
Java集合及concurrent併發包總結(轉)
集合包最常用的有Collection和Map兩個介面的實現類,Colleciton用於存放多個單物件,Map用於存放Key-Value形式的鍵值對。
Collection中最常用的又分為兩種型別的介面:List和Set,兩者最明顯的差別為List支援放入重複的元素,而Set不支援。
List最常用的實現類有:ArrayList、LinkedList、Vector及Stack;Set介面常用的實現類有:HashSet、TreeSet。
1.1 ArrayList
ArrayList基於陣列方式實現,預設構造器通過呼叫ArrayList(int)來完成建立,傳入的值為10,例項化了一個Object陣列,並將此陣列賦給了當前例項的elementData屬性,此Object陣列的大小即為傳入的initialCapacity,因此呼叫空構造器的情況下會建立一個大小為10的Object陣列。
插入物件:add(E)
基於已有元素數量加1作為名叫minCapacity的變數,比較此值和Object陣列的大小,若大於陣列值,那麼先將當前Object陣列值賦給一個數組物件,接著產生一個鑫的陣列容量值。此值的計算方法為當前陣列值*1.5+1,如得出的容量值仍然小於minCapacity,那麼就以minCapacity作為新的容量值,呼叫Arrays.copyOf來生成新的陣列物件。
還提供了add(int,E)這樣的方法將元素直接插入指定的int位置上,將目前index及其後的資料都往後挪一位,然後才能將指定的index位置的賦值為傳入的物件,這種方式要多付出一次複製陣列的代價。還提供了addAll
刪除物件:remove(E)
這裡呼叫了faseRemove方法將index後的物件往前複製一位,並將陣列中的最後一個元素的值設定為null,即釋放了對此物件的引用。 還提供了remove(int)方法來刪除指定位置的物件,remove(int)的實現比remove(E)多了一個數組範圍的檢測,但少了物件位置的查詢,因此效能會更好。
獲取單個物件:get(int)
遍歷物件:iterator()
判斷物件是否存在:contains(E)
總結:
1,ArrayList基於陣列方式實現,無容量的限制;
2,ArrayList在執行插入元素時可能要擴容,在刪除元素時並不會減小陣列的容量(如希望相應的縮小陣列容量,可以呼叫ArrayList的trimToSize()),在查詢元素時要遍歷陣列,對於非null的元素採取equals的方式尋找;
3,ArrayList是非執行緒安全的。
1.2 LinkedList
LinkedList基於雙向連結串列機制,所謂雙向連結串列機制,就是集合中的每個元素都知道其前一個元素及其後一個元素的位置。在LinkedList中,以一個內部的Entry類來代表集合中的元素,元素的值賦給element屬性,Entry中的next屬性指向元素的後一個元素,Entry中的previous屬性指向元素的前一個元素,基於這樣的機制可以快速實現集合中元素的移動。
總結:
1,LinkedList基於雙向連結串列機制實現;
2,LinkedList在插入元素時,須建立一個新的Entry物件,並切換相應元素的前後元素的引用;在查詢元素時,須遍歷連結串列;在刪除元素時,要遍歷連結串列,找到要刪除的元素,然後從連結串列上將此元素刪除即可,此時原有的前後元素改變引用連在一起;
3,LinkedList是非執行緒安全的。
1.3 Vector
其add、remove、get(int)方法都加了synchronized關鍵字,預設建立一個大小為10的Object陣列,並將capacityIncrement設定為0。容量擴充策略:如果capacityIncrement大於0,則將Object陣列的大小擴大為現有size加上capacityIncrement的值;如果capacity等於或小於0,則將Object陣列的大小擴大為現有size的兩倍,這種容量的控制策略比ArrayList更為可控。
Vector是基於Synchronized實現的執行緒安全的ArrayList,但在插入元素時容量擴充的機制和ArrayList稍有不同,並可通過傳入capacityIncrement來控制容量的擴充。
1.4 Stack
Stack繼承於Vector,在其基礎上實現了Stack所要求的後進先出(LIFO)的彈出與壓入操作,其提供了push、pop、peek三個主要的方法:
push操作通過呼叫Vector中的addElement來完成;
pop操作通過呼叫peek來獲取元素,並同時刪除陣列中的最後一個元素;
