
網路程式設計中的基本概念
什麼是socket?
- socket可以看成是使用者程序與核心網路協議棧的程式設計介面。
- socket不僅可以用於本機的程序間通訊,還可以用於網路上不同主機的程序間通訊。


Socket本身有“插座”的意思,在Linux環境下,用於表示程序間網路通訊的特殊檔案型別。本質為核心藉助緩衝區形成的偽檔案。
既然是檔案,那麼理所當然的,我們可以使用檔案描述符引用套接字。與管道類似的,Linux系統將其封裝成檔案的目的是為了統一介面,使得讀寫套接字和讀寫檔案的操作一致。區別是管道主要應用於本地程序間通訊,而套接字多應用於網路程序間資料的傳遞。
套接字的核心實現較為複雜,不宜在學習初期深入學習。
在TCP/IP協議中,“IP地址+TCP或UDP埠號”唯一標識網路通訊中的一個程序。“IP地址+埠號”就對應一個socket。欲建立連線的兩個程序各自有一個socket來標識,那麼這兩個socket組成的socket pair就唯一標識一個連線。因此可以用Socket來描述網路連線的一對一關係。
套接字通訊原理如下圖所示:

在網路通訊中,套接字一定是成對出現的。一端的傳送緩衝區對應對端的接收緩衝區。我們使用同一個檔案描述符索傳送緩衝區和接收緩衝區。
TCP/IP協議最早在BSD UNIX上實現,為TCP/IP協議設計的應用層程式設計介面稱為socket API。本章的主要內容是socket API,主要介紹TCP協議的函式介面,最後介紹UDP協議和UNIX Domain Socket的函式介面。
IPv4套介面地址結構
IPv4套介面地址結構通常也稱為“網際套接字地址結構”,它以“sockaddr_in”命名,定義在標頭檔案<netinet/in.h>中
struct sockaddr_in - sin_len:整個sockaddr_in結構體的長度,在4.3BSD-Reno版本之前的第一個成員是sin_family.
- sin_family:指定該地址家族,在這裡必須設為AF_INET(TCP/IP)
- sin_port:埠
- sin_addr:IPv4的地址;
- sin_zero:暫不使用,一般將其設定為0
通用地址結構
通用地址結構用來指定與套接字關聯的地址。
struct sockaddr {
uint8_t sin_len;
sa_family_t sin_family;
char sa_data[14]; //14
}; - sin_len:整個sockaddr結構體的長度
- sin_family:指定該地址家族
- sa_data:由sin_family決定它的形式。
再說sockaddr資料結構
strcut sockaddr 很多網路程式設計函式誕生早於IPv4協議,那時候都使用的是sockaddr結構體,為了向前相容,現在sockaddr退化成了(void *)的作用,傳遞一個地址給函式,至於這個函式是sockaddr_in還是sockaddr_in6,由地址族確定,然後函式內部再強制型別轉化為所需的地址型別。

- sockaddr資料結構
struct sockaddr {
sa_family_t sa_family; /* address family, AF_xxx */
char sa_data[14]; /* 14 bytes of protocol address */
};使用 sudo grep -r “struct sockaddr_in {” /usr 命令可檢視到struct sockaddr_in結構體的定義。一般其預設的儲存位置:/usr/include/linux/in.h 檔案中。
struct sockaddr_in {
__kernel_sa_family_t sin_family; /* Address family */ 地址結構型別
__be16 sin_port; /* Port number */ 埠號
struct in_addr sin_addr; /* Internet address */ IP地址
