
ARM7、ARM9和ARM11的區別
1. 時鐘頻率的提高
雖然核心架構相同,但ARM7處理器採用3級流水線的馮·諾伊曼結構;而ARM9採用5級流水線的哈佛結構,ARM11為8級流水線哈弗結構(從arm9開始都採用了哈弗結構)。增加的流水線設計提高了時鐘頻率和並行處理能力。5級流水線能夠將每一個指令處理分配到5個時鐘週期內,在每一個時鐘週期內同時有5個指令在執行。在常用的晶片生產工藝 下,ARM7一般執行在100MHz左右,而ARM9則至少在200MHz以上.ARM11首先推出350M~500MHz時鐘頻率的核心,
目前上升到1GHz時鐘頻率。
2 指令週期的改進
指令週期的改進對於處理器效能的提高有很大的幫助。效能提高的幅度依賴於程式碼執行時指令的重疊,這實際上是程式本身的問題。對於採用最高階的語言,一般來說,效能的提高在30%左右。
3.MMU(記憶體管理單元)
ARM7一般沒有MMU(記憶體管理單元),(ARM720T有MMU)。
ARM9一般是有MMU的,ARM9940T只有MPU,不是一個完整的MMU。
ARM11當然也有MMU的。
這一條很重要,MMU單元是大型作業系統必需的硬體支援,如LINUX;WINCE等。這就是說,ARM7一般只能執行小型的實時系統如UCOS-II,eCOS等,而ARM9無此限制,一般的作業系統都可以移植。其實即使ARM720T能支援LINUX;WINCE等系統,也鮮有人用,因為以ARM7的執行速度跑這種大型作業系統,實在有點吃力。再者兩者的應用領域明顯不同,也無此必要。
下面兩個圖:架構一幕瞭然。
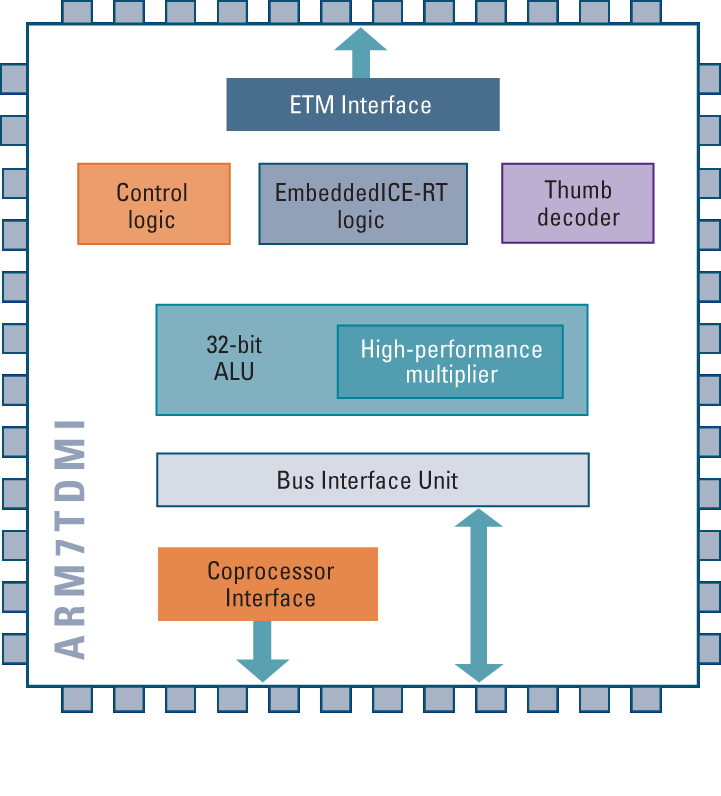
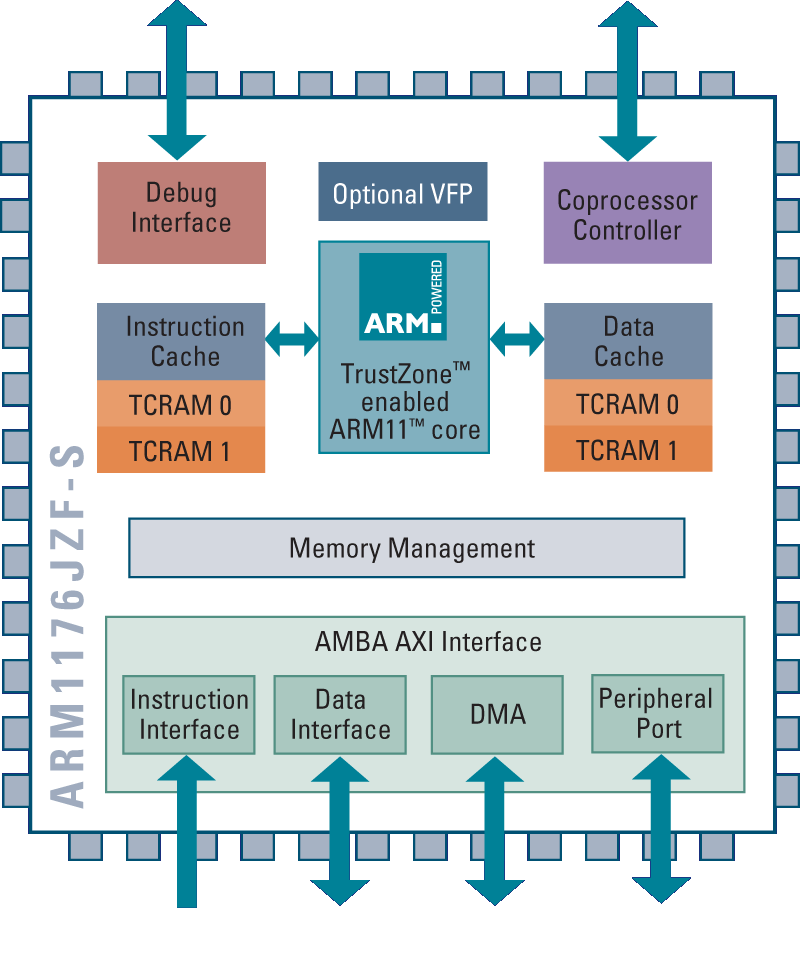
