
Linux schedule 2、排程演算法
2、排程演算法
linux程序一般分成了實時程序(RT)和普通程序,linux使用sched_class結構來管理不同型別程序的排程演算法:rt_sched_class負責實時類程序(SCHED_FIFO/SCHED_RR)的排程,fair_sched_class負責普通程序(SCHED_NORMAL)的排程,還有idle_sched_class(SCHED_IDLE)、dl_sched_class(SCHED_DEADLINE)都比較簡單和少見;
實時程序的排程演算法移植都沒什麼變化,SCHED_FIFO型別的誰優先順序高就一直搶佔/SCHED_RR相同優先順序的進行時間片輪轉。
所以我們常說的排程演算法一般指普通程序(SCHED_NORMAL)的排程演算法,這類程序也在系統中佔大多數。在2.6.24以後核心引入的是CFS演算法,這個也是現在的主流;在這之前2.6核心使用的是一種O(1)演算法;
2.1、linux2.6的O(1)排程演算法
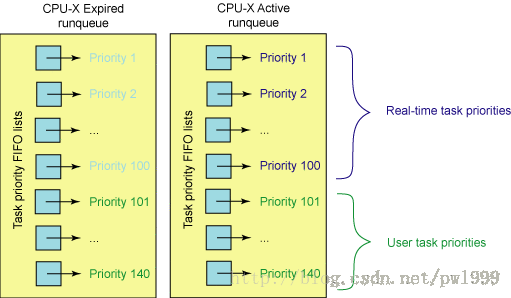
linux程序的優先順序有140種,其中優先順序(0-99)對應實時程序,優先順序(100-139)對應普通程序,nice(0)對應優先順序120,nice(-10)對應優先順序100,nice(19)對應優先順序139。
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO // 優先順序(1-99)對應實時程序
#define MAX_PRIO (MAX_RT_PRIO + 40) // 優先順序(100-139)對應普通程序
/*
* Convert user-nice values [ -20 O(1)排程演算法主要包含以下內容:
- (1)、每個cpu的rq包含兩個140個成員的連結串列陣列rq->active、rq->expired;
任務根據優先順序掛載到不同的陣列當中,時間片沒有用完放在rq->active,時間片用完後放到rq->expired,在rq->active所有任務時間片用完為空後rq->active和rq->expired相互反轉。
在schedule()中pcik next task時,首先會根據array->bitmap找出哪個最先優先順序還有任務需要排程,然後根據index找到 對應的優先順序任務連結串列。因為查詢bitmap的在IA處理器上可以通過bsfl等一條指令來實現,所以他的複雜度為O(1)。
asmlinkage void __sched schedule(void)
{
idx = sched_find_first_bit(array->bitmap);
queue = array->queue + idx;
next = list_entry(queue->next, task_t, run_list);
}- (2)、程序優先順序分為靜態優先順序(p->static_prio)、動態優先順序(p->prio);
靜態優先順序(p->static_prio)決定程序時間片的大小:
/*
* task_timeslice() scales user-nice values [ -20 ... 0 ... 19 ]
* to time slice values: [800ms ... 100ms ... 5ms]
*
* The higher a thread's priority, the bigger timeslices
* it gets during one round of execution. But even the lowest
* priority thread gets MIN_TIMESLICE worth of execution time.
*/
/* 根據演算法如果nice(0)的時間片為100mS,那麼nice(-20)時間片為800ms、nice(19)時間片為5ms */
#define SCALE_PRIO(x, prio) \
max(x * (MAX_PRIO - prio) / (MAX_USER_PRIO/2), MIN_TIMESLICE)
static unsigned int task_timeslice(task_t *p)
{
if (p->static_prio < NICE_TO_PRIO(0))
return SCALE_PRIO(DEF_TIMESLICE*4, p->static_prio);
else
return SCALE_PRIO(DEF_TIMESLICE, p->static_prio);
}
#define MIN_TIMESLICE max(5 * HZ / 1000, 1)
#define DEF_TIMESLICE (100 * HZ / 1000)動態優先順序決定程序在rq->active、rq->expired程序連結串列中的index:
static void enqueue_task(struct task_struct *p, prio_array_t *array)
{
sched_info_queued(p);
list_add_tail(&p->run_list, array->queue + p->prio); // 根據動態優先順序p->prio作為index,找到對應連結串列
__set_bit(p->prio, array->bitmap);
array->nr_active++;
p->array = array;
}動態優先順序和靜態優先順序之間的轉換函式:動態優先順序=max(100 , min(靜態優先順序 – bonus + 5) , 139)
/*
* effective_prio - return the priority that is based on the static
* priority but is modified by bonuses/penalties.
*
* We scale the actual sleep average [0 .... MAX_SLEEP_AVG]
* into the -5 ... 0 ... +5 bonus/penalty range.
*
* We use 25% of the full 0...39 priority range so that:
*
* 1) nice +19 interactive tasks do not preempt nice 0 CPU hogs.
* 2) nice -20 CPU hogs do not get preempted by nice 0 tasks.
*
* Both properties are important to certain workloads.
