
黑馬程式設計師——java的集合類
------- android培訓、java培訓、期待與您交流! ----------
前言:通過觀看畢向東老師的java基礎視訊,查漏補缺,將一些自己掌握的還不牢固的知識寫出來,希望和大家交流分享。
1.集合框架
1.集合類的出現原因:為了方便對多個物件的操作,就對物件進行儲存,集合就是儲存物件最常用的一種方式。
2.java集合框架的構成,由於資料結構的不同,有不同的集合,也叫容器。如下圖:

3.與陣列相比,集合的優勢: 陣列雖然也可以儲存物件,但長度是固定的;集合長度是可變的。陣列中可以儲存基本資料型別,集合只能儲存物件。
2.Collection類
1.Collection的結構:
Collection
|--List//元素是有序的,元素可以重複。因為該集合體繫有索引。
|--Set//元素是無序的,元素不可以重複。
2.Collection介面中常見方法1)add(Object obj); //新增元素,add方法的引數型別是Object。以便於接收任意型別物件。
2) 刪除元素
remove(Objectobj);
removeAll(另一集合);//呼叫者只保留另一集合中沒有的元素。
clear();//清空集合
3)判斷元素
contains(Objectobj);//判斷是否存在obj這個元素
isEmpty();//是否為空
4)size();//獲取個數,集合長度
注:集合中儲存的都是物件的引用(地址)。
3.迭代1) 迭代是取出集合中元素的一種方式。
2)Iterator規則:對於集合的元素取出這個動作被定義成了內部類,可以直接訪問集合內部的元素。對每一個容器的資料結構不同,所以取出的動作細節也不一樣。
但是都具有共性內容: 判斷和取出。那麼就可以將這些共性抽取。 那麼這些內部類都符合一個規則(或者說都抽取出來一個規則)。該規則就是Iterator。
通過一個對外提供的方法:iterator();,來獲取集合的取出物件。因為Collection中有iterator方法,所以每一個子類集合物件都具備迭代器。
3)三個方法:
next();//取出下一個元素
remove();//移除
注:在迭代時迴圈中next呼叫一次,就要hasNext判斷一次
如:
ArrayList a=newArrayList();//建立一個集合
Iteratorit=a.iterator();//獲取一個迭代器,用於取出集合中的元素。
//第一種列印方式:
for(Iterator iter = a.iterator();iter.hasNext();){
System.out.println(iter.next());
}
//第二種列印方式:
Iterator iter = a.iterator();
while(iter.hasNext()){
System.out.println(iter.next());
} 迭代器在Collcection介面中是通用的,它替代了Vector類中的Enumeration(列舉)。
迭代器的next方法是自動向下取元素,要避免出現NoSuchElementException。
迭代器的next方法返回值型別是Object,所以要記得型別轉換。
3.List類
1.list的組成結構
List:元素是有序的,元素可以重複。因為該集合體繫有索引。
|--ArrayList:底層的資料結構使用的是陣列結構。特點:查詢速度很快。但是增刪稍慢。執行緒不同步。
|--LinkedList:底層使用的是連結串列資料結構。特點:增刪速度很快,查詢稍慢。
|--Vector:底層是陣列資料結構。執行緒同步。被ArrayList替代了。
2.List的特有方法:凡是可以操作角標的方法都是該體系特有的方法。
1)增
boolean add(index,element);//指定位置新增元素
Boolean addAll(index,Collection);//在指定位置增加給定集合中的所有元素,若省略位置引數,則在當前集合的後面依次新增元素
2)刪
Boolean remove(index);//刪除指定位置的元素
3)改
set(index,element);//修改指定位置的元素。
4)查
get(index);//通過角標獲取元素
subList(from,to);//獲取部分物件元素
5)其他
listIterator();//List特有的迭代器
indexOf(obj);//獲取元素第一次出現的位置,如果沒有則返回-1
注:List集合判斷元素是否相同,移除等操作,依據的是元素的equals方法。
3.ListIterator 是List集合特有的迭代器,是Iterator的子介面,對Iterator進行了擴充套件。
ListIterator特有的方法:
add(obj);//增加
set(obj);//修改為obj
hasPrevious();//判斷前面有沒有元素
previous();//取前一個元素
4.Vector中的列舉Enumeration
1、列舉就是Vector特有的取出方式
2、發現列舉和迭代器很像。
3、其實列舉和迭代是一樣的,因為列舉的名稱以及方法的名稱都過長,所以被迭代器取代了
它底層使用的是連結串列資料結構。特點:增刪速度很快,查詢稍慢。
特有方法:
1、增
addFirst();
addLast();
2、獲取
//獲取元素,但不刪除元素。如果集合中沒有元素,會出現NoSuchElementException
getFirst();
getLast();
3、刪
//獲取元素,並刪除元素。如果集合中沒有元素,會出現NoSuchElementException
removeFirst();
removeLast();
在JDK1.6以後,出現了替代方法。
1、增
offFirst();
offLast();
2、獲取
//獲取元素,但是不刪除。如果集合中沒有元素,會返回null。
peekFirst();
peekLast();
3、刪
//獲取元素,並刪除元素。如果集合中沒有元素,會返回null。
pollFirst();
pollLast();
LinkedList程式碼示例:package collection;
import java.util.LinkedList;
/**
* 使用LinkedList模擬一個堆疊或者佇列資料結構。
* 堆疊:先進後出 如同一個杯子。
* 佇列:先進先出 FIFO 如同一個水管。
* @author songwenju
*
*/
public class LinkedListDemo {