4. 在從ARM7到ARM9,ARM11的平臺轉變過程中,有一件事情是非常值得慶幸的,即ARM9,ARM11能夠地向後相容ARM7上的軟體;並且開發人員面對的程式設計模型和架構基礎也保持一致。
下面圖是一些特徵比較:
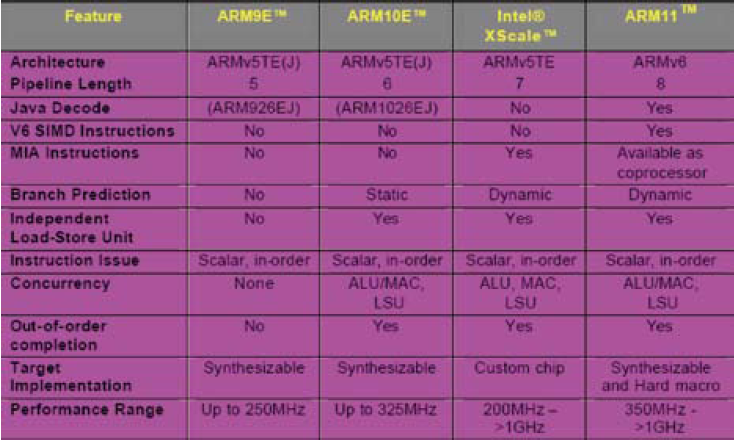
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ARM7是馮諾依慢結構,三級流水線結構
ARM9、
ARM9和ARM11大多帶記憶體管理器,跑作業系統好一點,ARM7適合裸奔。
我們慣稱的 ARM9系列中又存在ARM9與ARM9E兩個系列,其中ARM9 屬於ARM v4T架構,典型處理器如ARM9TDMI和ARM922T;而ARM9E屬於ARM v5TE架構,典型處理器如ARM926EJ和ARM946E。因為後者的晶片數量和應用更為廣泛,所以我們提到ARM9的時候更多地是特指ARM9E系 列處理器(主要就是ARM926EJ和ARM946E這兩款處理器)。下面關於ARM9的介紹也是更多地集中於ARM9E。
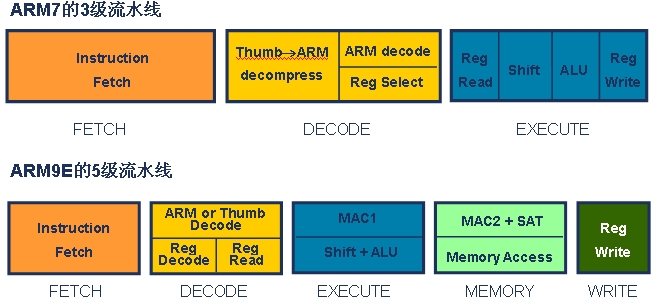
ARM7處理器和ARM9E處理器的流水線差別
對嵌入式系統設計者來說,硬體通常是第一考慮的因素。針對處理器來說,流水線則是硬體差別的最明顯標誌,不同的流水線設計會產生一系列硬體差異。讓我們來比較一下ARM7和ARM9E的流水線,如圖1。
可 以看到ARM9E從ARM7的3級流水線增加到了5級,ARM9E的流水線中容納了更多的邏輯操作,但是每一級的邏輯操作卻變得更為簡單。比如原來 ARM7的第三級流水,需要先內部讀取暫存器、然後進行相關的邏輯和算術運算,接著處理結果回寫,完成的動作非常複雜;而在ARM9E的5級流水中,寄存 器讀取、邏輯運算、結果回寫分散在不同的流水當中,使得每一級流水處理的動作非常簡潔。