織結構是表或索引的儲存結構。在SQL Server現有的版本中,還無法對錶的單個分割槽建立索引(聚集或非聚集索引都不行)
簡而言之,目錄檢視sys.partitions與sys.indexes均存有索引的相關資訊,因此這兩個檢視查詢聚集索引的資訊,然後就可區分表的型別。
聚集索引表與堆表的正確使用
我們有很多理由去建立一個聚集索引表,而非堆表。那麼最大的理由可能就是:當一個非聚集索引包含的列不能完全符合一條查詢(select)時,執行計劃可通過聚集索引查詢,而非通過表掃描的方式。
那麼我們為什麼會選擇堆表,原因大致就如下2點:
1. 堆表沒有聚集索引,因此堆表可節省索引的磁碟空間
2. 堆表沒有聚集索引,且資料組織是無序的,節省了排序操作,寫入操作更快。
特別注意:在聚集索引索引表上建立分割槽時,務必檢查sql指令碼。若設定的分割槽函式指定的列不是聚集索引列,將會導致聚集索引的變化(刪除與重建),最終導致表的型別轉換。
參考資料
2.《Microsoft SQL Server 2008 Internals》