
大資料開發利器:Hadoop(11) Hadoop2 HA(High Availability)
本節主要介紹了HDFS HA(High Availability)的原理、主備切換過程以及基於JournalNode的共享儲存系統。
1. 前言
在當初介紹Hadoop2.0時,我們簡單提到了Hadoop框架中MapReduce的不足與改進。(即設計了新的資源管理框架YARN)。
那麼,Hadoop2.0針對HDFS在Hadoop1.0的存在的問題如何改進了呢?
HDFS在Hadoop1.0中主要存在以下兩個問題:
① 單一名稱節點,所以可能產生單點失效問題。
② 單一名稱節點,所以無法實現資源隔離。
所以針對HDFS以上兩個問題,Hadoop2.0進行以下改進:
① 設計了HDFS HA,提供名稱節點熱備機制。
② 設計了HDFS Federation,管理多個名稱空間。
本節主要對HDFS HA進行介紹。
2. HDFS HA(Availability)
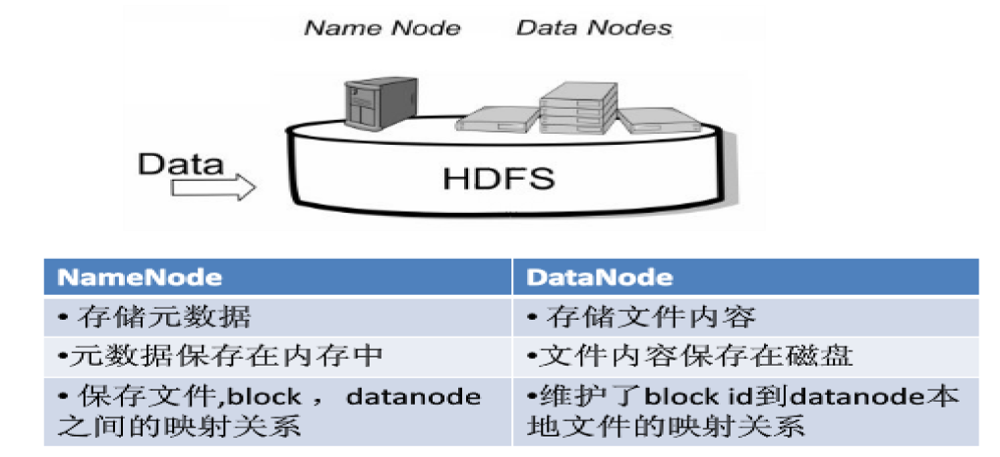
2.1 HDFS1.0 元件及其功能回顧
① Namenode
- 名稱節點
namenode負責管理分散式檔案系統的名稱空間namespace,儲存了兩個核心的資料結構:FsImage和EditLog。
- FsImage用於維護檔案系統樹以及檔案樹中所有檔案和資料夾的元資料。
- 操作日誌檔案EditLog中記錄了所有針對檔案的建立、刪除、重新命名等操作。
- 名稱節點記錄了每個檔案中各個塊所在的資料節點中的位置資訊。
② Datanode
- 資料節點
datanode是分散式檔案系統HDFS的工作節點,負責資料的儲存和讀取,會根據客戶端或者是名稱節點的排程來進行資料的儲存和檢索,並且向名稱節點定期傳送所儲存的塊的列表。 - 每個資料節點中的資料都會被儲存在各自節點的本地Liunx檔案系統中。
兩者功能如下圖:
2.2 HDFS 1.0 單點故障問題
HDFS執行原理如下圖:
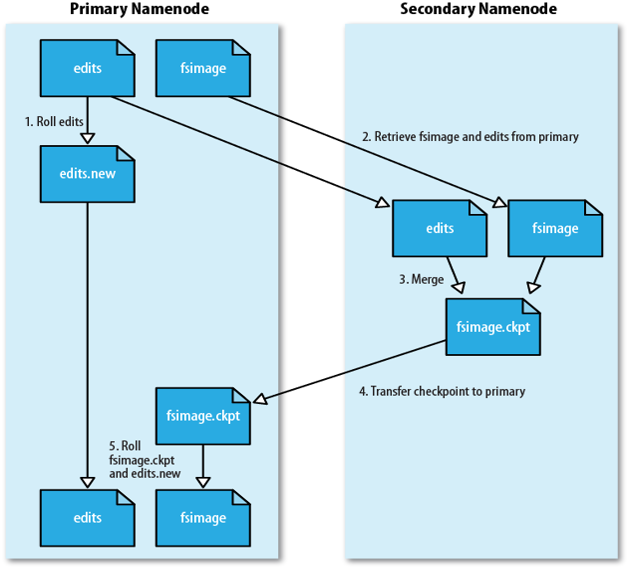
① 第二名稱節點SecondaryNameNode會定期和Namenode通訊。
② 從Namenode上獲取到FsImage和EditLog檔案,並下載到本地的相應目錄下。
③ 執行EditLog和FsImage檔案合併。
④ 將新的FsImage檔案傳送到Namenode節點上。
⑤ Namenode使用新的FsImage和EditLog(縮小了)。
所以,我們可以發現,SecondaryNameNode不是熱備份,主要是防止日誌檔案EditLog過大,導致名稱節點失敗恢復時消耗過多時間,同時附帶冷備份功能。
可以得出結論,SecondaryNameNode無法解決單點故障問題。
因此,HDFS2.0提供了HDFS HA的解決方案。
2.3 HDFS HA 原理
HDFS HA(High Availability)如其名,高可用性,是為了解決單點故障問題。
主要用以下方法進行解決:
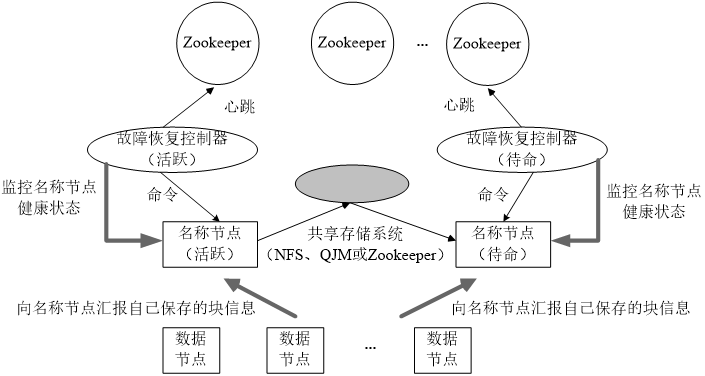
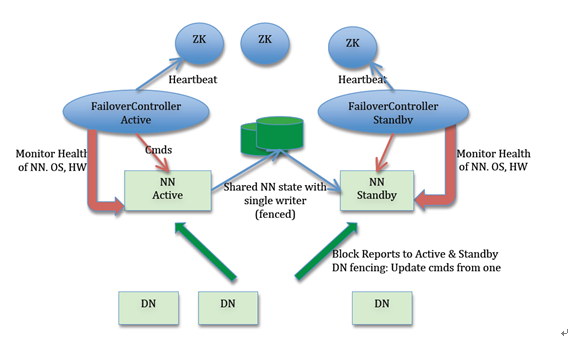
① HA叢集設定了兩個名稱節點:Active和Standby,即活躍和待命。
② 兩種名稱節點的狀態同步,可以藉助一個共享儲存系統來實現。
③ 一旦活躍名稱節點Active出現故障,就可以立即切換到待命名稱節點Standby。
④ Zookeeper確保一個名稱節點在對外服務。(主備切換控制)
⑤ 名稱節點維護對映資訊,資料節點同時向兩個名稱節點彙報資訊。
HDFS HA架構如以下兩個圖:
2.4 HDFS HA元件介紹
主要就是以下幾個元件:
① Active Namenode
這是主Namenode,處於Active狀態。只有主名稱節點才能對外提供讀寫服務。
② Standby Namenode
這是備Namenode,處於Standby狀態。
③ ZKFailoverController
這是主備切換器,作為獨立的程序執行。對Namenode的主備切換進行整體控制。ZKFC能夠及時監測到節點的健康狀況。在主Namenode故障的時候,藉助Zookeeper這個叢集去實現自動的主備選舉和切換。
④ Zookeeper叢集
⑤ 共享儲存系統
這是實現Namenode高可用性的關鍵。它把一部分元資料儲存在這裡面。主Namenode和備Namenode通過它實現共享元資料的同步。
⑥ Datanode
資料節點功能和之前類似。唯一的區別是之前只需要向一個Namenode彙報資訊,現在需要向主備namenode都彙報資訊。
2.5 Namenode的主備切換
以下是Namenode的主備切換流程圖:
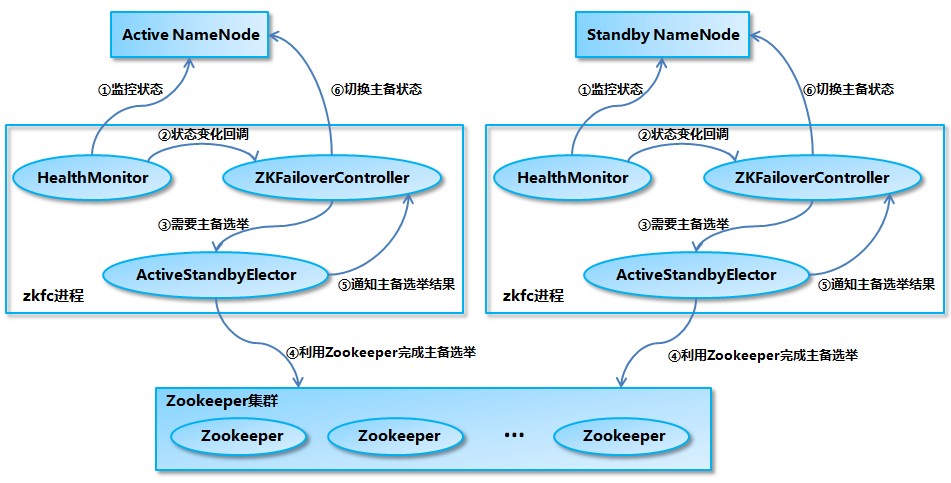
- Namenode主要是由
ZKFailoverControllar、HealthMonitor和ActiveStandByElector這三個元件協同完成的。 - ZKFC這個程序作為Namenode機器上的一個獨立程序啟動,啟動時候會建立HealthMonitor和ActiveStandbyElector這兩個主要的內部元件。ZKFC在建立這兩個元件的同時也會向HealthMonitor和ActiveStandByElector註冊相應的回撥方法。
HealthMonitor主要負責監測namenode健康狀態,可以理解為ZKFC直接去監測namenode的健康狀態。如果namenode狀態發生變化,它會回撥ZKFC的相應方法,進行自動的主備選舉。
ActiveStandbyElector主要負責完成自動的主備選舉,它內部封裝了Zookeeper的處理邏輯,一旦Zookeeper主備選舉完成,就會回撥ZKFC的相應方法來進行namenode的主備切換。
2.6 基於JournalNode的共享儲存系統
作用主要為:
共享儲存把一部分元資料儲存在這裡面,主、備Namenode通過它實現共享元資料的同步。
參看前面介紹的架構圖。
① Namenode執行原理介紹