/* Pad to size of `struct sockaddr'. */
unsigned char __pad[__SOCK_SIZE__ - sizeof(short int) -
sizeof(unsigned short int) - sizeof(struct in_addr)];
};
struct in_addr { /* Internet address. */
__be32 s_addr;
};
struct sockaddr_in6 {
unsigned short int sin6_family; /* AF_INET6 */
__be16 sin6_port; /* Transport layer port # */
__be32 sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
__u32 sin6_scope_id; /* scope id (new in RFC2553) */
};
struct in6_addr {
union {
__u8 u6_addr8[16];
__be16 u6_addr16[8];
__be32 u6_addr32[4];
} in6_u;
#define s6_addr in6_u.u6_addr8
#define s6_addr16 in6_u.u6_addr16
#define s6_addr32 in6_u.u6_addr32
};
#define UNIX_PATH_MAX 108
struct sockaddr_un {
__kernel_sa_family_t sun_family; /* AF_UNIX */
char sun_path[UNIX_PATH_MAX]; /* pathname */
};
Pv4和IPv6的地址格式定義在netinet/in.h中,IPv4地址用sockaddr_in結構體表示,包括16位埠號和32位IP地址,IPv6地址用sockaddr_in6結構體表示,包括16位埠號、128位IP地址和一些控制欄位。UNIX Domain Socket的地址格式定義在sys/un.h中,用sock-addr_un結構體表示。各種socket地址結構體的開頭都是相同的,前16位表示整個結構體的長度(並不是所有UNIX的實現都有長度欄位,如Linux就沒有),後16位表示地址型別。IPv4、IPv6和Unix Domain Socket的地址型別分別定義為常數AF_INET、AF_INET6、AF_UNIX。這樣,只要取得某種sockaddr結構體的首地址,不需要知道具體是哪種型別的sockaddr結構體,就可以根據地址型別欄位確定結構體中的內容。因此,socket API可以接受各種型別的sockaddr結構體指標做引數,例如bind、accept、connect等函式,這些函式的引數應該設計成void 型別以便接受各種型別的指標,但是sock API的實現早於ANSI C標準化,那時還沒有void 型別,因此這些函式的引數都用struct sockaddr *型別表示,在傳遞引數之前要強制型別轉換一下,例如:
struct sockaddr_in servaddr;
bind(listen_fd, (struct sockaddr *)&servaddr, sizeof(servaddr)); /* initialize servaddr */
網路位元組序
- 大端位元組序(Big Endian)
最高有效位(MSB:Most Significant Bit)儲存於最低記憶體地址處,最低有效位(LSB:Lowest Significant Bit)儲存於最高記憶體地址處。 - 小端位元組序(Little Endian)