*/
static int effective_prio(task_t *p)
{
int bonus, prio;
if (rt_task(p))
return p->prio;
bonus = CURRENT_BONUS(p) - MAX_BONUS / 2; // MAX_BONUS = 10
prio = p->static_prio - bonus;
if (prio < MAX_RT_PRIO)
prio = MAX_RT_PRIO;
if (prio > MAX_PRIO-1)
prio = MAX_PRIO-1;
return prio;
}從上面看出動態優先順序是以靜態優先順序為基礎,再加上相應的懲罰或獎勵(bonus)。這個bonus並不是隨機的產生,而是根據程序過去的平均睡眠時間做相應的懲罰或獎勵。所謂平均睡眠時間(sleep_avg,位於task_struct結構中)就是程序在睡眠狀態所消耗的總時間數,這裡的平均並不是直接對時間求平均數。
- (3)、根據平均睡眠時間判斷程序是否是互動式程序(INTERACTIVE);
互動式程序的好處?互動式程序時間片用完會重新進入active佇列;
void scheduler_tick(void)
{
if (!--p->time_slice) { // (1) 時間片用完
dequeue_task(p, rq->active); // (2) 退出actice佇列
set_tsk_need_resched(p);
p->prio = effective_prio(p);
p->time_slice = task_timeslice(p);
p->first_time_slice = 0;
if (!rq->expired_timestamp)
rq->expired_timestamp = jiffies;
if (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) {
enqueue_task(p, rq->expired); // (3) 普通程序進入expired佇列
if (p->static_prio < rq->best_expired_prio)
rq->best_expired_prio = p->static_prio;
} else
enqueue_task(p, rq->active); // (4) 如果是互動式程序,重新進入active佇列
}
}判斷程序是否是互動式程序(INTERACTIVE)的公式:動態優先順序≤3*靜態優先順序/4 + 28
#define TASK_INTERACTIVE(p) \
((p)->prio <= (p)->static_prio - DELTA(p))
平均睡眠時間的演算法和互動程序的思想,我沒有詳細去看大家可以參考一下的一些描述:
所謂平均睡眠時間(sleep_avg,位於task_struct結構中)就是程序在睡眠狀態所消耗的總時間數,這裡的平均並不是直接對時間求平均數。平均睡眠時間隨著程序的睡眠而增長,隨著程序的執行而減少。因此,平均睡眠時間記錄了程序睡眠和執行的時間,它是用來判斷程序互動性強弱的關鍵資料。如果一個程序的平均睡眠時間很大,那麼它很可能是一個互動性很強的程序。反之,如果一個程序的平均睡眠時間很小,那麼它很可能一直在執行。另外,平均睡眠時間也記錄著程序當前的互動狀態,有很快的反應速度。比如一個程序在某一小段時間互動性很強,那麼sleep_avg就有可能暴漲(當然它不能超過 MAX_SLEEP_AVG),但如果之後都一直處於執行狀態,那麼sleep_avg就又可能一直遞減。理解了平均睡眠時間,那麼bonus的含義也就顯而易見了。互動性強的程序會得到排程程式的獎勵(bonus為正),而那些一直霸佔CPU的程序會得到相應的懲罰(bonus為負)。其實bonus相當於平均睡眠時間的縮影,此時只是將sleep_avg調整成bonus數值範圍內的大小。
O(1)排程器區分互動式程序和批處理程序的演算法與以前雖大有改進,但仍然在很多情況下會失效。有一些著名的程式總能讓該排程器效能下降,導致互動式程序反應緩慢。例如fiftyp.c, thud.c, chew.c, ring-test.c, massive_intr.c等。而且O(1)排程器對NUMA支援也不完善。
2.2、CFS排程演算法
針對O(1)演算法出現的問題(具體是哪些問題我也理解不深說不上來),linux推出了CFS(Completely Fair Scheduler)完全公平排程演算法。該演算法從樓梯排程演算法(staircase scheduler)和RSDL(Rotating Staircase Deadline Scheduler)發展而來,拋棄了複雜的active/expire陣列和互動程序計算,把所有程序一視同仁都放到一個執行時間的紅黑樹中,實現了完全公平的思想。
CFS的主要思想如下:
- 根據普通程序的優先順序nice值來定一個比重(weight),該比重用來計算程序的實際執行時間到虛擬執行時間(vruntime)的換算;不言而喻優先順序高的程序執行更多的時間和優先順序低的程序執行更少的時間在vruntime上市等價的;
- 根據rq->cfs_rq中程序的數量計算一個總的period週期,每個程序再根據自己的weight佔整個的比重來計算自己的理想執行時間(ideal_runtime),在scheduler_tick()中判斷如果程序的實際執行時間(exec_runtime)已經達到理想執行時間(ideal_runtime),則程序需要被排程test_tsk_need_resched(curr)。有了period,那麼cfs_rq中所有程序在period以內必會得到排程;
- 根據程序的虛擬執行時間(vruntime),把rq->cfs_rq中的程序組織成一個紅黑樹(平衡二叉樹),那麼在pick_next_entity時樹的最左節點就是執行時間最少的程序,是最好的需要排程的候選人;
2.2.1、vruntime
每個程序的vruntime = runtime * (NICE_0_LOAD/nice_n_weight)
/* 該表的主要思想是,高一個等級的weight是低一個等級的 1.25 倍 */
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};nice(0)對應的weight是NICE_0_LOAD(1024),nice(-1)對應的weight是NICE_0_LOAD*1.25,nice(1)對應的weight是NICE_0_LOAD/1.25。
NICE_0_LOAD(1024)在schedule計算中是一個非常神奇的數字,他的含義就是基準”1”。因為kernel不能表示小數,所以把1放大稱為1024。
scheduler_tick() -> task_tick_fair() -> update_curr():
↓
static void update_curr(struct cfs_rq *cfs_rq)
{
curr->sum_exec_runtime += delta_exec; // (1) 累計當前程序的實際執行時間
schedstat_add(cfs_rq, exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr); // (2) 累計當前程序的vruntime
update_min_vruntime(cfs_rq);
}
↓
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
// (2.1) 根據程序的weight折算vruntime
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
2.2.2、period和ideal_runtime
scheduler_tick()中根據cfs_rq中的se數量計算period和ideal_time,判斷當前程序時間是否用完需要排程:
scheduler_tick() -> task_tick_fair() -> entity_tick() -> check_preempt_tick():
↓
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
/* (1) 計算period和ideal_time */
ideal_runtime = sched_slice(cfs_rq, curr);
/* (2) 計算實際執行時間 */
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
/* (3) 如果實際執行時間已經超過ideal_time,
當前程序需要被排程,設定TIF_NEED_RESCHED標誌
*/
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
↓
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/* (1.1) 計算period值 */
u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq);
/* 疑問:這裡是根據最底層se和cfq_rq來計算ideal_runtime,然後逐層按比重摺算到上層時間
這種方法是不對的,應該是從頂層到底層分配時間下來才比較合理。
慶幸的是,在task_tick_fair()中會呼叫task_tick_fair遞迴的每層遞迴的計算時間,
所以最上面的一層也是判斷的
*/
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
/* (1.2) 根據period值和程序weight在cfs_rq weight中的比重計算ideal_runtime
*/
slice = __calc_delta(slice, se->load.weight, load);
}
return slice;
}
↓
/* (1.1.1) period的計算方法,從預設值看:
如果cfs_rq中的程序大於8(sched_nr_latency)個,則period=n*0.75ms(sysctl_sched_min_granularity)
如果小於等於8(sched_nr_latency)個,則period=6ms(sysctl_sched_latency)
*/
/*
* The idea is to set a period in which each task runs once.