這就使得處理器的主頻可以大幅度地提高。因為每一級流水都對應 CPU的一個時鐘週期,如果一級流水中的邏輯過於複雜,使得執行時間居高不下,必然導致所需的時鐘週期變長,造成CPU的主頻不能提升。所以流水線的拉長,有利於CPU主頻的提高。在常用的晶片生產工藝下,ARM7一般執行在100MHz左右,而ARM9E則至少在200MHz以上。
ARM9E處理器的儲存器子系統
像ARM926EJ 和ARM946E這兩個最常見的ARM9E處理器中,都帶有一套儲存器子系統,以提高系統性能和支援大型作業系統。如圖2所示,一個儲存器子系統包含一個 MMU(儲存器管理單元)或MPU(儲存器保護單元)、快取記憶體(Cache)和寫緩衝(Write Buffer);CPU通過該子系統與系統儲存器系統相連。
快取記憶體和寫快取 的引入是基於如下事實,即處理器速度遠遠高於儲存器訪問速度;如果儲存器訪問成為系統性能的瓶頸,則處理器再快也是浪費,因為處理器需要耗費大量的時間在 等待儲存器上面。快取記憶體正是用來解決這個問題,它可以儲存最近常用的程式碼和資料,以最快的速度提供給CPU處理(CPU訪問Cache不需要等待)。
圖2:複雜處理器內部的儲存器子系統。

MMU則是用來支援儲存器管理的硬體單元,滿足現代平臺作業系統記憶體管理的需要;它主要包括兩個功能:一是支援虛擬/實體地址對映,二是提供不同儲存器地址空間的保護機制。一個簡單的例子可以幫助我們理解MMU的功能,
如 圖3,在一個作業系統下,程式開發人員都是在作業系統給定的API和程式設計模型下開發程式;作業系統通常只開放一個確定的儲存器地址空間給使用者。這樣就帶來 一個直接的問題,所有的應用程式都使用了相同的儲存器地址空間,如果這些程式同時啟動的話(在現在的多工系統中這是非常常見的),就會產生儲存器訪問衝 突。那作業系統是如何來避免這個問題的呢?