peek操作通過獲取當前Object陣列的大小,並獲取陣列上的最後一個元素。
1.5 HashSet
預設構造建立一個HashMap物件
add(E):呼叫HashMap的put方法來完成此操作,將需要增加的元素作為Map中的key,value則傳入一個之前已建立的Object物件。
remove(E):呼叫HashMap的remove(E)方法完成此操作。
contains(E):HashMap的containsKey
iterator():呼叫HashMap的keySet的iterator方法。
HashSet不支援通過get(int)獲取指定位置的元素,只能自行通過iterator方法來獲取。
總結:
1,HashSet基於HashMap實現,無容量限制;
2,HashSet是非執行緒安全的。
1.6 TreeSet
TreeSet和HashSet的主要不同在於TreeSet對於排序的支援,TreeSet基於TreeMap實現。
1.7 HashMap
HashMap空構造,將loadFactor設為預設的0.75,threshold設定為12,並建立一個大小為16的Entry物件陣列。
基於陣列+連結串列的結合體(連結串列雜湊)實現,將key-value看成一個整體,存放於Entity[]陣列,put的時候根據key hash後的hashcode和陣列length-1按位與的結果值判斷放在陣列的哪個位置,如果該陣列位置上若已經存放其他元素,則在這個位置上的元素以連結串列的形式存放。如果該位置上沒有元素則直接存放。
當系統決定儲存HashMap中的key-value對時,完全沒有考慮Entry中的value,僅僅只是根據key來計算並決定每個Entry的儲存位置。我們完全可以把Map集合中的value當成key的附屬,當系統決定了key的儲存位置之後,value隨之儲存在那裡即可。get取值也是根據key的hashCode確定在陣列的位置,在根據key的equals確定在連結串列處的位置。
1 while (capacity < initialCapacity) 2 capacity <<= 1;
以上程式碼保證了初始化時HashMap的容量總是2的n次方,即底層陣列的長度總是為2的n次方。它通過h & (table.length -1) 來得到該物件的儲存位,若length為奇數值,則與運算產生相同結果,便會形成連結串列,儘可能的少出現連結串列才能提升hashMap的效率,所以這是hashMap速度上的優化。
擴容resize():
當HashMap中的元素越來越多的時候,hash衝突的機率也就越來越高,因為陣列的長度是固定的。所以為了提高查詢的效率,就要對HashMap的陣列進行擴容,而在HashMap陣列擴容之後,最消耗效能的點就出現了:原陣列中的資料必須重新計算其在新陣列中的位置,並放進去,這就是resize。那麼HashMap什麼時候進行擴容呢?當HashMap中的元素個數超過陣列大小*loadFactor時,就會進行陣列擴容,loadFactor的預設值為0.75,這是一個折中的取值。
負載因子衡量的是一個散列表的空間的使用程度,負載因子越大表示散列表的裝填程度越高,反之愈小。負載因子越大,對空間的利用更充分,然而後果是查詢效率的降低;如果負載因子太小,那麼散列表的資料將過於稀疏,對空間造成嚴重浪費。
HashMap的實現中,通過threshold欄位來判斷HashMap的最大容量。threshold就是在此loadFactor和capacity對應下允許的最大元素數目,超過這個數目就重新resize,以降低實際的負載因子。預設的的負載因子0.75是對空間和時間效率的一個平衡選擇。
initialCapacity*2,成倍擴大容量,HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的負載因子建立一個 HashMap。不設定引數,則初始容量值為16,預設的負載因子為0.75,不宜過大也不宜過小,過大影響效率,過小浪費空間。擴容後需要重新計算每個元素在陣列中的位置,是一個非常消耗效能的操作,所以如果我們已經預知HashMap中元素的個數,那麼預設元素的個數能夠有效的提高HashMap的效能。
HashTable資料結構的原理大致一樣,區別在於put、get時加了同步關鍵字,而且HashTable不可存放null值。
在高併發時可以使用ConcurrentHashMap,其內部使用鎖分段技術,維持這鎖Segment的陣列,在陣列中又存放著Entity[]陣列,內部hash演算法將資料較均勻分佈在不同鎖中。
總結:
1,HashMap採用陣列方式儲存key、value構成的Entry物件,無容量限制;
2,HashMap基於key hash尋找Entry物件存放到陣列的位置,對於hash衝突採用連結串列的方式解決;
3,HashMap在插入元素時可能會擴大陣列的容量,在擴大容量時須要重新計算hash,並複製物件到新的陣列中;
4,HashMap是非執行緒安全的。
1.8 TreeMap
TreeMap基於紅黑樹的實現,因此它要求一定要有key比較的方法,要麼傳入Comparator實現,要麼key物件實現Comparable藉口。在put操作時,基於紅黑樹的方式遍歷,基於comparator來比較key應放在樹的左邊還是右邊,如找到相等的key,則直接替換掉value。
2.併發包
jdk5.0一很重要的特性就是增加了併發包java.util.concurrent.*,在說具體的實現類或介面之前,這裡先簡要說下Java記憶體模型、volatile變數及AbstractQueuedSynchronizer(以下簡稱AQS同步器),這些都是併發包眾多實現的基礎。
Java記憶體模型
描述了執行緒記憶體與主存見的通訊關係。定義了執行緒內的記憶體改變將怎樣傳遞到其他執行緒的規則,同樣也定義了執行緒記憶體與主存進行同步的細節,也描述了哪些操作屬於原子操作及操作間的順序。
程式碼順序規則:
一個執行緒內的每個動作happens-before同一個執行緒內在程式碼順序上在其後的所有動作.
volatile變數規則:
對一個volatile變數的讀,總是能看到(任意執行緒)對這個volatile變數最後的寫入.
傳遞性:
如果A happens-before B, B happens-before C, 那麼A happens-before C.
volatile
當我們宣告共享變數為volatile後,對這個變數的讀/寫將會很特別。理解volatile特性的一個好方法是:把對volatile變數的單個讀/寫,看成是使用同一個監視器鎖對這些單個讀/寫操作做了同步。
監視器鎖的happens-before規則保證釋放監視器和獲取監視器的兩個執行緒之間的記憶體可見性,這意味著對一個volatile變數的讀,總是能看到(任意執行緒)對這個volatile變數最後的寫入。
簡而言之,volatile變數自身具有下列特性:
可見性。對一個volatile變數的讀,總是能看到(任意執行緒)對這個volatile變數最後的寫入。
原子性:對任意單個volatile變數的讀/寫具有原子性,但類似於volatile++這種複合操作不具有原子性。
volatile寫的記憶體語義如下:
當寫一個volatile變數時,JMM會把該執行緒對應的本地記憶體中的共享變數重新整理到主記憶體。
volatile讀的記憶體語義如下:
當讀一個volatile變數時,JMM會把該執行緒對應的本地記憶體置為無效。執行緒接下來將從主記憶體中讀取共享變數。
下面對volatile寫和volatile讀的記憶體語義做個總結:
執行緒A寫一個volatile變數,實質上是執行緒A向接下來將要讀這個volatile變數的某個執行緒發出了(其對共享變數所在修改的)訊息。
執行緒B讀一個volatile變數,實質上是執行緒B接收了之前某個執行緒發出的(在寫這個volatile變數之前對共享變數所做修改的)訊息。
執行緒A寫一個volatile變數,隨後執行緒B讀這個volatile變數,這個過程實質上是執行緒A通過主記憶體向執行緒B傳送訊息。
鎖釋放-獲取與volatile的讀寫具有相同的記憶體語義,
鎖釋放的記憶體語義如下:
當執行緒釋放鎖時,JMM會把該執行緒對應的本地記憶體中的共享變數重新整理到主記憶體。
鎖獲取的記憶體語義如下:
當執行緒獲取鎖時,JMM會把該執行緒對應的本地記憶體置為無效,從而使得被監視器保護的臨界區程式碼必須要從主記憶體中讀取共享變數。
下面對鎖釋放和鎖獲取的記憶體語義做個總結:
執行緒A釋放一個鎖,實質上是執行緒A向接下來將要獲取這個鎖的某個執行緒發出了(執行緒A對共享變數所做修改的)訊息。
執行緒B獲取一個鎖,實質上是執行緒B接收了之前某個執行緒發出的(在釋放這個鎖之前對共享變數所做修改的)訊息。
執行緒A釋放鎖,隨後執行緒B獲取這個鎖,這個過程實質上是執行緒A通過主記憶體向執行緒B傳送訊息。
示例:

1 class VolatileExample { 2 int x = 0; 3 volatile int b = 0; 4 5 private void write() { 6 x = 5; 7 b = 1; 8 } 9 10 private void read() { 11 int dummy = b; 12 while (x != 5) { 13 } 14 } 15 16 public static void main(String[] args) throws Exception { 17 final VolatileExample example = new VolatileExample(); 18 Thread thread1 = new Thread(new Runnable() { 19 public void run() { 20 example.write(); 21 } 22 }); 23 Thread thread2 = new Thread(new Runnable() { 24 public void run() { 25 example.read(); 26 } 27 }); 28 thread1.start(); 29 thread2.start(); 30 thread1.join(); 31 thread2.join(); 32 } 33 }
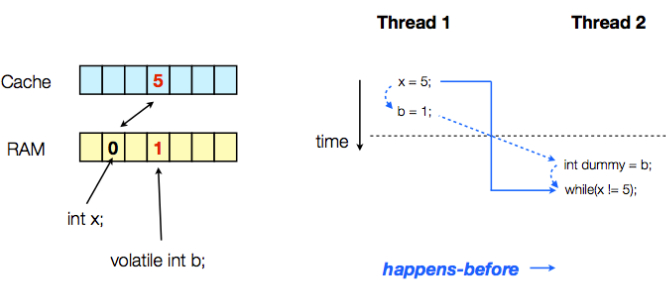
若thread1先於thread2執行,則程式執行流程分析如上圖所示,thread2讀的結果是dummy=1,x=5所以不會進入死迴圈。
但並不能保證兩執行緒的執行順序,若thread2先於thread1執行,則程式在兩執行緒join中斷之前的結果為:因為b變數的型別是volatile,故thread1寫之後,thread2即可讀到b變數的值發生變化,
而x是普通變數,故最後情況是dummy=1,但thread2的讀操作因為x=0而進入死迴圈中。
在JSR-133之前的舊Java記憶體模型中,雖然不允許volatile變數之間重排序,但舊的Java記憶體模型仍然會允許volatile變數與普通變數之間重排序。JSR-133則增強了volatile的記憶體語義:嚴格限制編譯器(在編譯期)和處理器(在執行期)對volatile變數與普通變數的重排序,確保volatile的寫-讀和監視器的釋放-獲取一樣,具有相同的記憶體語義。限制重排序是通過記憶體屏障實現的,具體可見JMM的描述。
由於volatile僅僅保證對單個volatile變數的讀/寫具有原子性,而監視器鎖的互斥執行的特性可以確保對整個臨界區程式碼的執行具有原子性。在功能上,監視器鎖比volatile更強大;在可伸縮性和執行效能上,volatile更有優勢。如果讀者想在程式中用volatile代替監視器鎖,請一定謹慎。
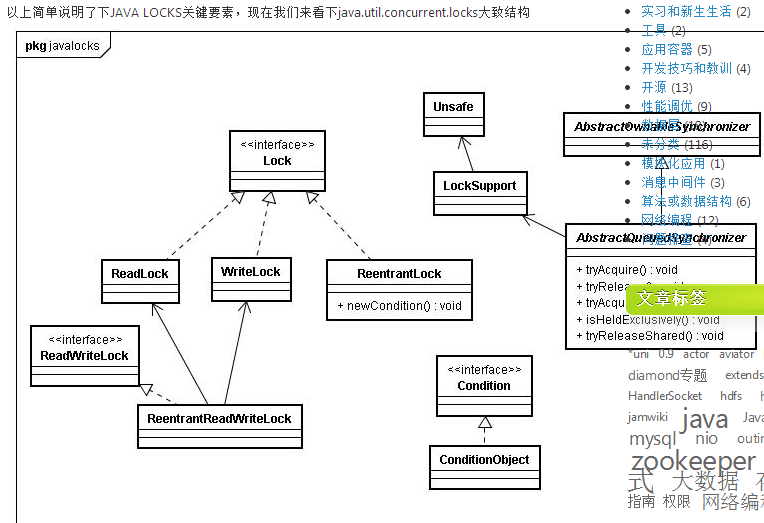
AbstractQueuedSynchronizer (AQS)
AQS使用一個整型的volatile變數(命名為state)來維護同步狀態,這是接下來實現大部分同步需求的基礎。提供了一個基於FIFO佇列,可以用於構建鎖或者其他相關同步裝置的基礎框架。使用的方法是繼承,子類通過繼承同步器並需要實現它的方法來管理其狀態,管理的方式就是通過類似acquire和release的方式來操縱狀態。然而多執行緒環境中對狀態的操縱必須確保原子性,因此子類對於狀態的把握,需要使用這個同步器提供的以下三個方法對狀態進行操作:
java.util.concurrent.locks.AbstractQueuedSynchronizer.getState()
java.util.concurrent.locks.AbstractQueuedSynchronizer.setState(int)
java.util.concurrent.locks.AbstractQueuedSynchronizer.compareAndSetState(int, int)
子類推薦被定義為自定義同步裝置的內部類,同步器自身沒有實現任何同步介面,它僅僅是定義了若干acquire之類的方法來供使用。該同步器即可以作為排他模式也可以作為共享模式,當它被定義為一個排他模式時,其他執行緒對其的獲取就被阻止,而共享模式對於多個執行緒獲取都可以成功。
同步器是實現鎖的關鍵,利用同步器將鎖的語義實現,然後在鎖的實現中聚合同步器。可以這樣理解:鎖的API是面向使用者的,它定義了與鎖互動的公共行為,而每個鎖需要完成特定的操作也是透過這些行為來完成的(比如:可以允許兩個執行緒進行加鎖,排除兩個以上的執行緒),但是實現是依託給同步器來完成;同步器面向的是執行緒訪問和資源控制,它定義了執行緒對資源是否能夠獲取以及執行緒的排隊等操作。鎖和同步器很好的隔離了二者所需要關注的領域,嚴格意義上講,同步器可以適用於除了鎖以外的其他同步設施上(包括鎖)。