//模擬棧
public static void stack(LinkedList<String> list){
while (!list.isEmpty()) {
System.out.println(list.removeFirst());
}
}
//模擬佇列
public static void queue(LinkedList<String> list){
while (!list.isEmpty()) {
System.out.println(list.removeLast());
}
}
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>();
list.addFirst("java01");
list.addFirst("java02");
list.addFirst("java03");
list.addFirst("java04");
list.addFirst("java05");
//堆疊輸出
//stack(list);
//佇列輸出
queue(list);
}
}
1.Set的組成結構
Set:元素是無序(存入和取出的順序不一定一致),元素不可以重複。
|--HashSet:底層資料結構是雜湊表。執行緒不同步。 保證元素唯一性的原理:判斷元素的hashCode值是否相同。如果相同,還會繼續判斷元素的equals方法,是否為true。
|--TreeSet:可以對Set集合中的元素進行排序。預設按照字母的自然排序。底層資料結構是二叉樹。保證元素唯一性的依據:compareTo方法return 0。
Set集合的功能和Collection是一致的。
2.HashSet
1)HashSet:執行緒不安全,存取速度快。
2)可以通過元素的兩個方法,hashCode和equals來完成保證元素唯一性。
如果元素的HashCode值相同,才會判斷equals是否為true。如果元素的hashCode值不同,不會呼叫equals。
3)HashSet對於判斷元素是否存在,以及刪除等操作,依賴的方法是元素的hashCode和equals方法。
程式碼示例:
package collection;
import java.util.HashSet;
/**
* 往hashSet集合中存入自定義物件
* 姓名和年齡相同為同一個人,重複元素。去除重複元素
* 思路:
* 1、對人描述,將人的一些屬性等封裝進物件
* 2、定義一個HashSet容器,儲存人物件
* 3、取出
* @author songwenju
*
*/
class Person{
private String name;
private int age;
public Person() {}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
//以下hashCode和equals是由eclipse生成的程式碼。
/* (non-Javadoc)
* @see java.lang.Object#hashCode()
*/
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
/* (non-Javadoc)
* @see java.lang.Object#equals(java.lang.Object)
*/
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (!(obj instanceof Person)) {
return false;
}
Person other = (Person) obj;
if (age != other.age) {
return false;
}
if (name == null) {
if (other.name != null) {
return false;
}
} else if (!name.equals(other.name)) {
return false;
}
return true;
}
}
public class HashSetDemo {
public static void main(String[] args) {
HashSet<Person> h = new HashSet<Person>();
h.add(new Person("stu1", 10));
h.add(new Person("stu2", 6));
h.add(new Person("stu3", 30));
h.add(new Person("stu1", 10));
h.add(new Person("stu4", 10));
for (Person p : h) {
System.out.println(p.getName()+"-->"+p.getAge());
}
}
}
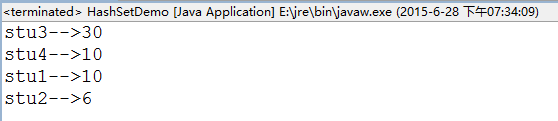
分析:重複元素去重。
1) 底層的資料結構為二叉樹結構(紅黑樹結構)
2)可對Set集合中的元素進行排序,是因為:TreeSet類實現了Comparable介面,該介面強制讓增加到集合中的物件進行了比較,需要複寫compareTo方法,才能讓物件按指定需求(如人的年齡大小比較等)進行排序,並加入集合。
3) java中的很多類都具備比較性,其實就是實現了Comparable介面。
4)排序時,當主要條件相同時,按次要條件排序。
5)保證資料的唯一性的依據:通過compareTo方法的返回值,是正整數、負整數或零,則兩個物件較大、較小或相同。相等時則不會存入。
6)Tree排序的兩種方式
1、方式一,自然排序:讓元素自身具備比較性。元素需要實現Comparable介面,覆蓋compareTo方法。這種方式也被稱為元素的自然順序,或者叫做預設順序。
程式碼示例:
package collection;
import java.util.TreeSet;
/**
* 自然排序
* @author songwenju
*
*/
//這裡要實現Compare介面,否則會報collection.Student cannot be cast to java.lang.Comparable錯誤
class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
//覆寫compareTo
@Override
public int compareTo(Student student) {