作業系統會利用MMU硬體單元完成 儲存器訪問虛擬地址到實體地址的轉換。所謂虛擬地址就是程式設計師在程式中使用的邏輯地址,而實體地址則是真實儲存器單元的空間地址。MMU通過一定的規則, 可以把相同的虛擬地址對映到不同的實體地址上去。這樣,即使有多個使用相同虛擬地址的程式程序啟動,也可以通過MMU排程把它們對映到不同的實體地址上 去,不會造成系統錯誤。
圖3:MMU的功能和作用。
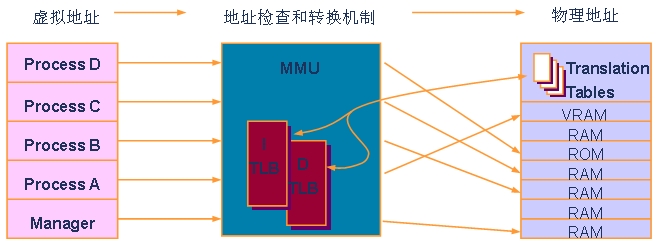
MMU 處理地址對映功能之外,還能給不同的地址空間設定不同的訪問屬性。比如作業系統把自己的核心程式地址空間設定為使用者模式下不可訪問,這樣的話使用者應用程式 就無法訪問到該空間,從而保證作業系統核心的安全性。MPU與MMU的區別在於它只有給地址空間設定訪問屬性的功能而沒有地址對映功能。
Cache以及MMU等硬體單元的引入,給系統程式設計師的程式設計模型帶來了許多全新的變化。除了需要掌握基本的概念和使用方法之外,下面幾個針對系統優化的點既有趣又重要:
1、系統實時性考慮
因 為儲存地址對映規則的頁表(Page Table)非常龐大,通常MMU中只是儲存器了常用的一小段頁表內容,大部分頁表內容都儲存於主儲存器裡面;當呼叫新的地址對映規則時,MMU可能需要 讀取主儲存器來更新頁表。這在某些情況下會造成系統實時性的丟失。比如當需要執行一段關鍵的程式程式碼時,如果不巧這段程式碼使用的地址空間不在當前MMU的 頁表處理範圍裡面,則MMU首先需要更新頁表,然後完成地址對映,接著才能相應儲存器訪問;整個地址譯碼過程非常長,給實時性帶來非常大的不利影響。所以 一般來說帶MMU和Cache的系統在實時性上不如一些簡單的處理器;不過也有一些辦法能夠幫助提高這些系統的實時效率。
一 個簡單的辦法是在需要的時候關閉MMU和Cache,這樣就變成一個簡單處理器了,可以馬上提高系統實時性。當然很多情況下這不可行;在ARM的MMU和 Cache設計中,有一個鎖定的功能,就是說你可以指定某一塊頁表在MMU中不會被更新掉,某一段程式碼或資料可以在Cache中鎖定而不會被重新整理掉;程式 員可以利用這個功能來支援那些實時性要求最高的程式碼,保證這些程式碼始終能夠得到最快的響應和支援。
2、系統軟體優化
在 嵌入式系統開發中,很多系統軟體優化的方法都是相同和通用的,多數情況下這種規則也適用於ARM9E架構上。如果你已經是一個ARM7的程式設計高手,那麼恭 喜你,以前你掌握的優化方法完全可以用在新的ARM9E平臺上,但是會有一些新的特性需要你加倍注意。最重要的便是Cache的作用,Cache本身並不 帶來程式設計模型和介面的變化,但是如果我們考察Cache的行為,就能夠發現對於軟體優化,Cache是有比較大的影響的。
Cache 在物理上就是一塊高速SRAM,ARM9E的Cache組織寬度(cache line)都是4個word(也就是32個位元組);Cache的行為受系統控制器控制而不是程式設計師,系統控制器會把最近訪問儲存器地址附近的內容複製到 Cache中去,這樣,當CPU訪問下一個儲存器單元的時候(這個訪問既可能是取指,也可能是資料),可能這個儲存器單元的內容已經在Cache裡了,所 以CPU不需要真的到主儲存器上去讀取內容,而直接讀取Cache快取記憶體上面的內容就可以了,從而加快了訪問的速度。從Cache的工作原理我們可以看 到,其實Cache的排程是基於概率的,CPU要訪問的資料既可能在Cache中已經存在(Cache hit),也可能沒有存在(Cache miss)。在Cache miss的情況下,CPU訪問儲存器的速度會比沒有Cache的情況更壞,因為CPU除了要從儲存器訪問資料以外,還需要處理Cache hit或miss的判斷,以及Cache內容的重新整理等動作。只有當Cache hit帶來的好處超過Cache miss帶來的犧牲的時候,系統的整體效能才能得到提高,所以Cache的命中率成為一個非常重要的優化指標。