*
* When there are too many tasks (sched_nr_latency) we have to stretch
* this period because otherwise the slices get too small.
*
* p = (nr <= nl) ? l : l*nr/nl
*/
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}
/*
* Minimal preemption granularity for CPU-bound tasks:
* (default: 0.75 msec * (1 + ilog(ncpus)), units: nanoseconds)
*/
unsigned int sysctl_sched_min_granularity = 750000ULL;
unsigned int normalized_sysctl_sched_min_granularity = 750000ULL;
/*
* is kept at sysctl_sched_latency / sysctl_sched_min_granularity
*/
static unsigned int sched_nr_latency = 8;
/*
* Targeted preemption latency for CPU-bound tasks:
* (default: 6ms * (1 + ilog(ncpus)), units: nanoseconds)
*
* NOTE: this latency value is not the same as the concept of
* 'timeslice length' - timeslices in CFS are of variable length
* and have no persistent notion like in traditional, time-slice
* based scheduling concepts.
*
* (to see the precise effective timeslice length of your workload,
* run vmstat and monitor the context-switches (cs) field)
*/
unsigned int sysctl_sched_latency = 6000000ULL;
unsigned int normalized_sysctl_sched_latency = 6000000ULL;
2.2.3、紅黑樹(Red Black Tree)

紅黑樹又稱為平衡二叉樹,它的特點:
- 1、平衡。從根節點到葉子節點之間的任何路徑,差值不會超過1。所以pick_next_task()複雜度為O(log n)。可以看到pick_next_task()複雜度是大於o(1)演算法的,但是最大路徑不會超過log2(n) - 1,複雜度是可控的。
- 2、排序。左邊的節點一定小於右邊的節點,所以最左邊節點是最小值。
按照程序的vruntime組成了紅黑樹:
enqueue_task_fair() -> enqueue_entity() -> __enqueue_entity():
↓
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
int leftmost = 1;
/*
* Find the right place in the rbtree:
*/
/* (1) 根據vruntime的值在rbtree中找到合適的插入點 */
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
if (entity_before(se, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = 0;
}
}
/*
* Maintain a cache of leftmost tree entries (it is frequently
* used):
*/
/* (2) 更新最左值最小值cache */
if (leftmost)
cfs_rq->rb_leftmost = &se->run_node;
/* (3) 將節點插入rbtree */
rb_link_node(&se->run_node, parent, link);
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}
2.2.4、sched_entity和task_group
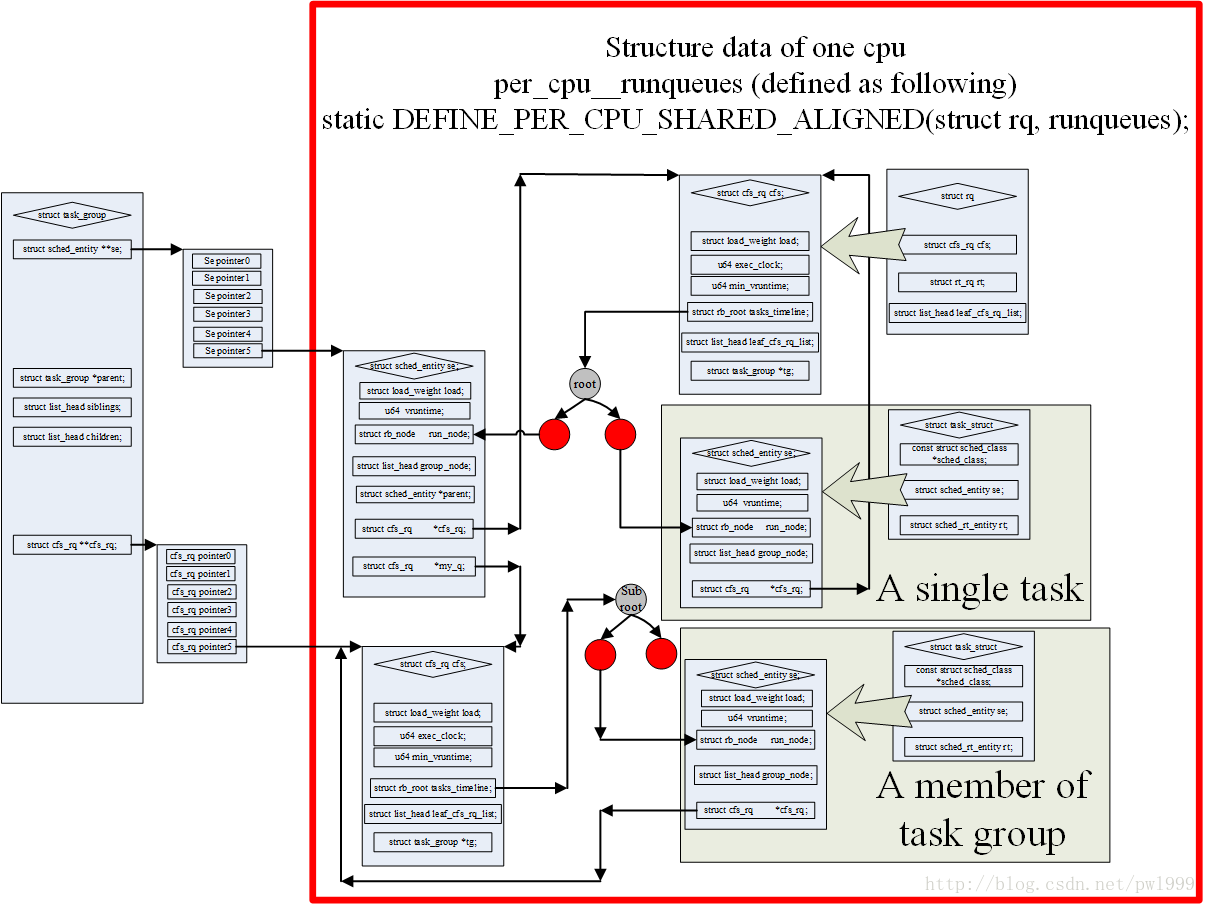
因為新的核心加入了task_group的概念,所以現在不是使用task_struct結構直接參與到schedule計算當中,而是使用sched_entity結構。一個sched_entity結構可能是一個task也可能是一個task_group->se[cpu]。上圖非常好的描述了這些結構之間的關係。
其中主要的層次關係如下:
- 1、一個cpu只對應一個rq;