同步器的開始提到了其實現依賴於一個FIFO佇列,那麼佇列中的元素Node就是儲存著執行緒引用和執行緒狀態的容器,每個執行緒對同步器的訪問,都可以看做是佇列中的一個節點。
對於一個獨佔鎖的獲取和釋放有如下偽碼可以表示:
獲取一個排他鎖
1 while(獲取鎖) { 2 if (獲取到) { 3 退出while迴圈 4 } else { 5 if(當前執行緒沒有入佇列) { 6 那麼入佇列 7 } 8 阻塞當前執行緒 9 } 10 }
釋放一個排他鎖
1 if (釋放成功) { 2 刪除頭結點 3 啟用原頭結點的後繼節點 4 }
示例:
下面通過一個排它鎖的例子來深入理解一下同步器的工作原理,而只有掌握同步器的工作原理才能更加深入瞭解其他的併發元件。
排他鎖的實現,一次只能一個執行緒獲取到鎖:
1 public class Mutex implements Lock, java.io.Serializable { 2 // 內部類,自定義同步器 3 private static class Sync extends AbstractQueuedSynchronizer { 4 // 是否處於佔用狀態 5 protected boolean isHeldExclusively() { 6 return getState() == 1; 7 } 8 // 當狀態為0的時候獲取鎖 9 public boolean tryAcquire(int acquires) { 10 assert acquires == 1; // Otherwise unused 11 if (compareAndSetState(0, 1)) { 12 setExclusiveOwnerThread(Thread.currentThread()); 13 return true; 14 } 15 return false; 16 } 17 // 釋放鎖,將狀態設定為0 18 protected boolean tryRelease(int releases) { 19 assert releases == 1; // Otherwise unused 20 if (getState() == 0) throw new IllegalMonitorStateException(); 21 setExclusiveOwnerThread(null); 22 setState(0); 23 return true; 24 } 25 // 返回一個Condition,每個condition都包含了一個condition佇列 26 Condition newCondition() { return new ConditionObject(); } 27 } 28 // 僅需要將操作代理到Sync上即可 29 private final Sync sync = new Sync(); 30 public void lock() { sync.acquire(1); } 31 public boolean tryLock() { return sync.tryAcquire(1); } 32 public void unlock() { sync.release(1); } 33 public Condition newCondition() { return sync.newCondition(); } 34 public boolean isLocked() { return sync.isHeldExclusively(); } 35 public boolean hasQueuedThreads() { return sync.hasQueuedThreads(); } 36 public void lockInterruptibly() throws InterruptedException { 37 sync.acquireInterruptibly(1); 38 } 39 public boolean tryLock(long timeout, TimeUnit unit) 40 throws InterruptedException { 41 return sync.tryAcquireNanos(1, unit.toNanos(timeout)); 42 } 43 }
可以看到Mutex將Lock介面均代理給了同步器的實現。使用方將Mutex構造出來後,呼叫lock獲取鎖,呼叫unlock將鎖釋放。
獲取鎖,acquire(int arg)的主要邏輯包括:
1. 嘗試獲取(呼叫tryAcquire更改狀態,需要保證原子性);
