
caffe中forward過程總結(1)
阿新 • • 發佈:2019-02-19
轉載地址:http://blog.csdn.net/Buyi_Shizi/article/details/51504276
感謝作者總結!
caffe中最重要的兩個部分就是forward和backward的過程,farward是根據輸入資料正向預測輸入屬於哪一類;backward是根據輸出的結果求得代價函式,然後根據代價函式反向求去其相對於各層網路引數的梯度的過程。我們先對farward過程做一下總結。
caffe中有兩個過程會設計到farward,test和train,這裡我們以train訓練過程為例。
- int train() caffe.cpp Line 181:
這是train的入口函式,train函式裡的操作這裡我們掠過,我們主要進入訓練的主體函式solver->Solve()函式(Line 253)。void Solver<Dtype>::Solve()函式是訓練網路的入口函式,而我們的訓練的主體函式就是在Line 293的Step()函式。 - 訓練主體函式void Solver<Dtype>::Step():
進入這個函式之後,我們首先就要進行迭代的迴圈,以lenet網路訓練為例,由於lenet是採用stochastic的訓練方式,所以就必須進行多次迭代,當然每次迭代迴圈又會採用多個樣本(batch)進行訓練。在迴圈體內,程式就回進入forward過程了。程式如下:- for (int i = 0; i < param_.iter_size(); ++i) { // iter_size=1 indicate update parameters for every sample
-
loss += net_->ForwardBackward(); // forward and backward process
- }
- loss /= param_.iter_size();
在進入net_->ForwardBackward()函式(net.hpp Line 85)之後,程式會先進入Forward函式:Forward(&loss),然後再會進入Backward()函式。forward過程是一層一層來進行的。在Net資料結構體中有一個儲存有每層Layer指標的vector,forward過程就回根據這個vector在每層layer中進行迴圈。當前層的forward就是由當前層輸入通過卷積或是矩陣運算或者別的運算求輸出,得到的輸出作為下一層的輸入,然後繼續下一層的forward過程。forward在每層的迴圈過程如下:-
- for (int i = start; i <= end; ++i) { // forward for every layer, 11 layers total
- // LOG(ERROR) << "Forwarding " << layer_names_[i];
- Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
- loss += layer_loss;
- if (debug_info_) { ForwardDebugInfo(i); }
- }
- for (int n = 0; n < this->num_; ++n) { // this->num: batch size
- this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
- top_data + n * this->top_dim_); // base_conv_layer.cpp:259 do convlution bottom_dim_:number of pixel of input, top_dim_:number of pixel of output with many convlution kernels
- if (this->bias_term_) {
- const Dtype* bias = this->blobs_[1]->cpu_data();
- this->forward_cpu_bias(top_data + n * this->top_dim_, bias); // scale bias if request and add bias to conv result
- }
- }
以lenet為例,在該層卷積之前,輸入資料是28×28的,該層的卷積核是5x5,那麼最後卷積的輸出應該是24x24。但是當前卷積層有20個卷積核,而且我現在想只調用一次blas的矩陣函式,就能完成20個卷積核對28x28影象的全部卷積函式。caffe是這樣處理的,如下圖所示

程式先把20個不同的卷積核放在一個矩陣裡,矩陣的每一行表示每個卷積核的所有係數,即每個卷積核都是按行展開了;然後對於輸入畫素,該卷積層只有一張輸入畫素,程式會把每個卷積核的不同位置上的25個畫素拍成一列,對於5x5卷積核卷積28x28的圖片,最後輸出是24x24的尺寸,我們就要為每個卷積核構造576列資料,分別對應不同位置上的25個對應的畫素;最後的輸出就會變成20x576,其中20表示20個卷積核,576表示每個卷積核的輸出尺寸,即24x24。
每個卷積核的bias只有一個值,但是對於每個卷積核在影象上的不同位置,我們可能要對其進行scale操作,這就需要576個scale係數,最後輸出是20x576,然後和weight卷積後的結果相加就可以得出最終的結果了。
為什麼要這樣設計,我理解的是,是為了一次卷積運算就可以把20個卷積核對影象的卷積操作一次計算出來。上面只是第一層卷積層,後面卷積層的處理和這相似,但由於輸入資料的個數不一樣,矩陣構造的過程又有稍微不同。
b.pooling層void PoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top): pooling層的作用就是下采樣,這裡採用的是PoolMethid_MAX方式,即在Pooling核的區域選擇出最大的值作為當前區域的值,pooling層的運算比較簡單,這裡不再深究。
c.2級卷積層void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top): 經過下采樣之後,影象尺寸變成12x12,但是有20個12x12的影象資料,因為對應有20個卷積核,這一層又需要構造卷積矩陣,我們這裡權值相乘的矩陣的構造,如下圖所示:
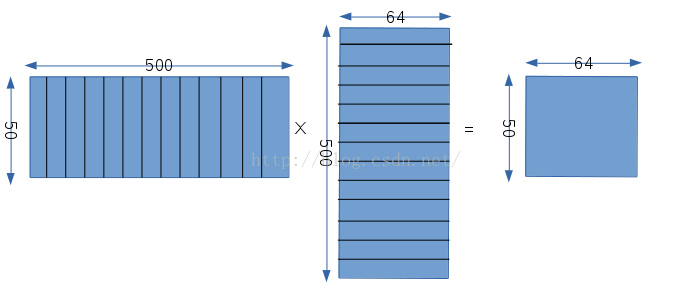
首先第一個矩陣同樣表示權值矩陣,50表示這一層有50個卷積核,500=25×20,這一層的卷積核是5x5,然後這一層的輸入有20個不同的12x12的影象,所以500就表示每個卷積核分別和20個不同的輸入的對應的位置相乘,然後再把所有的結果相加,從這我們可以看出,這一層的每一個卷積核都是和所有的資料相連線的;第二個矩陣表示輸入矩陣,同樣由於卷積核的大小是5x5,輸入尺寸是12x12,所以輸出的結果是8x8,即一個卷積核在一個數據上卷積了64次,所以對於每一幅輸入影象,我們都要構造64個對應的數,而又因為輸入是有20張影象的,所以每一次卷積都會設計25x20個數據,所以輸入矩陣有500行,64列;輸出矩陣自然就是50x64,50對應卷積核的個數,64對應每個卷積核的輸出。
d.2級pooling層void PoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
這也只是一個下采樣層,對輸入8x8的影象進行下采樣,輸出就變成4x4個,都是有50個。
以上就是caffe中forward過程的和卷積層相關的forward具體過程,在卷積層後還有InnerProduct層以及求取代價函式層,這在另一篇有總結。