
正則表示式中\b跟\s的或運算
正則表示式:
\s 匹配空格;
\b 匹配邊界 包括空格、回車、字串開頭跟結尾(但不包括空格、回車)。
不多說上圖。
第一張:匹配 \s|\b

第二張:匹配 \b|\s

第三張:匹配 \s

第四張:匹配 \b
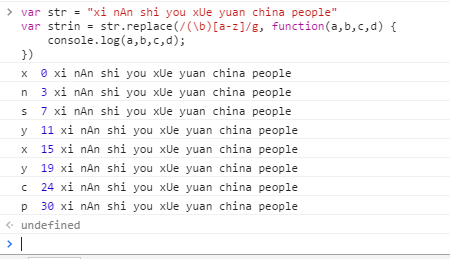
先看第一張跟第二張,也就是匹配 \s|\b 跟 \b|\s 得到的結果一樣,也就是說或運算的匹配跟前後位置沒有關係。
再看第三張,匹配 \s 全部匹配的是空格加n、s、y 等等 (這個可以對比前兩張圖的x跟n的位置,可以看到n 前面是有空格的)。
第四張,匹配 \d 全部匹配的是n、s、y等等,沒有空格。
再回頭來看第一二張 是先匹配的一個n 然後再匹配空格加s、y等。所以不難看出:\s跟\b做或運算時,不管位置順序,先匹配\b 然後才匹配\s。
相關推薦
正則表示式中\b跟\s的或運算
正則表示式: \s 匹配空格; \b 匹配邊界 包括空格、回車、字串開頭跟結尾(但不包括空格、回車)。 不多說上圖。 第一張:匹配 \s|\b 第二張:匹配 \b|\s 第三張:匹配 \s 第四張:匹配 \b 先看第一張跟第二張,
Python正則表示式中的re.S的作用
在Python的正則表示式中,有一個引數為re.S。它表示“.”(不包含外側雙引號,下同)的作用擴充套件到整個字串,包括“\n”。看如下程式碼: import re a = '''asdfhellopass: 123 worldaf '''
正則表示式中的邏輯運算子或(怎麼用邏輯運算子或連線兩個正則表示式)
今天使用正則表示式是遇到一個問題, 磨了半天, 發現犯了個低階錯誤, 因此記錄下來加深印象 問題描述: 我需要把 ^drawable(-[a-zA-Z0-9]+)*$ 和 ^mipmap(-[a-zA-Z0-9]+)*$ 這兩個正則表示式用或的關係連線起來 我嘗試了
關於在正則表示式中實現為空或滿足一定規則的寫法
實現驗證電話:(^(0[0-9]{2,3}\-)?([2-9][0-9]{6,7})+(\-[0-9]{1,4})?$)|(^((\(\d{3}\))|(\d{3}\-))?(1[358]\d{9})$) 可以為空,但當不為空時必須要電話的格式: (^(0[0-9]
詳解正則表示式中的\B和\b
對於正則表示式的中\B和\b 有些地方會出現弄不懂的情況 或許你看了下面這篇部落格 你就能夠對\B和\b認識加深了 根據檢視API可以知道 \B和\b都是邊界匹配符 先說說\b這個單詞邊界吧!竟然想了解 首先必須清楚什麼叫單詞邊界!我們可以以\b為分
js正則表示式中關於零寬斷言的奇異現象
碰到一個特別的需求,就是有一段Sql Server 的 SQL片段,內容大概就是所有JOIN表的集合,要求把這個SQL片段分割成陣列,每個元素就是包含單個表的字串。 例如: SQL = INNER JOIN Sale b ON 1=1 LEFT JOIN OutStock c
php 正則表示式中的 .*? 表示什麼意思
我們知道我 .* 是任意字元,有的時候比較困惑在加個?什麼意思。 ?是非貪婪模式.*會匹配後面的一切字元,就是到結束的意思加?後就是不貪婪模式,這時要看?後邊的字元是什麼了,如.*?"的意思是遇到雙引號則匹配結束 例如: 現在我要匹配出圖片中的src,圖片格式為:"圖片01<img src='ht
正則表示式中常用字串方法
1,search()用於檢索字串中指定的子字串,或檢索與正則表示式相匹配的子字串,並返回子串的起始位置。search()方法不支援全域性搜尋,因為會忽略正則表示式引數的標識g,並且也忽略了regexp的lastIndex屬性,總是從字串的開始位置進行檢索,所以它會總是返回str的第一個匹配的位置。 &n
關於python正則表示式中匹配分組的問題