在tryAcquire方法中適用了同步器提供的對state操作的方法,利用compareAndSet保證只有一個執行緒能夠對狀態進行成功修改,而沒有成功修改的執行緒將進入sync佇列排隊。
2. 如果獲取不到,將當前執行緒構造成節點Node並加入sync佇列;
進入佇列的每個執行緒都是一個節點Node,從而形成了一個雙向佇列,類似CLH佇列,這樣做的目的是執行緒間的通訊會被限制在較小規模(也就是兩個節點左右)。
3. 再次嘗試獲取,如果沒有獲取到那麼將當前執行緒從執行緒排程器上摘下,進入等待狀態。
釋放鎖,release(int arg)的主要邏輯包括:
1. 嘗試釋放狀態;
tryRelease能夠保證原子化的將狀態設定回去,當然需要使用compareAndSet來保證。如果釋放狀態成功之後,就會進入後繼節點的喚醒過程。
2. 喚醒當前節點的後繼節點所包含的執行緒。
通過LockSupport的unpark方法將休眠中的執行緒喚醒,讓其繼續acquire狀態。
回顧整個資源的獲取和釋放過程:
在獲取時,維護了一個sync佇列,每個節點都是一個執行緒在進行自旋,而依據就是自己是否是首節點的後繼並且能夠獲取資源;
在釋放時,僅僅需要將資源還回去,然後通知一下後繼節點並將其喚醒。
這裡需要注意,佇列的維護(首節點的更換)是依靠消費者(獲取時)來完成的,也就是說在滿足了自旋退出的條件時的一刻,這個節點就會被設定成為首節點。
佇列裡的節點執行緒的禁用和喚醒是通過LockSupport的park()及unpark(),呼叫的unsafe、底層也是native的實現。
共享模式和以上的獨佔模式有所區別,分別呼叫acquireShared(int arg)和releaseShared(int arg)獲取共享模式的狀態。
以檔案的檢視為例,如果一個程式在對其進行讀取操作,那麼這一時刻,對這個檔案的寫操作就被阻塞,相反,這一時刻另一個程式對其進行同樣的讀操作是可以進行的。如果一個程式在對其進行寫操作,
那麼所有的讀與寫操作在這一時刻就被阻塞,直到這個程式完成寫操作。
以讀寫場景為例,描述共享和獨佔的訪問模式,如下圖所示:
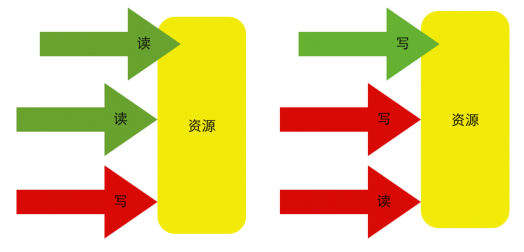
上圖中,紅色代表被阻塞,綠色代表可以通過。
在上述對同步器AbstractQueuedSynchronizer進行了實現層面的分析之後,我們通過一個例子來加深對同步器的理解:
設計一個同步工具,該工具在同一時刻,只能有兩個執行緒能夠並行訪問,超過限制的其他執行緒進入阻塞狀態。
對於這個需求,可以利用同步器完成一個這樣的設定,定義一個初始狀態,為2,一個執行緒進行獲取那麼減1,一個執行緒釋放那麼加1,狀態正確的範圍在[0,1,2]三個之間,當在0時,代表再有新的執行緒對資源進行獲取時只能進入阻塞狀態(注意在任何時候進行狀態變更的時候均需要以CAS作為原子性保障)。由於資源的數量多於1個,同時可以有兩個執行緒佔有資源,因此需要實現tryAcquireShared和tryReleaseShared方法。
1 public class TwinsLock implements Lock { 2 private final Sync sync = new Sync(2); 3 4 private static final class Sync extends AbstractQueuedSynchronizer { 5 private static final long serialVersionUID = -7889272986162341211L; 6 7 Sync(int count) { 8 if (count <= 0) { 9 throw new IllegalArgumentException("count must large than zero."); 10 } 11 setState(count); 12 } 13 14 public int tryAcquireShared(int reduceCount) { 15 for (;;) { 16 int current = getState(); 17 int newCount = current - reduceCount; 18 if (newCount < 0 || compareAndSetState(current, newCount)) { 19 return newCount; 20 } 21 } 22 } 23 24 public boolean tryReleaseShared(int returnCount) { 25 for (;;) { 26 