最高有效位(MSB:Most Significant Bit)儲存於最高記憶體地址 處,最低有效位(LSB:Lowest Significant Bit)儲存於最低記憶體地址處。 - 主機位元組序
不同的主機有不同的位元組序,如x86為小端位元組序,Motorola 6800為大端位元組序,ARM位元組序是可配置的。 - 網路位元組序
網路位元組序規定為大端位元組序
位元組序轉換函式
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);說明:在上述的函式中,h代表host;n代表network s代表short;l代表long
地址轉換函式
早期:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int inet_aton(const char *cp, struct in_addr *inp);
in_addr_t inet_addr(const char *cp);
char *inet_ntoa(struct in_addr in);- 只能處理IPv4的ip地址
- 不可重入函式
- 注意引數是struct in_addr
現在:
#include <arpa/inet.h>
int inet_pton(int af, const char *src, void *dst);
const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);- 支援IPv4和IPv6
- 可重入函式
- 其中inet_pton和inet_ntop不僅可以轉換IPv4的in_addr,還可以轉換IPv6的in6_addr。
- 因此函式介面是void *addrptr。
套接字型別
- 流式套接字(SOCK_STREAM)
提供面向連線的、可靠的資料傳輸服務,資料無差錯,無重複的傳送,且按傳送順序接收。 - 資料報式套接字(SOCK_DGRAM)
提供無連線服務。不提供無錯保證,資料可能丟失或重複,並且接收順序混亂。 - 原始套接字(SOCK_RAW)
什麼是協議
從應用的角度出發,協議可理解為“規則”,是資料傳輸和資料的解釋的規則。
假設,A、B雙方欲傳輸檔案。規定:
* 第一次,傳輸檔名,接收方接收到檔名,應答OK給傳輸方;
* 第二次,傳送檔案的尺寸,接收方接收到該資料再次應答一個OK;
* 第三次,傳輸檔案內容。同樣,接收方接收資料完成後應答OK表示檔案內容接收成功。
由此,無論A、B之間傳遞何種檔案,都是通過三次資料傳輸來完成。A、B之間形成了一個最簡單的資料傳輸規則。雙方都按此規則傳送、接收資料。A、B之間達成的這個相互遵守的規則即為協議。
這種僅在A、B之間被遵守的協議稱之為原始協議。當此協議被更多的人採用,不斷的增加、改進、維護、完善。最終形成一個穩定的、完整的檔案傳輸協議,被廣泛應用於各種檔案傳輸過程中。該協議就成為一個標準協議。最早的ftp協議就是由此衍生而來。
TCP協議注重資料的傳輸。http協議著重於資料的解釋。
典型協議
傳輸層 常見協議有TCP/UDP協議。
應用層 常見的協議有HTTP協議,FTP協議。
網路層 常見協議有IP協議、ICMP協議、IGMP協議。
網路介面層 常見協議有ARP協議、RARP協議。
TCP傳輸控制協議 (Transmission Control Protocol)是一種面向連線的、可靠的、基於位元組流的傳輸層通訊協議。
UDP使用者資料報協議 (User Datagram Protocol)是OSI參考模型中一種無連線的傳輸層協議,提供面向事務的簡單不可靠資訊傳送服務。
HTTP超文字傳輸協議 (Hyper Text Transfer Protocol)是網際網路上應用最為廣泛的一種網路協議。
FTP檔案傳輸協議(File Transfer Protocol)
IP協議是因特網互聯協議(Internet Protocol)
