google object detection API 實現教程
阿新 • • 發佈:2019-02-19
一,環境(配置參照上一篇教程):
ubuntu14.04
tensorflow_gpu-1.4.0
二,安裝相應的庫
sudo apt-get install protobuf-compiler python-pil python-lxml python-tk
sudo pip install jupyter
sudo pip install matplotlib三,下載google object detection api原始碼
四,編譯proto檔案為python檔案
之前裝的protoc軟體在這裡有問題,這時我們手動去網上下載
然後解壓到tensorflow/models/research/ 目錄wget https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip 下載比較慢也可以這裡下載: https://www.witsrc.com/download
bin/protoc object_detection/protos/*.proto --python_out=. #進行編譯五,新增slim環境變數
# From tensorflow/models/research/
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim六,最後到tensorflow/models/research/object_detection目錄
執行如下程式碼(先去網上下載ssd_mobilenet_v_coco_11_0模型解壓提取其中的frozen_inference_graph.pb到tensorflow/models/research/object_detection目錄)
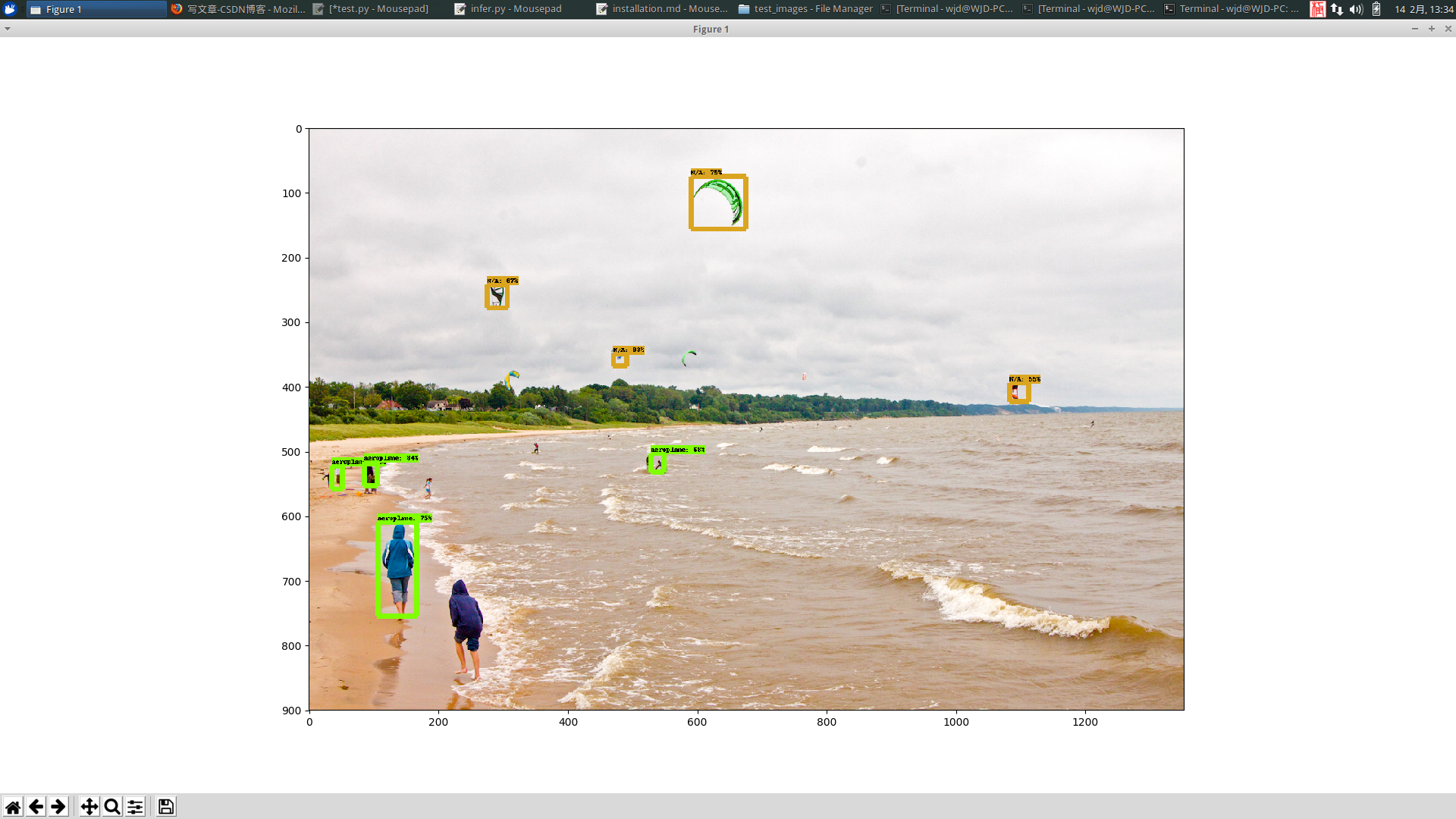
import sys sys.path.append('..') import os import time import tensorflow as tf import numpy as np from PIL import Image from matplotlib import pyplot as plt from utils import label_map_util from utils import visualization_utils as vis_util from collections import defaultdict from io import StringIO PATH_TEST_IMAGE = sys.argv[1] PATH_TO_CKPT = 'frozen_inference_graph.pb' PATH_TO_LABELS = 'data/pascal_label_map.pbtxt' NUM_CLASSES = 90 #21 IMAGE_SIZE = (12, 8) label_map = label_map_util.load_labelmap(PATH_TO_LABELS) categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True) category_index = label_map_util.create_category_index(categories) detection_graph = tf.Graph() with detection_graph.as_default(): od_graph_def = tf.GraphDef() with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid: serialized_graph = fid.read() od_graph_def.ParseFromString(serialized_graph) tf.import_graph_def(od_graph_def, name='') def load_image_into_numpy_array(image): (im_width, im_height) = image.size return np.array(image.getdata()).reshape( (im_height, im_width, 3)).astype(np.uint8) with detection_graph.as_default(): with tf.Session(graph=detection_graph) as sess: start_time = time.time() print(time.ctime()) image = Image.open(PATH_TEST_IMAGE) image_np = load_image_into_numpy_array(image) image_np_expanded = np.expand_dims(image_np, axis=0) image_tensor = detection_graph.get_tensor_by_name('image_tensor:0') boxes = detection_graph.get_tensor_by_name('detection_boxes:0') scores = detection_graph.get_tensor_by_name('detection_scores:0') classes = detection_graph.get_tensor_by_name('detection_classes:0') num_detections = detection_graph.get_tensor_by_name('num_detections:0') (boxes, scores, classes, num_detections) = sess.run( [boxes, scores, classes, num_detections], feed_dict={image_tensor: image_np_expanded}) print('{} elapsed time: {:.3f}s'.format(time.ctime(), time.time() - start_time)) vis_util.visualize_boxes_and_labels_on_image_array( image_np, np.squeeze(boxes), np.squeeze(classes).astype(np.int32), np.squeeze(scores), category_index, use_normalized_coordinates=True, line_thickness=8) plt.figure(figsize=IMAGE_SIZE) plt.imshow(image_np) plt.show()
儲存為infer.py
python3 infer.py test_images/image2.jpg執行程式