根 據Cache行為的特點,我們可以直觀地得到提高Cache命中率的一些方法,如儘可能把功能相關的程式碼和資料放置在一起,減少跳轉次數;跳轉經常會引起 Cache miss。保持合適的函式大小,不要書寫太多過小的函式體,因為線性的程式執行流程是最為Cache友好的。迴圈體最好放置在4個word對齊的地址,這 樣就能保證迴圈體在Cache中是行對齊的,並且佔用最少的Cache行數,使得被多次呼叫的迴圈體得到更好的執行效率。
效能和效率的提升
前 面介紹了ARM9E相比於ARM7效能上的提高,這不僅表現在ARM9E有更快的主頻、更多的硬體特性上面,還體現在某些指令的執行效率上面。執行效率我 們可以用CPU的時鐘週期數(Cycle)來衡量;運行同一段程式,ARM9E的處理器可以比ARM7節省大約30%左右的時鐘週期。
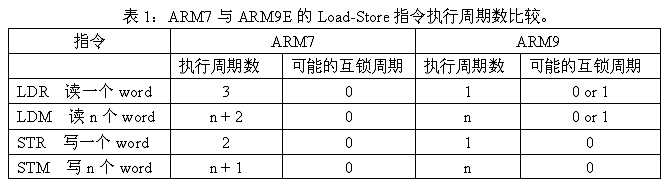
效 率的提高主要來自於ARM9E對於Load-Store指令執行效率的增強。我們知道在RISC架構的處理器中,程式中大約有30%的指令是Load- Store指令,這些指令的效率對系統效率的貢獻是最明顯的。ARM9E中有兩個因素幫助提高Load-Store指令的效率:
1)ARM9核心是哈佛架構,擁有獨立的指令和資料匯流排;相對應,ARM7核心是指令和資料匯流排複用的馮?諾依曼架構。
2)ARM9的5級流水線設計把儲存器訪問和暫存器寫回放在不同的流水上面。
兩 者結合,使得在指令流的執行過程中每個CPU時鐘週期都可以完成一個Load或Store指令。下面的表格比較了ARM7和ARM9處理器之間的Load -Store指令。從中可以看出所有的Store指令ARM9比ARM7省1個週期,Load指令可以省2個週期(在沒有互鎖的情況下,編譯工具能夠通過 編譯優化消除大多數的互鎖可能)。
綜合各種因素,ARM9E處理器擁有非常強大的效能。但是在實際的系統設計中,設計人員並不總是把處理器效能開到最大,理想情況是把處理器和系統執行頻率降 低,使得效能剛好能滿足應用需求;達到節省功耗和成本的目的。在評估系統能夠提供的處理器能力過程中,DMIPS指標被很多人採用;同時它也被廣泛應用於 不同處理器間的效能比較。
但是用DMIPS來衡量處理器效能存在很大的缺陷。 DMIPS並非字面上每秒百萬條指令的意思,它是一個測量 CPU執行一個叫Dhrystone的測試程式時表現出來的相對效能高低的一個單位(很多場合人們也習慣用MIPS作為這個效能指標的單位)。因為基於程 序的測試容易受到惡意優化的干擾,並且DMIPS指標值的釋出不受任何機構的監督,所以使用DMIPS進行評估時要慎重。例如對Dhrystone測試程 序進行不同的編譯處理,在同一個處理器上執行也可以得出差別很大的結果,如圖4中是ARM926EJ在32位0等待儲存器上執行測試程式的結果。ARM一
直採用比較保守的值作為CPU的DMIPS標稱值,如ARM926EJ是1.1DMPS/MHz。
圖4:不同測試條件下ARM926EJ處理器的DMIPS值。

DMIPS 另外一個缺點是不能測量處理器的數字訊號處理能力和Cache/MMU子系統的效能。因為Dhrystone測試程式不包含DSP表示式,只包含一些整型 運算和字串處理,並且測試程式偏小,幾乎可以完整地放在Cache裡面執行而無需與外部儲存器進行互動。這樣就難以反映處理器在一個真實系統中的真正性 能。
一種值得鼓勵的評估方法是站在系統的角度看問題,而不僅僅拘泥於CPU本身;而系統性能評估最好的測試向量就是使用者應用程式或相近的測試程式,這是使用者所需的最真實的結果。
ARM9E處理器的DSP運算能力