- 2、一個rq有一個cfs_rq;
- 3、cfs_rq使用紅黑樹組織多個同一層級的sched_entity;
- 4、如果sched_entity對應的是一個task_struct,那sched_entity和task是一對一的關係;
- 5、如果sched_entity對應的是task_group,那麼他是一個task_group多個sched_entity中的一個。task_group有一個數組se[cpu],在每個cpu上都有一個sched_entity。這種型別的sched_entity有自己的cfs_rq,一個sched_entity對應一個cfs_rq(se->my_q),cfs_rq再繼續使用紅黑樹組織多個同一層級的sched_entity;3-5的層次關係可以繼續遞迴下去。
2.2.5、scheduler_tick()
關於演算法,最核心的部分都在scheduler_tick()函式當中,所以我們來詳細的解析這部分程式碼。
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
/* (1) sched_tick()的校準,x86 bug的修復 */
sched_clock_tick();
#ifdef CONFIG_MTK_SCHED_MONITOR
mt_trace_rqlock_start(&rq->lock);
#endif
raw_spin_lock(&rq->lock);
#ifdef CONFIG_MTK_SCHED_MONITOR
mt_trace_rqlock_end(&rq->lock);
#endif
/* (2) 計算cpu級別(rq)的執行時間 :
rq->clock是cpu總的執行時間 (疑問:這裡沒有考慮cpu hotplug??)
rq->clock_task是程序的實際執行時間,= rq->clock總時間 - rq->prev_irq_time中斷消耗的時間
*/
update_rq_clock(rq);
/* (3) 呼叫程序所屬sched_class的tick函式
cfs對應的是task_tick_fair()
rt對應的是task_tick_rt()
*/
curr->sched_class->task_tick(rq, curr, 0);
/* (4) 更新cpu級別的負載 */
update_cpu_load_active(rq);
/* (5) 更新系統級別的負載 */
calc_global_load_tick(rq);
/* (6) cpufreq_sched governor,計算負載來進行cpu調頻 */
sched_freq_tick(cpu);
raw_spin_unlock(&rq->lock);
perf_event_task_tick();
#ifdef CONFIG_MTK_SCHED_MONITOR
mt_save_irq_counts(SCHED_TICK);
#endif
#ifdef CONFIG_SMP
/* (7) 負載均衡 */
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}
|→
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
/* (3.1) 按照task_group組織的se父子關係,
逐級對se 和 se->parent 進行遞迴計算
*/
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
/* (3.2) se對應的tick操作 */
entity_tick(cfs_rq, se, queued);
}
/* (3.3) NUMA負載均衡 */
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
if (!rq->rd->overutilized && cpu_overutilized(task_cpu(curr)))
rq->rd->overutilized = true;
}
||→
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
/* (3.2.1) 更新cfs_rq->curr的se的實際執行時間curr->sum_exec_runtime和虛擬執行時間curr->vruntime
更新cfs_rq的執行時間
*/
update_curr(cfs_rq);
/*
* Ensure that runnable average is periodically updated.
*/
/* (3.2.2) 更新entity級別的負載,PELT計算 */
update_load_avg(curr, 1);
/* (3.2.3) 更新task_group的shares */
update_cfs_shares(cfs_rq);
#ifdef CONFIG_SCHED_HRTICK
/*
* queued ticks are scheduled to match the slice, so don't bother
* validating it and just reschedule.