int current = getState(); 27 int newCount = current + returnCount; 28 if (compareAndSetState(current, newCount)) { 29 return true; 30 } 31 } 32 } 33 } 34 35 public void lock() { 36 sync.acquireShared(1); 37 } 38 39 public void lockInterruptibly() throws InterruptedException { 40 sync.acquireSharedInterruptibly(1); 41 } 42 43 public boolean tryLock() { 44 return sync.tryAcquireShared(1) >= 0; 45 } 46 47 public boolean tryLock(long time, TimeUnit unit) throws InterruptedException { 48 return sync.tryAcquireSharedNanos(1, unit.toNanos(time)); 49 } 50 51 public void unlock() { 52 sync.releaseShared(1); 53 } 54 55 public Condition newCondition() { 56 return null; 57 } 58 }
這裡我們編寫一個測試來驗證TwinsLock是否能夠正常工作並達到預期。
1 public class TwinsLockTest { 2 3 @Test 4 public void test() { 5 final Lock lock = new TwinsLock(); 6 7 class Worker extends Thread { 8 public void run() { 9 while (true) { 10 lock.lock(); 11 12 try { 13 Thread.sleep(1000L); 14 System.out.println(Thread.currentThread()); 15 Thread.sleep(1000L); 16 } catch (Exception ex) { 17 18 } finally { 19 lock.unlock(); 20 }相關推薦
Java集合及concurrent併發包總結(轉)
集合包最常用的有Collection和Map兩個介面的實現類,Colleciton用於存放多個單物件,Map用於存放Key-Value形式的鍵值對。 Collection中最常用的又分為兩種型別的介面:List和Set,兩者最明顯的差別為List支援放入重複的元素,而Set不支援。List最常用的實
集合及concurrent併發包總結
1.集合包 集合包最常用的有Collection和Map兩個介面的實現類,Colleciton用於存放多個單物件,Map用於存放Key-Value形式的鍵值對。 Collection中最常用的又分為兩種型別的介面:List和Set,兩者最明顯的差別為List支
Java併發:多執行緒和java.util.concurrent併發包總結
引言前面已經針對Java多執行緒框架中具體的點介紹了很多了,現在是需要一個概括性總結的時候了,正好從網上找到一張描述java.util.concurrent包組成結構的類圖,正好可以對java多執行緒中
Java併發程式設計和高併發學習總結(一)-大綱
系列 開篇語 想寫這樣一個東西很久了,在慕課網上學完某老師的課程(避免打廣告的嫌疑就不貼出來了,感興趣的同學可以去慕課網上去搜來看看,是個付費課程)之後就覺得應該有這樣的一個學習總結的東西來,後來因為懶又有其他事情耽誤了,然後又上了新專案(正好拿來練手了,當然
Java IO流學習總結(轉)
rar output 出現 arr system 不存在 技術分享 輸出 寫入 原文地址:http://www.cnblogs.com/oubo/archive/2012/01/06/2394638.html Java流操作有關的類或接口: Java流類圖結構:
Fiddler 抓包工具總結(轉)
人的 現在 手機 inspect bubuko lec 開啟 區分 cmd 閱讀目錄 1. Fiddler 抓包簡介 1). 字段說明 2). Statistics 請求的性能數據分析 3). Inspectors 查看數據內容