伴 隨應用程式的多樣化和複雜化,諸如多媒體、音視訊功能在嵌入式系統裡面也是全面開花。這些應用需要相當的DSP處理能力;如果是在傳統的RISC架構上實 現這些演算法,所需的資源(頻率和儲存器等)會非常不經濟。ARM9E處理器一個非常重要的優勢就是擁有輕量級的DSP處理能力,以非常小的成本(CPU增 加功能需要增加硬體)換來了非常實用的DSP效能。
因為CPU的DSP能力並不直接反映在像DMIPS這樣的評測指標中,同時像以前的ARM7處理器中也沒有類似的概念;所以這一點對所有使用ARM9E處理器進行開發的人來說,都是需要注意的一個要點。
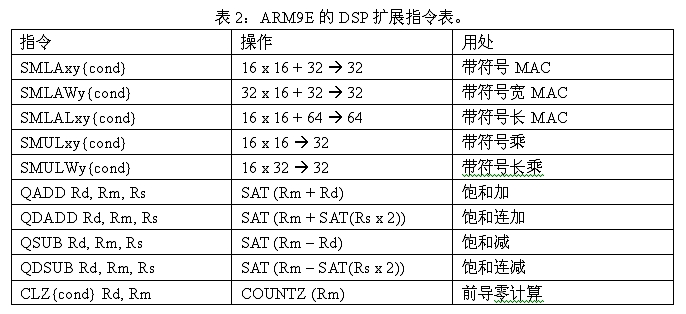
ARM9E的DSP擴充套件指令如表2所示,主要包括三個型別。
1)單週期的16x16和32x16 MAC操作,因為數字訊號處理中甚少32位寬的運算元,在32位暫存器中可以對運算元分段運算顯得非常有用。
2)對原有的算術運算指令增加了飽和處理擴充套件,所謂飽和運算,就是當運算結果大於一個上限或小於一個下限時,結果就等於上限或是下限;飽和處理在音訊資料和視訊畫素處理中普遍使用,現在一條單週期飽和運算指令就能夠完成普通RISC指令“運算-判斷-取值”這一系列操作。
3)前導零(CLZ)運算指令,提高了歸一化和浮點運算以及除法操作的效能。
以 流行的MP3解碼程式為例。整個解碼過程中前端的三個步驟是運算量最大的,包括位元流的讀入(解包)、霍夫曼譯碼還有反量化取樣(逆變換)。ARM9E的 DSP指令正好可以高效地完成這些運算。以44.1 KHz@128 kbps位元速率的MP3音樂檔案為例,ARM7TDMI需要佔用20MHz以上的資源,而ARM926EJ則只要小於10MHz的資源
在 從ARM7到ARM9的平臺轉變過程中,有一件事情是非常值得慶幸的,即ARM9E能夠完全地向後相容ARM7上的軟體;並且開發人員面對的程式設計模型和架 構基礎也保持一致。但是畢竟ARM9E中增加了很多新的特性,為了充分利用這些新的資源,把系統性能優化好,需要我們對ARM9E做更多深入地瞭解。
------------------------------------------------------------------------------------------------------------------------------------------------------------
"目前市場上出現很多ARM11的6410開發板,而且賣的很熱門。針對很多人不知道6410開發板跟ARM9的具體區別的問題,我把自己的看法給大家講一下:
我之前有用過ARM9開發板S3C2440的,最近公司買了塊S3C6410的開發板,感覺上來講真的很不一樣。它們的區別總體來說有這麼幾點:
1. 首先是主頻,2440開發板是400M的,而6410開發板是667M的,據說還有高達800M的呢;
2. 作業系統上最大區別是2440開發板支援WINCE5.0的作業系統"~而6410開發板支援WINCE6.0的系統,另外6410還支援Linux2.6,Android,Ubuntu三個系統;
3.ARM11的6410開發板有MPEG-4/H.264/VC-1的視訊編解碼; 2D/3D圖形加速,TV輸出等 ,而ARM9的2440不支援;
4.ARM11的6410開發板支援2路SD/MMC4.0卡和符合CF3.0規範高速CF卡,而ARM9的2440不能同時支援這麼多,一般就支援一個SD卡;
5.帶有IDE介面,支援WINCE6.0系統下掛載PATA硬碟;
6.可以擴充套件更大的容量,增加更多的介面,串列埠上面就是比ARM9多1-2個,還有多了紅外介面,高速USB介面,S-VIDEO介面等等。
以上的不同我僅僅是研究了立宇泰電子公司的開發板而得出的,我們公司從44B0開始就用他們家產品,資料上面很齊全,服務也一直很到位。大家可以參考下
http://blog.csdn.net/muge0913/article/details/6144709