*/
if (queued) {
resched_curr(rq_of(cfs_rq));
return;
}
/*
* don't let the period tick interfere with the hrtick preemption
*/
if (!sched_feat(DOUBLE_TICK) &&
hrtimer_active(&rq_of(cfs_rq)->hrtick_timer))
return;
#endif
/* (3.2.4) check當前任務的理想執行時間ideal_runtime是否已經用完,
是否需要重新排程
*/
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
|||→
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
/* (3.2.1.1) 計算cfs_rq->curr se的實際執行時間 */
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
// 更新cfs_rq的實際執行時間cfs_rq->exec_clock
schedstat_add(cfs_rq, exec_clock, delta_exec);
/* (3.2.1.2) 計算cfs_rq->curr se的虛擬執行時間vruntime */
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
/* (3.2.1.3) 如果se對應的是task,而不是task_group,
更新task對應的時間統計
*/
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
// 更新task所在cgroup之cpuacct的某個cpu執行時間ca->cpuusage[cpu]->cpuusage
cpuacct_charge(curtask, delta_exec);
// 統計task所線上程組(thread group)的執行時間:
// tsk->signal->cputimer.cputime_atomic.sum_exec_runtime
account_group_exec_runtime(curtask, delta_exec);
}
/* (3.2.1.4) 計算cfs_rq的執行時間,是否超過cfs_bandwidth的限制:
cfs_rq->runtime_remaining
*/
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
2.2.6、幾個特殊時刻vruntime的變化
關於cfs排程和vruntime,除了正常的scheduler_tick()的計算,還有些特殊時刻需要特殊處理。這些細節用一些疑問來牽引出來:
- 1、新程序的vruntime是多少?
假如新程序的vruntime初值為0的話,比老程序的值小很多,那麼它在相當長的時間內都會保持搶佔CPU的優勢,老程序就要餓死了,這顯然是不公平的。
CFS的做法是:取父程序vruntime(curr->vruntime) 和 (cfs_rq->min_vruntime + 假設se執行過一輪的值)之間的最大值,賦給新建立程序。把新程序對現有程序的排程影響降到最小。
_do_fork() -> copy_process() -> sched_fork() -> task_fork_fair():
↓
static void task_fork_fair(struct task_struct *p)
{
/* (1) 如果cfs_rq->current程序存在,
se->vruntime的值暫時等於curr->vruntime
*/
if (curr)
se->vruntime = curr->vruntime;
/* (2) 設定新的se->vruntime */
place_entity(cfs_rq, se, 1);
/* (3) 如果sysctl_sched_child_runs_first標誌被設定,
確保fork子程序比父程序先執行*/
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
/* (4) 防止新程序執行時是在其他cpu上執行的,
這樣在加入另一個cfs_rq時再加上另一個cfs_rq佇列的min_vruntime值即可
(具體可以看enqueue_entity函式)
*/
se->vruntime -= cfs_rq->min_vruntime;
raw_spin_unlock_irqrestore(&rq->lock, flags);
}
|→
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
/* (2.1) 計算cfs_rq->min_vruntime + 假設se執行過一輪的值,
這樣的做法是把新程序se放到紅黑樹的最後 */
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
/* sleeps up to a single latency don't count. */
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/* (2.2) 在 (curr->vruntime) 和 (cfs_rq->min_vruntime + 假設se執行過一輪的值),
之間取最大值
*/
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update the normalized vruntime before updating min_vruntime
* through calling update_curr().
*/
/* (4.1) 在enqueue時給se->vruntime重新加上cfs_rq->min_vruntime */
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
se->vruntime += cfs_rq->min_vruntime;
}
- 2、休眠程序的vruntime一直保持不變嗎、
如果休眠程序的 vruntime 保持不變,而其他執行程序的 vruntime 一直在推進,那麼等到休眠程序終於喚醒的時候,它的vruntime比別人小很多,會使它獲得長時間搶佔CPU的優勢,其他程序就要餓死了。這顯然是另一種形式的不公平。
CFS是這樣做的:在休眠程序被喚醒時重新設定vruntime值,以min_vruntime值為基礎,給予一定的補償,但不能補償太多。
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
if (flags & ENQUEUE_WAKEUP) {
/* (1) 計算程序喚醒後的vruntime */
place_entity(cfs_rq, se, 0);
enqueue_sleeper(cfs_rq, se);
}
}
|→
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
/* (1.1) 初始值是cfs_rq的當前最小值min_vruntime */
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
/* sleeps up to a single latency don't count. */
/* (1.2) 在最小值min_vruntime的基礎上給予補償,
預設補償值是6ms(sysctl_sched_latency)
*/
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
- 3、休眠程序在喚醒時會立刻搶佔CPU嗎?
程序被喚醒預設是會馬上檢查是否庫搶佔,因為喚醒的vruntime在cfs_rq的最小值min_vruntime基礎上進行了補償,所以他肯定會搶佔當前的程序。
CFS可以通過禁止WAKEUP_PREEMPTION來禁止喚醒搶佔,不過這也就失去了搶佔特性。
try_to_wake_up() -> ttwu_queue() -> ttwu_do_activate() -> ttwu_do_wakeup() -> check_preempt_curr() -> check_preempt_wakeup()
↓
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
/*
* Batch and idle tasks do not preempt non-idle tasks (their preemption
* is driven by the tick):
*/
/* (1) 如果WAKEUP_PREEMPTION沒有被設定,不進行喚醒時的搶佔 */
if (unlikely(p->policy != SCHED_NORMAL) || !sched_feat(WAKEUP_PREEMPTION))
return;
preempt:
resched_curr(rq);
}
- 4、程序從一個CPU遷移到另一個CPU上的時候vruntime會不會變?
