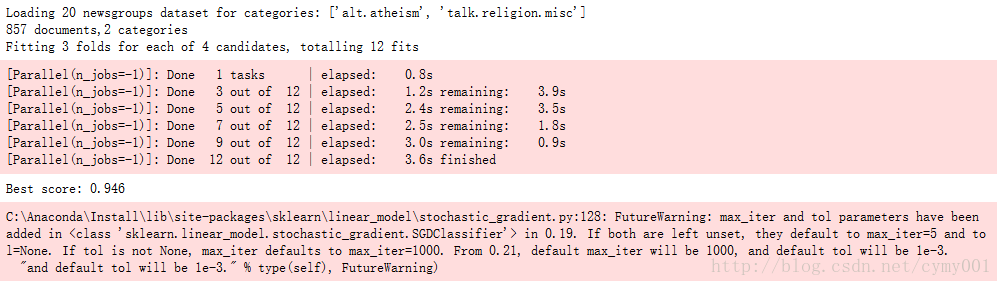
模型調優:交叉驗證,超引數搜尋(複習17)
阿新 • • 發佈:2019-02-19
用模型在測試集上進行效能評估前,通常是希望儘可能利用手頭現有的資料對模型進行調優,甚至可以粗略地估計測試結果。通常,對現有資料進行取樣分割:一部分資料用於模型引數訓練,即訓練集;一部分資料用於調優模型配置和特徵選擇,且對未知的測試效能做出估計,即驗證集。
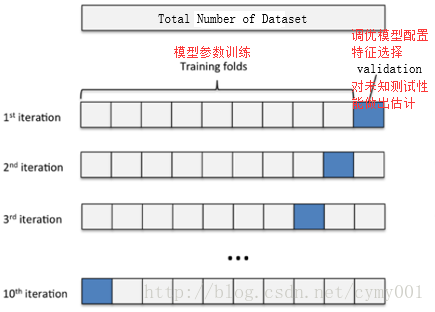
交叉驗證可以保證所有資料都有被訓練和驗證的機會,也盡最大可能讓優化的模型效能表現的更加可信。下圖給出了十折交叉驗證的示意圖。
模型的超引數是指實驗時模型的配置,通過網格搜尋的方法對超引數組合進行調優,該過程平行計算。由於超引數的空間是無盡的,因此超引數的組合配置只能是“更優”解,沒有最優解。通常,依靠網格搜尋對多種超引數組合的空間進行暴力搜尋。每一套超引數組合被代入到學習函式中作為新的模型,為了比較新模型之間的效能,每個模型都會採用交叉驗證的方法在多組相同的訓練和測試資料集下進行評估
from sklearn.model_selection import GridSearchCV
from sklearn import svm
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
svc=svm.SVC()
param_grid = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
grid_search = GridSearchCV(svc, param_grid=param_grid, verbose=10 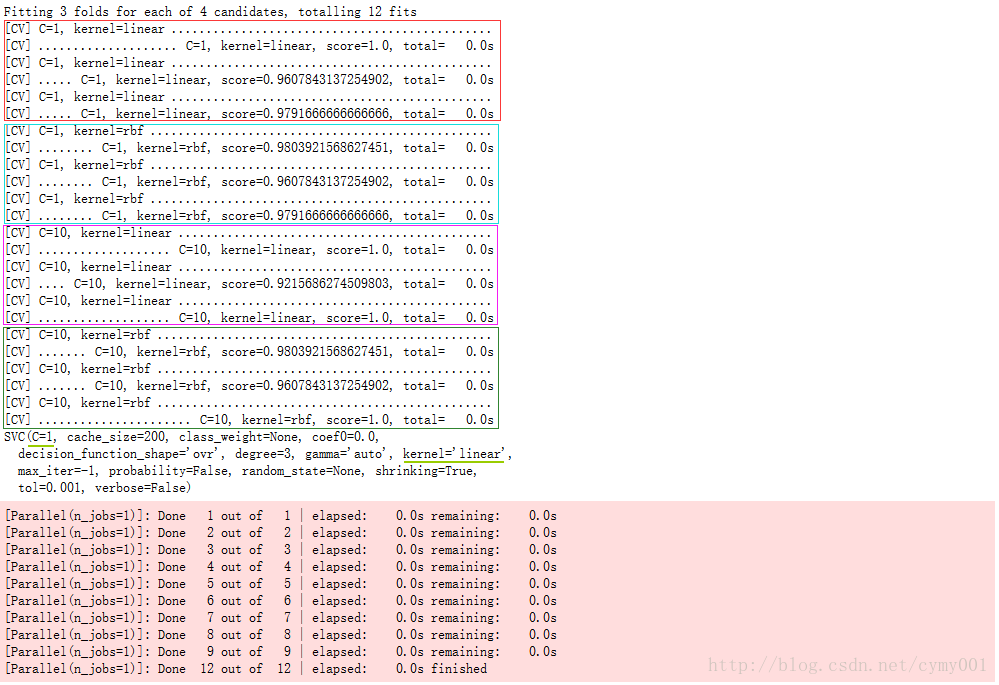
from __future__ import print_function
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import