
C指標陣列和陣列指標的記憶體佈局
一、指標陣列和陣列指標的記憶體佈局
初學者總是分不出指標陣列與陣列指標的區別。其實很好理解:
指標陣列:首先它是一個數組,陣列的元素都是指標,陣列佔多少個位元組由陣列本身決定。它是“儲存指標的陣列”的簡稱。
陣列指標:首先它是一個指標,它指向一個數組。在32 位系統下永遠是佔4 個位元組,至於它指向的陣列佔多少位元組,不知道。它是“指向陣列的指標”的簡稱。下面到底哪個是陣列指標,哪個是指標陣列呢:A)
int *p1[10];
B)
int (*p2)[10];
每次上課問這個問題,總有弄不清楚的。這裡需要明白一個符號之間的優先順序問題。
“[]”的優先順序比“*”要高。p1 先與“[]”結合,構成一個數組的定義,陣列名為p1,int *修飾的是陣列的內容,即陣列的每個元素。那現在我們清楚,這是一個數組,其包含10 個指向int 型別資料的指標,即指標陣列。至於p2 就更好理解了,在這裡“()”的優先順序比“[]”高,“*”號和p2 構成一個指標的定義,指標變數名為p2,int 修飾的是陣列的內容,即陣列的每個元素。陣列在這裡並沒有名字,是個匿名陣列。那現在我們清楚p2 是一個指標,它指向一個包含10 個int 型別資料的陣列,即陣列指標。我們可以藉助下面的圖加深理解:

二、int (*)[10] p2-----也許應該這麼定義陣列指標
這裡有個有意思的話題值得探討一下:平時我們定義指標不都是在資料型別後面加上指標變數名麼?這個指標p2 的定義怎麼不是按照這個語法來定義的呢?也許我們應該這樣來定義p2:
int (*)[10] p2;
int (*)[10]是指標型別,p2 是指標變數。這樣看起來的確不錯,不過就是樣子有些彆扭。其實陣列指標的原型確實就是這樣子的,只不過為了方便與好看把指標變數p2 前移了而已。你私下完全可以這麼理解這點。雖然編譯器不這麼想。^_^
三、再論a 和&a 之間的區別
既然這樣,那問題就來了。前面我們講過a 和&a 之間的區別,現在再來看看下面的程式碼:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[5] = &a;
char (*p4)[5] = a;
return 0;
}
上面對p3 和p4 的使用,哪個正確呢?p3+1 的值會是什麼?p4+1 的值又會是什麼?毫無疑問,p3 和p4 都是陣列指標,指向的是整個陣列。&a 是整個陣列的首地址,a是陣列首元素的首地址,其值相同但意義不同。在C 語言裡,賦值符號“=”號兩邊的資料型別必須是相同的,如果不同需要顯示或隱式的型別轉換。p3 這個定義的“=”號兩邊的資料型別完全一致,而p4 這個定義的“=”號兩邊的資料型別就不一致了。左邊的型別是指向整個陣列的指標,右邊的資料型別是指向單個字元的指標。在Visual C++6.0 上給出如下警告:
warning C4047: 'initializing' :'char (*)[5]' differs in levels of indirection from 'char *'。
還好,這裡雖然給出了警告,但由於&a 和a 的值一樣,而變數作為右值時編譯器只是取變數的值,所以執行並沒有什麼問題。不過我仍然警告你別這麼用。
既然現在清楚了p3 和p4 都是指向整個陣列的,那p3+1 和p4+1 的值就很好理解了。
但是如果修改一下程式碼,會有什麼問題?p3+1 和p4+1 的值又是多少呢?
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[3] = &a;
char (*p4)[3] = a;
return 0;
}
甚至還可以把程式碼再修改:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[10] = &a;
char (*p4)[10] = a;
return 0;
}
這個時候又會有什麼樣的問題?p3+1 和p4+1 的值又是多少?