不同cpu的負載時不一樣的,所以不同cfs_rq裡se的vruntime水平是不一樣的。如果程序遷移vruntime不變也是非常不公平的。
CFS使用了一個很聰明的做法:在退出舊的cfs_rq時減去舊cfs_rq的min_vruntime,在加入新的cfq_rq時重新加上新cfs_rq的min_vruntime。
static void
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Normalize the entity after updating the min_vruntime because the
* update can refer to the ->curr item and we need to reflect this
* movement in our normalized position.
*/
/* (1) 退出舊的cfs_rq時減去舊cfs_rq的min_vruntime */
if (!(flags & DEQUEUE_SLEEP))
se->vruntime -= cfs_rq->min_vruntime;
}
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update the normalized vruntime before updating min_vruntime
* through calling update_curr().
*/
/* (2) 加入新的cfq_rq時重新加上新cfs_rq的min_vruntime */
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
se->vruntime += cfs_rq->min_vruntime;
}
2.2.7、cfs bandwidth
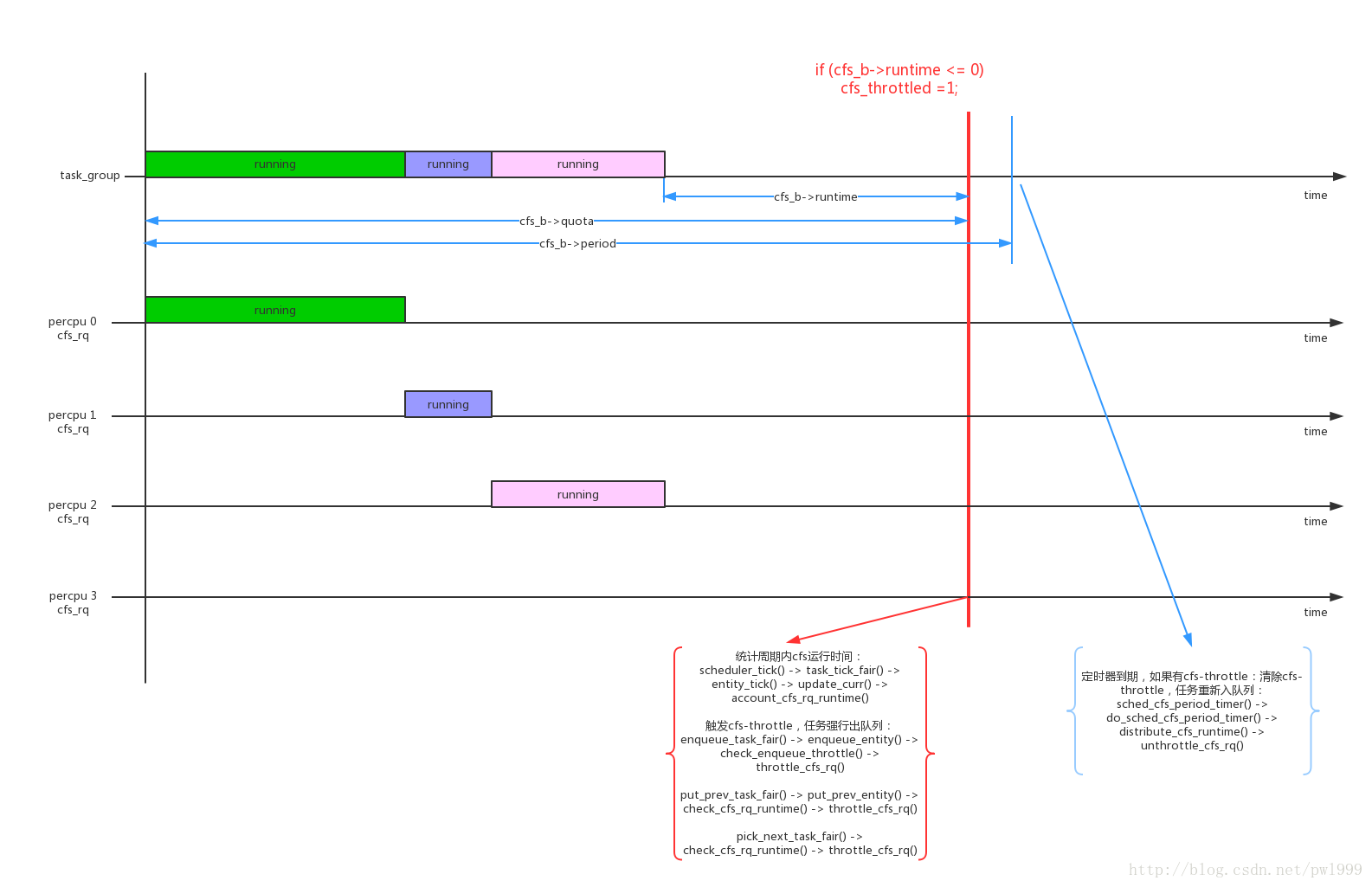
- 1、cfs bandwidth是針對task_group的配置,一個task_group的bandwidth使用一個struct cfs_bandwidth *cfs_b資料結構來控制。
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
ktime_t period; // cfs bandwidth的監控週期,預設值是default_cfs_period() 0.1s
u64 quota; // cfs task_group 在一個監控週期內的執行時間配額,預設值是RUNTIME_INF,無限大
u64 runtime; // cfs task_group 在一個監控週期內剩餘可執行的時間
s64 hierarchical_quota;
u64 runtime_expires;
int idle, period_active;
struct hrtimer period_timer;
struct hrtimer slack_timer;
struct list_head throttled_cfs_rq;
/* statistics */
int nr_periods, nr_throttled;
u64 throttled_time;
#endif
};其中幾個關鍵的資料結構:cfs_b->period是監控週期,cfs_b->quota是tg的執行配額,cfs_b->runtime是tg剩餘可執行的時間。cfs_b->runtime在監控週期開始的時候等於cfs_b->quota,隨著tg不斷執行不斷減少,如果cfs_b->runtime < 0說明tg已經超過bandwidth,觸發流量控制;
cfs bandwidth是提供給CGROUP_SCHED使用的,所以cfs_b->quota的初始值都是RUNTIME_INF無限大,所以在使能CGROUP_SCHED以後需要自己配置這些引數。
- 2、因為一個task_group是在percpu上都建立了一個cfs_rq,所以cfs_b->quota的值是這些percpu cfs_rq中的程序共享的,每個percpu cfs_rq在執行時需要向tg->cfs_bandwidth->runtime來申請;
scheduler_tick() -> task_tick_fair() -> entity_tick() -> update_curr() -> account_cfs_rq_runtime()
↓
static __always_inline
void account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled)
return;
__account_cfs_rq_runtime(cfs_rq, delta_exec);
}
|→
static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
/* (1) 用cfs_rq已經申請的時間配額(cfs_rq->runtime_remaining)減去已經消耗的時間 */
/* dock delta_exec before expiring quota (as it could span periods) */
cfs_rq->runtime_remaining -= delta_exec;
/* (2) expire超期時間的判斷 */
expire_cfs_rq_runtime(cfs_rq);
/* (3) 如果cfs_rq已經申請的時間配額還沒用完,返回 */
if (likely(cfs_rq->runtime_remaining > 0))
return;
/*
* if we're unable to extend our runtime we resched so that the active
* hierarchy can be throttled
*/
/* (4) 如果cfs_rq申請的時間配額已經用完,嘗試向tg的cfs_b->runtime申請新的時間片
如果申請新時間片失敗,說明整個tg已經沒有可執行時間了,把本程序設定為需要重新排程,