ICMP協議是Internet控制報文協議(Internet Control Message Protocol)它是TCP/IP協議族的一個子協議,用於在IP主機、路由器之間傳遞控制訊息。
IGMP協議是 Internet 組管理協議(Internet Group Management Protocol),是因特網協議家族中的一個組播協議。該協議執行在主機和組播路由器之間。
ARP協議是正向地址解析協議(Address Resolution Protocol),通過已知的IP,尋找對應主機的MAC地址。
RARP是反向地址轉換協議,通過MAC地址確定IP地址。
網路應用程式設計模式
- C/S模式
傳統的網路應用設計模式,客戶機(client)/伺服器(server)模式。需要在通訊兩端各自部署客戶機和伺服器來完成資料通訊。 B/S模式
瀏覽器()/伺服器(server)模式。只需在一端部署伺服器,而另外一端使用每臺PC都預設配置的瀏覽器即可完成資料的傳輸。優缺點
對於C/S模式來說,其優點明顯。客戶端位於目標主機上可以保證效能,將資料快取至客戶端本地,從而提高資料傳輸效率。且,一般來說客戶端和伺服器程式由一個開發團隊創作,所以他們之間所採用的協議相對靈活。可以在標準協議的基礎上根據需求裁剪及定製。例如,騰訊公司所採用的通訊協議,即為ftp協議的修改剪裁版。
因此,傳統的網路應用程式及較大型的網路應用程式都首選C/S模式進行開發。如,知名的網路遊戲魔獸世界。3D畫面,資料量龐大,使用C/S模式可以提前在本地進行大量資料的快取處理,從而提高觀感。
C/S模式的缺點也較突出。由於客戶端和伺服器都需要有一個開發團隊來完成開發。工作量將成倍提升,開發週期較長。另外,從使用者角度出發,需要將客戶端安插至使用者主機上,對使用者主機的安全性構成威脅。這也是很多使用者不願使用C/S模式應用程式的重要原因。B/S模式相比C/S模式而言,由於它沒有獨立的客戶端,使用標準瀏覽器作為客戶端,其工作開發量較小。只需開發伺服器端即可。另外由於其採用瀏覽器顯示資料,因此移植性非常好,不受平臺限制。如早期的偷菜遊戲,在各個平臺上都可以完美執行。
B/S模式的缺點也較明顯。由於使用第三方瀏覽器,因此網路應用支援受限。另外,沒有客戶端放到對方主機上,快取資料不盡如人意,從而傳輸資料量受到限制。應用的觀感大打折扣。第三,必須與瀏覽器一樣,採用標準http協議進行通訊,協議選擇不靈活。
因此在開發過程中,模式的選擇由上述各自的特點決定。根據實際需求選擇應用程式設計模式。
OSI七層模型

1. 物理層:主要定義物理裝置標準,如網線的介面型別、光纖的介面型別、各種傳輸介質的傳輸速率等。它的主要作用是傳輸位元流(就是由1、0轉化為電流強弱來進行傳輸,到達目的地後再轉化為1、0,也就是我們常說的數模轉換與模數轉換)。這一層的資料叫做位元。
2. 資料鏈路層:定義瞭如何讓格式化資料以幀為單位進行傳輸,以及如何讓控制對物理介質的訪問。這一層通常還提供錯誤檢測和糾正,以確保資料的可靠傳輸。如:串列埠通訊中使用到的115200、8、N、1
3. 網路層:在位於不同地理位置的網路中的兩個主機系統之間提供連線和路徑選擇。Internet的發展使得從世界各站點訪問資訊的使用者數大大增加,而網路層正是管理這種連線的層。
4. 傳輸層:定義了一些傳輸資料的協議和埠號(WWW埠80等),如:TCP(傳輸控制協議,傳輸效率低,可靠性強,用於傳輸可靠性要求高,資料量大的資料),UDP(使用者資料報協議,與TCP特性恰恰相反,用於傳輸可靠性要求不高,資料量小的資料,如QQ聊天資料就是通過這種方式傳輸的)。 主要是將從下層接收的資料進行分段和傳輸,到達目的地址後再進行重組。常常把這一層資料叫做段。
5. 會話層:通過傳輸層(埠號:傳輸埠與接收埠)建立資料傳輸的通路。主要在你的系統之間發起會話或者接受會話請求(裝置之間需要互相認識可以是IP也可以是MAC或者是主機名)。
