
EmotiW2016第一論文Video-based emotion recognition using CNNRNN and C3D hybrid networks
這篇論文主要利用了RNN和C3D解決視訊分類問題,其中RNN將CNN從每個視訊幀中提取出來的特徵進行時序上的編碼,C3D對人臉表徵和運動資訊同時建模,最後再融合音訊特徵,完成視訊分類。本文以59.02%的正確率較EmotiW 2015 53.8%的正確率高出許多。
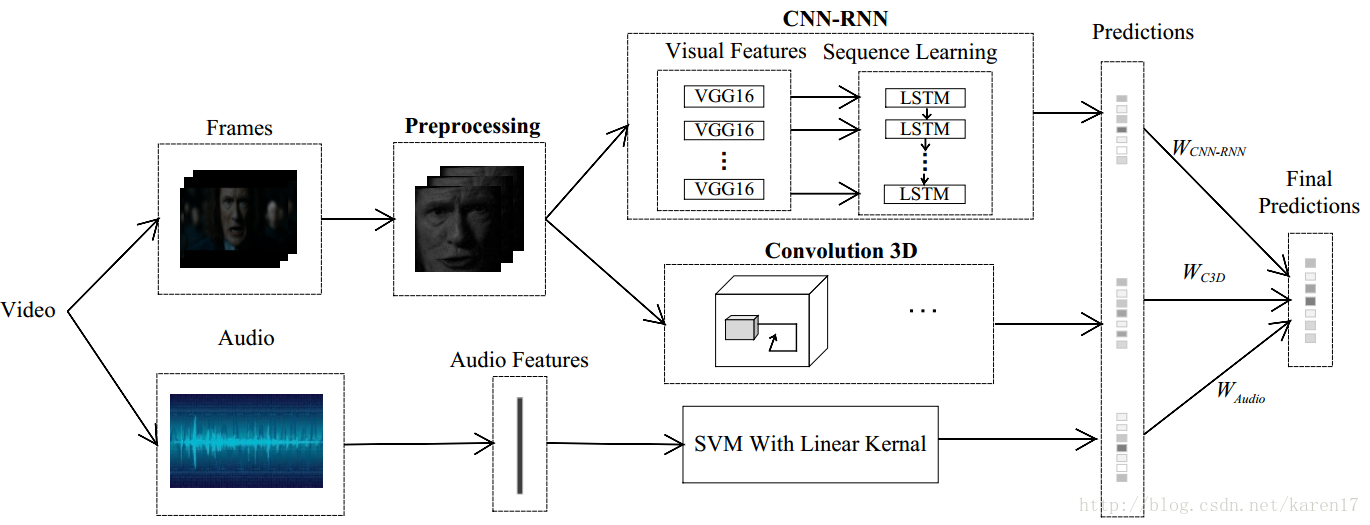
整體模型如圖1,該模型主要由三個子模型組成:CNN-RNN,C3D和音訊模型;CNN-RNN和C3D模型較為核心。本文單獨訓練三個子模型,每個子模型都能得到一個預測結果,最後根據它們在驗證集上的表現,為三個子模型各分配一個權重,最後加權以獲取最終得分。
Experiment
1. 資料集:AFEW6.0
該資料集中每個視訊被標記為一種情緒,一共七種情緒:anger,disgust,fear,happiness,sad,surprise和neural,我們的任務就是為測試集中每個視訊標記一種情緒標籤。該資料集共有1750個短視訊,其中訓練集774個,驗證集383個,測試集593個。
2. 一些實施細節
1)資料預處理部分,要先過濾掉non-faces的圖片幀;
2)CNN-RNN模型中,CNN選用的是用FER2013資料集預訓練過引數的VGG16-Face模型,將fc6層特徵提出來輸入到LSTM中。本文實驗發現用一層LSTM、128個隱藏層單元效果最優。有幾點要注意:如果用VGG16模型的話,迭代多次訓練過程的正確率也就50%左右,模型不能收斂;另外如果不用FER2013資料集對模型引數初始化,預測結果與論文也會差很多。
3)C3D模型:每個視訊選了16個圖片幀,如果該視訊圖片幀數少於16,則不斷複製最後一幀。但在訓練集和驗證集中按一定間隔選取圖片,間隔取決於每個視訊的總體圖片數,step=視訊總幀數/15,也能達到與論文差不多的結果。
本文搭建的C3D網路有8個卷積層、5個下采樣層和2個全連線層,最後一個softmax分類層,如圖所示;模型中很多引數可以參見論文:Learning Spatiotemporal Features with 3D Convolutional Networks 。

C3D結構
Conclusion
本文為競賽論文,比較好懂,作者對為什麼選取一層、128神經元LSTM,為什麼選CNN的fc6層特徵以及最終組合了哪幾個模型,這些細節都有詳細實驗證明,詳見論文。但對如何將三個子模型融合部分一筆帶過,這部分不是本文的重點。關於視訊影象子模型融合問題,後續會寫Recurrent Neural Networksfor Emotion Recognition in Video(EmotiW2015的論文)筆記。