在中斷返回,發起schedule()時,發現cfs_rq->runtime_remaining<=0,會呼叫throttle_cfs_rq()對cfs_rq進行實質的限制
*/
if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr))
resched_curr(rq_of(cfs_rq));
}
||→
static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct task_group *tg = cfs_rq->tg;
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg);
u64 amount = 0, min_amount, expires;
/* (4.1) cfs_b的分配時間片的預設值是5ms */
/* note: this is a positive sum as runtime_remaining <= 0 */
min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota == RUNTIME_INF)
/* (4.2) RUNTIME_INF型別,時間是分配不完的 */
amount = min_amount;
else {
start_cfs_bandwidth(cfs_b);
/* (4.3) 剩餘時間cfs_b->runtime減去分配的時間片 */
if (cfs_b->runtime > 0) {
amount = min(cfs_b->runtime, min_amount);
cfs_b->runtime -= amount;
cfs_b->idle = 0;
}
}
expires = cfs_b->runtime_expires;
raw_spin_unlock(&cfs_b->lock);
/* (4.4) 分配的時間片賦值給cfs_rq */
cfs_rq->runtime_remaining += amount;
/*
* we may have advanced our local expiration to account for allowed
* spread between our sched_clock and the one on which runtime was
* issued.
*/
if ((s64)(expires - cfs_rq->runtime_expires) > 0)
cfs_rq->runtime_expires = expires;
/* (4.5) 判斷分配時間是否足夠? */
return cfs_rq->runtime_remaining > 0;
}
- 3、在enqueue_task_fair()、put_prev_task_fair()、pick_next_task_fair()這幾個時刻,會check cfs_rq是否已經達到throttle,如果達到cfs throttle會把cfs_rq dequeue停止執行;
enqueue_task_fair() -> enqueue_entity() -> check_enqueue_throttle() -> throttle_cfs_rq()
put_prev_task_fair() -> put_prev_entity() -> check_cfs_rq_runtime() -> throttle_cfs_rq()
pick_next_task_fair() -> check_cfs_rq_runtime() -> throttle_cfs_rq()
static void check_enqueue_throttle(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return;
/* an active group must be handled by the update_curr()->put() path */
if (!cfs_rq->runtime_enabled || cfs_rq->curr)
return;
/* (1.1) 如果已經throttle,直接返回 */
/* ensure the group is not already throttled */
if (cfs_rq_throttled(cfs_rq))
return;
/* update runtime allocation */
/* (1.2) 更新最新的cfs執行時間 */
account_cfs_rq_runtime(cfs_rq, 0);
/* (1.3) 如果cfs_rq->runtime_remaining<=0,啟動throttle */
if (cfs_rq->runtime_remaining <= 0)
throttle_cfs_rq(cfs_rq);
}
/* conditionally throttle active cfs_rq's from put_prev_entity() */
static bool check_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return false;
/* (2.1) 如果cfs_rq->runtime_remaining還有執行時間,直接返回 */
if (likely(!cfs_rq->runtime_enabled || cfs_rq->runtime_remaining > 0))
return false;
/*
* it
相關推薦
Linux schedule 2、排程演算法
2、排程演算法
linux程序一般分成了實時程序(RT)和普通程序,linux使用sched_class結構來管理不同型別程序的排程演算法:rt_sched_class負責實時類程序(SCHED_FIFO/SCHED_RR)的排程,fair_sched_cla
Linux schedule 1、排程的時刻
1、Linux schedule框架(排程的時刻)
Linux程序排程(schedule)的框架如上圖所示。
本文的程式碼分析基於linux kernel 4.4.22,最好的學習方法還是”RTFSC”
1.1、中心是rq(runqueue