6. 表示層:可確保一個系統的應用層所傳送的資訊可以被另一個系統的應用層讀取。例如,PC程式與另一臺計算機進行通訊,其中一臺計算機使用擴充套件二一十進位制交換碼(EBCDIC),而另一臺則使用美國資訊交換標準碼(ASCII)來表示相同的字元。如有必要,表示層會通過使用一種通格式來實現多種資料格式之間的轉換。
7. 應用層:是最靠近使用者的OSI層。這一層為使用者的應用程式(例如電子郵件、檔案傳輸和終端模擬)提供網路服務。
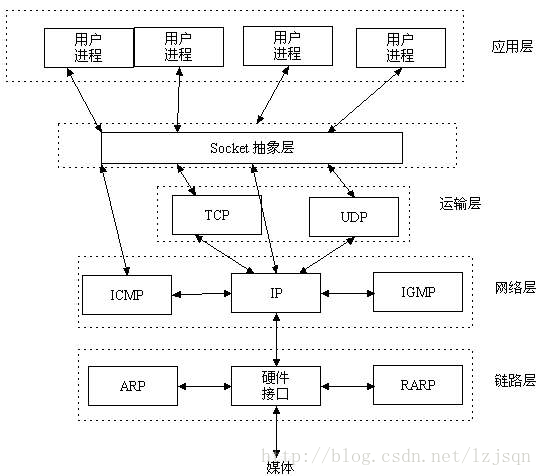
TCP/IP四層模型
TCP/IP網路協議棧分為應用層(Application)、傳輸層(Transport)、網路層(Network)和鏈路層(Link)四層。如下圖所示:

一般在應用開發過程中,討論最多的是TCP/IP模型
通訊過程
兩臺計算機通過TCP/IP協議通訊的過程如下所示:

上圖對應兩臺計算機在同一網段中的情況,如果兩臺計算機在不同的網段中,那麼資料從一臺計算機到另一臺計算機傳輸過程中要經過一個或多個路由器,如下圖所示:

鏈路層有乙太網、令牌環網等標準,鏈路層負責網絡卡裝置的驅動、幀同步(即從網線上檢測到什麼訊號算作新幀的開始)、衝突檢測(如果檢測到衝突就自動重發)、資料差錯校驗等工作。交換機是工作在鏈路層的網路裝置,可以在不同的鏈路層網路之間轉發資料幀(比如十兆乙太網和百兆乙太網之間、乙太網和令牌環網之間),由於不同鏈路層的幀格式不同,交換機要將進來的資料包拆掉鏈路層首部重新封裝之後再轉發。
網路層的IP協議是構成Internet的基礎。Internet上的主機通過IP地址來標識,Inter-net上有大量路由器負責根據IP地址選擇合適的路徑轉發資料包,資料包從Internet上的源主機到目的主機往往要經過十多個路由器。路由器是工作在第三層的網路裝置,同時兼有交換機的功能,可以在不同的鏈路層介面之間轉發資料包,因此路由器需要將進來的資料包拆掉網路層和鏈路層兩層首部並重新封裝。IP協議不保證傳輸的可靠性,資料包在傳輸過程中可能丟失,可靠性可以在上層協議或應用程式中提供支援。
網路層負責點到點(ptop,point-to-point)的傳輸(這裡的“點”指主機或路由器),而傳輸層負責端到端(etoe,end-to-end)的傳輸(這裡的“端”指源主機和目的主機)。傳輸層可選擇TCP或UDP協議。
TCP是一種面向連線的、可靠的協議,有點像打電話,雙方拿起電話互通身份之後就建立了連線,然後說話就行了,這邊說的話那邊保證聽得到,並且是按說話的順序聽到的,說完話掛機斷開連線。也就是說TCP傳輸的雙方需要首先建立連線,之後由TCP協議保證資料收發的可靠性,丟失的資料包自動重發,上層應用程式收到的總是可靠的資料流,通訊之後關閉連線。
UDP是無連線的傳輸協議,不保證可靠性,有點像寄信,信寫好放到郵筒裡,既不能保證信件在郵遞過程中不會丟失,也不能保證信件寄送順序。使用UDP協議的應用程式需要自己完成丟包重發、訊息排序等工作。
目的主機收到資料包後,如何經過各層協議棧最後到達應用程式呢?其過程如下圖所示:

乙太網驅動程式首先根據乙太網首部中的“上層協議”欄位確定該資料幀的有效載荷(payload,指除去協議首部之外實際傳輸的資料)是IP、ARP還是RARP協議的資料報,然後交給相應的協議處理。假如是IP資料報,IP協議再根據IP首部中的“上層協議”欄位確定該資料報的有效載荷是TCP、UDP、ICMP還是IGMP,然後交給相應的協議處理。假如是TCP段或UDP段,TCP或UDP協議再根據TCP首部或UDP首部的“埠號”欄位確定應該將應用層資料交給哪個使用者程序。IP地址是標識網路中不同主機的地址,而埠號就是同一臺主機上標識不同程序的地址,IP地址和埠號合起來標識網路中唯一的程序。
雖然IP、ARP和RARP資料報都需要乙太網驅動程式來封裝成幀,但是從功能上劃分,ARP和RARP屬於鏈路層,IP屬於網路層。雖然ICMP、IGMP、TCP、UDP的資料都需要IP協議來封裝成資料報,但是從功能上劃分,ICMP、IGMP與IP同屬於網路層,TCP和UDP屬於傳輸層。