上述幾個問題,希望讀者能仔細考慮考慮。
四、地址的強制轉換
先看下面這個例子:
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
假設p 的值為0x100000。如下表表示式的值分別為多少?
p + 0x1 = 0x___ ?
(unsigned long)p + 0x1 = 0x___?
(unsigned int*)p + 0x1 = 0x___?
我相信會有很多人一開始沒看明白這個問題是什麼意思。其實我們再仔細看看,這個知識點似曾相識。一個指標變數與一個整數相加減,到底該怎麼解析呢?
還記得前面我們的表示式“a+1”與“&a+1”之間的區別嗎?其實這裡也一樣。指標變數與一個整數相加減並不是用指標變數裡的地址直接加減這個整數。這個整數的單位不是byte 而是元素的個數。所以:p + 0x1 的值為0x100000+sizof(Test)*0x1。至於此結構體的大小為20byte,前面的章節已經詳細講解過。所以p +0x1 的值為:0x100014。
(unsigned long)p + 0x1 的值呢?這裡涉及到強制轉換,將指標變數p 儲存的值強制轉換成無符號的長整型數。任何數值一旦被強制轉換,其型別就改變了。所以這個表示式其實就是一個無符號的長整型數加上另一個整數。所以其值為:0x100001。
(unsigned int*)p + 0x1 的值呢?這裡的p 被強制轉換成一個指向無符號整型的指標。所以其值為:0x100000+sizof(unsigned int)*0x1,等於0x100004。
上面這個問題似乎還沒啥技術含量,下面就來個有技術含量的:在x86 系統下,其值為多少?
intmain()
{
int a[4]={1,2,3,4};
int *ptr1=(int *)(&a+1);
int *ptr2=(int *)((int)a+1);
printf("%x,%x",ptr1[-1],*ptr2);
return 0;
}
這是我講課時一個學生問我的題,他在網上看到的,據說難倒了n 個人。我看題之後告訴他,這些人肯定不懂彙編,一個懂彙編的人,這種題實在是小case。下面就來分析分析這個問題:
根據上面的講解,&a+1 與a+1 的區別已經清楚。
ptr1:將&a+1 的值強制轉換成int*型別,賦值給int* 型別的變數ptr,ptr1 肯定指到陣列a 的下一個int 型別資料了。ptr1[-1]被解析成*(ptr1-1),即ptr1 往後退4 個byte。所以其值為0x4。
ptr2:按照上面的講解,(int)a+1 的值是元素a[0]的第二個位元組的地址。然後把這個地址強制轉換成int*型別的值賦給ptr2,也就是說*ptr2 的值應該為元素a[0]的第二個位元組開始的連續4 個byte 的內容。
其記憶體佈局如下圖:
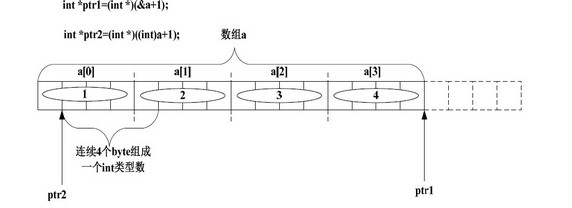
好,問題就來了,這連續4 個byte 裡到底存了什麼東西呢?也就是說元素a[0],a[1]裡面的值到底怎麼儲存的。這就涉及到系統的大小端模式了,如果懂彙編的話,這根本就不是問題。既然不知道當前系統是什麼模式,那就得想辦法測試。大小端模式與測試的方法在第一章講解union 關鍵字時已經詳細討論過了,請翻到彼處參看,這裡就不再詳述。我們可以用下面這個函式來測試當前系統的模式。
int checkSystem( )
{
union check
{
int i;
char ch;
} c;
c.i = 1;
return (c.ch ==1);
}
如果當前系統為大端模式這個函式返回0;如果為小端模式,函式返回1。也就是說如果此函式的返回值為1 的話,*ptr2 的值為0x2000000。如果此函式的返回值為0 的話,*ptr2 的值為0x100。