55、LVS型別、排程演算法、ipvsadm命令用法
LVS型別:
NAT
DR
TUN
FULLNAT
LVS的排程方法:10種
靜態方法:僅根據演算法本身進行排程
rr 輪詢
wrr 加權輪詢
sh 源地址雜湊,可實現session繫結
dh 目標地址雜湊
動態方法:根據演算法及RS當前的負載狀況
lc 最小連線,小者勝出
linux之 修改磁碟排程演算法
IO排程器的總體目標是希望讓磁頭能夠總是往一個方向移動,移動到底了再往反方向走,這恰恰就是現實生活中的電梯模型,所以IO排程器也被叫做電梯. (elevator)而相應的演算法也就被叫做電梯演算法.而Linux中IO排程的電梯演算法有好幾種,一個叫做as(Anticipato
linux磁碟請求電梯排程演算法研究
1.電梯簡介
電梯排程演算法主要適用於INUX I/O磁碟請求排程。磁碟結構如下圖所示,磁碟主要由盤面和磁頭組成。磁碟每次進讀寫請求時,需要給磁碟驅動器一個地址,磁碟驅動器根據給定地址計算出相應的扇區,然後將磁頭移動到需要訪問的扇區,開始進行讀寫。
百度面試(程序排程、排程演算法)
一、常見的批處理作業排程演算法
1.先來先服務排程演算法(FCFS):就是按照各個作業進入系統的自然次序來排程作業。這種排程演算法的優點是實現簡單,公平。其缺點是沒有考慮到系統中各種資源的綜合使用情
linux核心分析之排程演算法(一)
linux排程演算法在2.6.32中採用排程類實現模組式的排程方式。這樣,能夠很好的加入新的排程演算法。
linux排程器是以模組方式提供的,這樣做的目的是允許不同型別的程序可以有針對性地選擇排程演算法。這種模組化結構被稱為排程器類,他允許多種不同哦可動態新增的排程演算法並
linux常用I/O排程演算法及更改
I/O 任何計算機程式都是為了執行一個特定的任務,有了輸入,使用者才能告訴計算機程式所需的資訊,有了輸出,程式執行後才能告訴使用者任務的結果。輸入是Input,輸出是Output,因此,我們把輸入輸出統稱為Input/Output,或者簡寫為IO。
第3章 處理機排程與死鎖 ---- 2、常用排程演算法
2、常用排程演算法
排程的實質就是一種資源分配。不同的系統和系統目標,通常採用不同的排程演算法——適合自己的才是最好的。
如批處理系統為照顧為數眾多的短作業,應採用短作業優先的排程演算法;
linux核心排程演算法(2)--CPU時間片如何分配
核心在微觀上,把CPU的執行時間分成許多分,然後安排給各個程序輪流執行,造成巨集觀上所有的程序彷彿同時在執行。雙核CPU,實際上最多隻能有兩個程序在同時執行,大家在top、vmstat命令裡看到的正在執行的程序,並不是真的在佔有著CPU哈。
所以,一些設計良好的高效能程序,比如nginx,都是實際上有幾顆C
linux程序排程演算法:分時排程策略、FIFO排程策略、RR排程策略
linux核心的三種排程方法:
SCHED_OTHER 分時排程策略,
SCHED_FIFO實時排程策略,先到先服務
SCHED_RR實時排程策略,時間片輪轉
注意:
實時程序將得到優先呼叫,實時程序根據實時優先順序決
linux 2.6核心的四種IO排程演算法
轉自:http://jackyrong.iteye.com/blog/898938
http://blog.csdn.net/theorytree/article/details/6259104
IO排程器的總體目標是希望讓磁頭能夠總是往一個方向移動,移動到底了再往反方
linux環境下部署zabbix3.2、模板、郵件告警詳細過程
-1 ice erer without zlib zip ever native item 服務端部署:
系統環境及軟件版本:
Linux:release 6.3
zabbix:zabbix-3.2.5.tar.gz
nginx:nginx-1.12.0.tar.gz
ph
12.2、linux作業管理、調整進程優先級
jobs nice 1、linux作業分類: 前臺作業:foreground,通過終端啟動,且啟動後會一直占據終端 後臺作業:background,可以通過終端啟動,但啟動後會轉入後臺,釋放終端占用作業可能包含多個程序,也可以只包含一個程序。2、作業被轉入後臺方法: 運行中的作業:c
Linux 124課程 2、從命令行管理文件
無法 img 運行 多級 命令 linux mage string sage 文件目錄
/ 代表根目錄 整個系統全部在根目錄中/boot 存放啟動配置文件 建議,單獨做成一個分區/dev
Linux下安裝Python3.5.2、Django、paramiko
roo help 更新 pip3 sim egg pan man inf 1,安裝依賴文件:
yum install zlib zlib-devel openssl openssl-devel
2,下載Python3.5.2:
安全連接時,要增加:--no-chec
nginx、thinkphp3.2、linux配置檔案配置
nginx.conf配置檔案:
server { listen 9001; server_name 127
2、【Linux Git】Git的安裝、本地倉庫、遠端倉庫的使用
一、安裝git
在Linux作業系統中安裝git,直接使用下面的命令就可以:
sudo apt-get install git
安裝完成後,還需要最後一步設定,在命令列輸入:
git config --global user.name "Your Name"
一列數的規則如下: 1、1、2、3、5、8、13、21、34...... 求第30位數是多少, 用遞迴演算法實現。//斐波那契數列
1 public class MainClass
2 {
3 public static void Main()
4 {
5 Console.WriteLine(Foo(30));
6 }
7 public static int Foo(int i)
8 {
作業系統程序排程演算法實現2
實驗三 程序排程
一、實驗目的
1、 理解有關程序控制塊、程序佇列的概念。 2、 掌握程序優先權排程演算法和時間片輪轉排程演算法的處理邏輯。 二、實驗內容與基本要求
1、 設計程序控制塊PCB的結構,分別適用於優先權排程演算法和時間片輪轉排程演算法。 2、 建立程序就緒佇列。 3、 編制