if (this.age == student.age) {
return this.name.compareTo(student.name);
}
return this.age - student.age;
}
}
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Student> t = new TreeSet<Student>();
t.add(new Student("stu1", 12));
t.add(new Student("stusj", 2));
t.add(new Student("stu1swj", 12));
t.add(new Student("stu6ds", 12));
t.add(new Student("stu", 22));
for (Student p : t) {
System.out.println(p.getName()+"-->"+p.getAge());
}
}
}
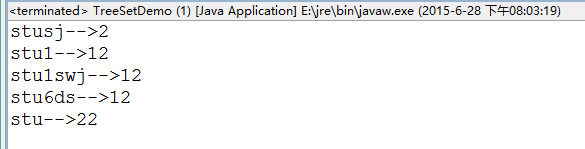
2、方式二,比較器:當元素自身不具備比較性時,或者具備的比較性不是所需要的。這時就需要讓集合自身具備比較性。
在集合初始化時,就有了比較方式。定義一個比較器,將比較器物件作為引數傳遞給TreeSet集合的建構函式。
比較器構造方式:定義一個類,實現Comparator介面,覆蓋compare方法。
當兩種排序都存在時,以比較器為主。
程式碼示例:
package collection;
import java.util.Comparator;
import java.util.TreeSet;
/**
* 往TreeSet集合中儲存自定義物件學生。
* 想按照學生的年齡進行排序。
* @author songwenju
*
*/
//這裡要實現Compare介面,否則會報collection.Student cannot be cast to java.lang.Comparable錯誤
class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
//覆寫compareTo
@Override
public int compareTo(Student student) {
if (this.age == student.age) {
return this.name.compareTo(student.name);
}
return this.age - student.age;
}
}
//定義一個比較器
class LenCompare implements Comparator<Student>{
@Override
public int compare(Student s1, Student s2) {
int num = new Integer(s1.getName().length()).compareTo(new Integer(s2.getName().length()));
if (num == 0) {
return new Integer(s1.getAge()).compareTo(s2.getAge());
}
return 0;
}
}
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<Student> t = new TreeSet<Student>();
t.add(new Student("stu1", 12));
t.add(new Student("stu1", 12));
t.add(new Student("stusj", 2));
t.add(new Student("stu1swj", 12));
t.add(new Student("stu6ds", 12));
t.add(new Student("stu", 22));
for (Student p : t) {
System.out.println(p.getName()+"-->"+p.getAge());
}
}
}

5.Map集合
1. Map<K,V>集合是一個介面,和List集合及Set集合不同的是,它是雙列集合,並且可以給物件加上名字,即鍵(Key)
2.該集合儲存鍵值對,一對一對往裡存。要保證鍵的唯一性。
3.Map的組成結構
Map
|--Hashtable:底層是雜湊表資料結構,不可以存入null鍵 null值。該集合是執行緒同步的。JDK1.0,效率低。
|--HashMap:底層是雜湊表資料結構。允許使用null鍵null值,該集合是不同步的。JDK1.2,效率高。
|--TreeMap:底層是二叉樹資料結構。執行緒不同步。可以用於給Map集合中的鍵進行排序。
Map和Set很像。其實Set底層就是使用了Map集合。
4.Map集合常用方法
1、新增
V put(K key,V value);//新增元素,如果出現新增時,相同的鍵,那麼後新增的值會覆蓋原有鍵對應值,並put方法會返回被覆蓋的值。
void putAll(Map <? extends K,? extends V> m);//新增一個集合
2、刪除
clear();//清空
V remove(Object key);//刪除指定鍵值對
3、判斷
containsKey(Objectkey);//判斷鍵是否存在
containsValue(Objectvalue)//判斷值是否存在
isEmpty();//判斷是否為空
4、獲取
V get(Object key);//通過鍵獲取對應的值
size();//獲取集合的長度
Collection<V>value();//獲取Map集合中所以得值,返回一個Collection集合
還有兩個取出方法,接下來會逐個講解:
Set<Map.Entry<K,V>> entrySet();
Set<K> keySet();
注:HashMap集合可以通過get()方法的返回值來判斷一個鍵是否存在,通過返回null來判斷。
5.Map集合的兩種取出方式Map集合的取出原理:將Map集合轉成Set集合。再通過迭代器取出。
1、Set<K> keySet():將Map中所以的鍵存入到Set集合。因為Set具備迭代器。先通過迭代方式取出所以鍵的值,再通過get方法。獲取每一個鍵對應的值。
程式碼示例:
package collection;
import java.util.HashMap;
/**
* 對Map進行遍歷輸出