【Java】 Spring 框架初步學習總結(一)簡單實現 IoC 和 AOP
1.0 其中 表示 只需要 第一篇 否則 info fin pojo Spring 是一個開源的設計層面的輕量級框架,Spring 的好處網上有太多,這裏就不在贅述。 IoC 控制反轉和 AOP 面向切面編程是 Spring 的兩個重要特性。 IoC(Inver
java集合類原始碼詳解-LinkedList(4)-基於JDK8
LinkedList 裡面還有個具有新增功能的函式,上回學漏了,這回補上。 它就是linkBefore()------在一個非空節點前,插入資料 這裡打上個斷點 點選下一步。先把size除二 ,去比較。具體的這個node()方法,我們之前學過,這裡跳過。這個方法,其實就
Java多執行緒程式設計學習總結(二)
(尊重勞動成果,轉載請註明出處:https://blog.csdn.net/qq_25827845/article/details/84894463冷血之心的部落格) 系列文章: Java多執行緒程式設計學習總結(一) Java多執行緒程式設計學習總結(二) 前
Java面試題,每日一總結(2)
1.字串String和StringBuilder 、StringBuffer的區別?StringBuilder和StringBuffer的區別? 分析:java提供了String和StringBuilder 、StringBuffer三種表示和操作字串的類。字串就是有多個字
Java 多執行緒程式設計學習總結(一)
定義篇 程序(Process)和執行緒(Thread) 怎樣實現多工處理(Multitasking)? 多工處理是同時執行多個任務的過程。我們使用多工處理來利用 CPU。可通過兩種方式實現多工處理: · 基於程序的多工 (多重處理) · 基於執行緒的多工處理
java集合類原始碼詳解-ArrayList(2)
上次關於ArrayList的結構沒有做總結。這次還是補充在自己部落格裡面吧。 ArrayList繼承自一個抽象類。實現了四個介面。 AbstractList繼承自AbstractCollection。AbstractCollection繼承自Object。 ArrayL
ueditor富文字編輯器java使用及最簡單的配置(ssh)
之前用過ueditor,結果這兩天要用又忘了怎麼用了,寫個文件記錄下來 1. UEditor簡介 UEditor是由百度web前端研發部開發所見即所得富文字web編輯器,具有輕量,可定製,注重使用者體驗等特點,開源基於MIT協議,允許自由使
java集合類原始碼詳解-ArrayList(5)
上次,測試了java集合類支援遍歷方式的效率比較,今天再通過斷電除錯,去ArrayList底層的迭代器做了什麼。 首先在迭代器這裡打上斷電,(在實際中變數ArrayList最後別用迭代器,因為他很慢) 可以看到這個iterator()方法返回值是一個迭代器,函式體是r
java弱型別總結(轉)
(因為最近寫個小工具,在手機平臺上需要用到,所以整理了大部分相關文件,希望對讀者有用,若有筆誤請來信告訴謝謝:[email protected])1.Java垃圾回收器概述 Java2平臺裡
java集合類原始碼詳解-ArrayList(1)
最近在瘋狂的補基礎 在java中 最重要的知識之一 非集合類莫屬。這次在學習java集合類原始碼,採用的是傳統的方法,斷點除錯和寫測試程式碼。由於是剛開始接觸java集合類原始碼。所以一開始只寫了兩句程式碼來測試,畢竟原始碼學習是很緩慢的過程。只能慢慢的啃。在閱
【深入Java虛擬機器】之精華總結(面試)
一.執行時資料區域 Java虛擬機器管理的記憶體包括幾個執行時資料記憶體:方法區、虛擬機器棧、堆、本地方法棧、程式計數器,其中方法區和堆是由執行緒共享的資料區,其他幾個是執行緒隔離的資料區。 1.1程式計數器 程式計數器是一塊較小的記憶體,他可以看做是當前執行緒所執行的行號指示器
【Java GUI】圖形使用者介面總結(1)
一、簡單視窗的顯示 import java.awt.Color; import java.awt.Container; import java.awt.Label; import javax.swing.*; public class SwingWin
【Java GUI】圖形使用者介面總結(2)
一、關於佈局管理器: package Layout; import java.awt.*; import javax.swing.*; public class BorderLayoutEx extends JFrame{ privat