Namenode在執行HDFS的客戶端提交、建立檔案或者移動檔案這樣操作的時候。會首先把這些操作日誌寫入EditLog,然後在更新記憶體中的檔案系統映象。
檔案系統映象用於namenode向客戶端提供讀服務,而EditLog只是在資料恢復時候起作用。
Namenode也會定期對記憶體中的檔案系統映象進行Checkpoint,在磁碟上生成FsImage檔案。
在namenode啟動的時候,會進行資料恢復,首先把FsImage檔案載入到記憶體中,形成檔案系統映象。
② 共享儲存介紹
基於JournalNode的共享儲存主要用於儲存EditLog,並不儲存Fsimage檔案,FsImage還是在本地磁碟上。
JournalNode叢集共享儲存的基本思想是來自Paxos演算法。採用多個成為JournalNode節點組成,JouranlNode叢集來儲存EditLog,每個JournalNode儲存同樣的EditLog副本,每個JouranlNode寫EditLog的時候除了向本地磁碟寫EditLog之外,也會並行的向JournalNode叢集之中的每一個JournalNode傳送寫請求。只要大多數的節點返回成功,就認為向Journalnode叢集寫入EditLog成功。
一般,Journalnode建立配置奇數個。如果Journal有2n+1臺,那麼根據大多數的原則,最多容忍n臺journalnode節點掛掉。
③ Active和Standby狀態原理
當處於Active狀態的namenode會同時向本地磁碟目錄和journalnode叢集的共享儲存目錄寫入EditLog。寫入JournalNode叢集通過並行呼叫每個Journal的RPC介面和方法去實現的。如果大多數寫成功了,即提交EditLog成功,否則說明提交失敗。
當Namenode進入Standby狀態時候,會定期地呼叫從JournalNode叢集上同步的EditLog,是並行地去呼叫,然後把同步的EditLog放回記憶體中檔案系統映象上,雖然Active nodenode向Journalnode叢集上提交EditLog是同步的,但Standbynamenode採用的是定時的從Journalnode叢集上同步EditLog。
那麼Standbynamenode記憶體中的檔案系統映象就很大可能會落後於Activenamenode,所以當Standbynamenode切換為Activenamenode的時候,就需要把落後的EditLog補上來。同時,由於主備切換,有可能Activenamenode發生異常退出,那麼Journalnode的資料很可能處於不一致狀態,所以首先讓Journalnode上的EditLog恢復成一致,這樣,就需要補齊落後的EditLog。
這兩步完成之後,這樣才能正式成為一個Active,從而對外提供服務。
3. 總結
本節主要介紹了HDFS HA(High Availability)的原理、主備切換過程以及基於JournalNode的共享儲存系統。
概念性的定義較多,需要進一步的熟悉。下一節介紹搭建企業級的Hadoop。
參考資料