在爬取網頁資訊時,我們不妨會用到Python正則表示式。之前一直沒有太明白關於正則表示式匹配分組的問題,今天終於搞清楚了,所以特意寫一下讓自己印象深刻。 myPage = requests.get(url).content.decode("gbk") 通過requests我們在網頁得到了這樣
正則表示式中Pattern類、Matcher類和matches()方法簡析
1.簡介: java.util.regex是一個用正則表示式所訂製的模式來對字串進行匹配工作的類庫包。 它包括兩個類:Pattern和Matcher 。 Pattern: 一個Pattern是一個正則表示式經編譯後的表現模式。 Matcher: 一個Matcher物件
正則表示式中如何新增變數
如果給義一個字串或是陣列加入變數,是非常簡單的事情,但是我們不能用這種常規思維來給正則表示式加入變數,比如 var param = 3; var reg = "/^[0-9]+"+param+"[a-z]+$/"; ✘ var reg = /^[0-9]+"+param+"[a-z]+$
正則表示式中的模式,函式,及使用規則
一、正則表示式轉義 正則中的特殊符號: . * ? $ [] {} () | \ 正則表示式匹配特殊字元如果需要加 \ 表達轉義,比如: pattern
正則表示式中的分組() ----填坑
import re string="abcdefg acbdgef abcdgfe cadbgfe" #帶括號與不帶括號的區別 #不帶括號 regex=re.compile("((\w+)\s+\w+)") print(regex.findall(string)) #輸出:[('abcde
PHP正則表示式中的元字元
假設我們需要在一個字串中查詢he,我們可以使用正則he,這是最簡單的正則表示式,它會精確地匹配這樣的字串:有兩個字元組成,前一個字元是h後一個字元是e。一般情況下,處理正則表示式的工具會提供一個忽略大小寫的選項,如果選擇了,這個表示式就可以匹配he、HE、He、hE這四種情況的任意一種,但是呢,
java正則表示式中出現空格
在正則表示式中是可以使用空格的,儘管空格可以用 \s表示。 在java正則中,我初次遇到帶有空格的正則時可謂是一臉懵B,當時就提出疑問,java中的空格不是可以用\s來表示嗎? 隨後我測試了一下,程式碼如下,一目瞭然。 public class TheBlankSpace { publ
(轉)正則表示式中^的用法
https://www.cnblogs.com/ytc6/p/8478989.html 用法一: 限定開頭 文件上給出瞭解釋是匹配輸入的開始,如果多行標示被設定成了true,同時會匹配後面緊跟的字元。&n
java正則表示式中要轉義的字元。
$ :匹配輸入字串的結尾位置。如果設定了 RegExp 物件的 Multiline 屬性,則 $ 也匹配 ‘\n' 或 ‘\r'。 ( ) :標記一個子表示式的開始和結束位置。 * :匹配前面的子表示式零次或多次。 + :匹配前面的子表示式一次或多次。
關於java正則表示式中的 ^和$的使用
java正則表示式的邊界匹配符中,有兩個比較常用的字元:“ ^ ”和“ $ ”,這兩個字元理解起來比較容易混淆。先說下這兩個字元的含義: “ ^ ”:匹配輸入字串開始的位置。如果設定了 RegExp 物件的 Multiline 屬性,^ 還會與”\n”或”\r
正則表示式中的\\\\/四個反斜槓含義
<? php echo '\\'; 執行結果:\ 由此可見,在字串中,兩個反斜槓被解釋為一個反斜槓,然後在作為正則表示式, \\ 則被正則表示式引擎解釋為 \,所以在正則表示式中需要使用四個反斜槓。 也就是說,前兩個反斜槓在字串中被解釋為一個反斜槓,後兩個也
正則表示式中常用符號
一: 正則在Perl、Py森、Ruby、Java等語言中文字的正則表示式幾乎是一樣的 以前常用到的在網上都有現成的例子拿來用,比如電話格式、郵箱格式之類的。 但是自然語言處理中往往會根據自己的需求來制定一個表示式,如果正則的知識掌握的比較片面,在編寫自然語言