* @author songwenju
*
*/
public class MapDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<String, String>();
map.put("河南", "鄭州");
map.put("河北", "石家莊");
map.put("湖南", "長沙");
map.put("湖北", "武漢");
//對keyset進行遍歷,得到每一個key再得到對於的value。
for (String k : map.keySet()) {
System.out.print(k + "-->");
System.out.println(map.get(k));
}
}
}

2、Set<Map.Entry<K,V>> entrySet():將Map集合中的對映關係存入到Set集合中,而這個關係的資料型別就是:Map.Entry 其實,Entry也是一個介面,它是Map介面中的一個內部介面。關係如下:
interface Map {
public static interface Entry{
public abstract Object getKey();
public abstract Object getValue();
}
}
package collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
/**
* 對Map進行遍歷輸出
* @author songwenju
*
*/
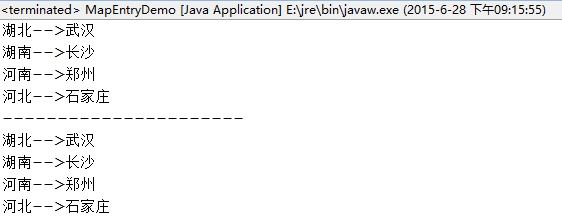
public class MapEntryDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<String, String>();
map.put("河南", "鄭州");
map.put("河北", "石家莊");
map.put("湖南", "長沙");
map.put("湖北", "武漢");
/*
* 用for each實現
*/
//對keyset進行遍歷,得到每一個key再得到對於的value。
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Entry<String, String> k : entries) {
System.out.print(k.getKey() + "-->");
System.out.println(k.getValue());
}
System.out.println("----------------------");
/*
* 用Iterator迭代實現
*/
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> me = it.next();
System.out.print(me.getKey() + "-->");
System.out.println(me.getValue());
}
}
}
5.Entry是一個介面,它是Map的子介面中的一個內部介面,就相當於是類中有內部類一樣。為何要定義在其內部呢?
原因:a、Map集合中村的是對映關係這樣的兩個資料,是先有Map這個集合,才可有對映關係的存在,而且此類關係是集合的內部事務。
b、並且這個對映關係可以直接訪問Map集合中的內部成員,所以定義在內部。
6.當量資料之間存在著對映關係的時候,就應該想到使用Map集合。
‘如:獲取該字串中的字母出現的次數,如:"sjokafjoilnvoaxllvkasjdfns";希望列印的結果是:a(3)c(0).....
通過結果發現,每個字母都有對應的次數,說明字母和次數之間有對映關係。
程式碼示例:
package collection;
import java.util.Map.Entry;
import java.util.TreeMap;
/**
* 需求: 獲取該字串中的字母出現的次數,如:"sjokafjoilnvoaxllvkasjdfns";希望列印的結果是:a(3)c(1).....
* 思路:
* 1、將字串轉換為字元陣列
* 2、定義一個TreeMap集合,用於儲存字母和字母出現的次數
* 3、用陣列去遍歷集合,如果集合中有該字母則次數加1,如果集合中沒有則存入
* 4、將TreeMap集合中的元素轉換為字串
* @author songwenju
*
*/
public class CharCount {
public static void main(String[] args) {
String s = "agk;sjaksd;gsa";
System.out.println("s中各字母出現的個數:"+charCount(s));
}
public static String charCount(String str) {
char[] chs = str.toCharArray();//轉化為字元陣列
//定義一個TreeMap集合,因為TreeMap集合會給鍵自動排序
TreeMap<Character, Integer> map = new TreeMap<Character, Integer>();
int count = 0;//定義計數變數
for (int i = 0; i < chs.length; i++) {
if (!(chs[i]>='a' && chs[i]<= 'z'||chs[i]>='A' && chs[i]<= 'Z')) {
continue;//如果字串中非字母,則不計數
}else {
Integer value = map.get(chs[i]);//獲取集合中的值
if (value != null) {//如果集合中沒有該字母,則存入
count = value;
}
count++;
map.put(chs[i], count);
count = 0;
}
}
StringBuilder sBuilder = new StringBuilder();
for (Entry<Character, Integer> c : map.entrySet()) {
sBuilder.append(c.getKey()+"("+c.getValue()+")");
}
return sBuilder.toString();
}
}
執行結果:

------- android培訓、java培訓、期待與您交流! ----------