
storm 原理簡介及單機版安裝指南
Storm是一個分散式的、高容錯的實時計算系統。
Storm對於實時計算的的意義相當於Hadoop對於批處理的意義。Hadoop為我們提供了Map和Reduce原語,使我們對資料進行批處理變的非常的簡單和優美。同樣,Storm也對資料的實時計算提供了簡單Spout和Bolt原語。
Storm適用的場景:
1、流資料處理:Storm可以用來用來處理源源不斷的訊息,並將處理之後的結果儲存到持久化介質中。
2、分散式RPC:由於Storm的處理元件都是分散式的,而且處理延遲都極低,所以可以Storm可以做為一個通用的分散式RPC框架來使用。
在這個教程裡面我們將學習如何建立Topologies, 並且把topologies部署到storm的叢集裡面去。Java將是我們主要的示範語言, 個別例子會使用python以演示storm的多語言特性。
1、準備工作
這個教程使用storm-starter專案裡面的例子。我推薦你們下載這個專案的程式碼並且跟著教程一起做。先讀一下:配置storm開發環境和新建一個strom專案這兩篇文章把你的機器設定好。
2、一個Storm叢集的基本元件
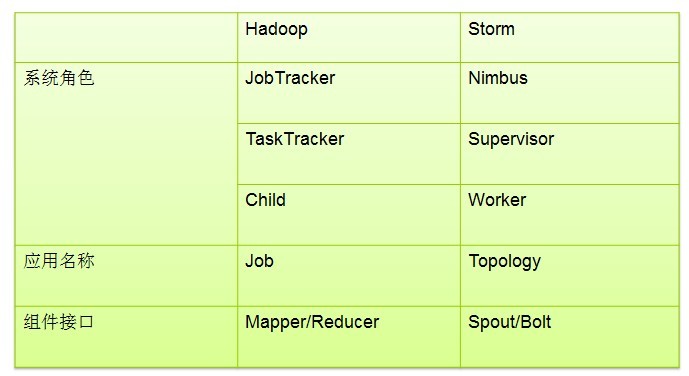
storm的叢集表面上看和hadoop的叢集非常像。但是在Hadoop上面你執行的是MapReduce的Job, 而在Storm上面你執行的是Topology。它們是非常不一樣的 — 一個關鍵的區別是: 一個MapReduce Job最終會結束, 而一個Topology運永遠執行(除非你顯式的殺掉他)。
在Storm的叢集裡面有兩種節點: 控制節點(master node)和工作節點(worker node)。控制節點上面執行一個後臺程式: Nimbus
每一個工作節點上面執行一個叫做Supervisor的節點(類似 TaskTracker)。Supervisor會監聽分配給它那臺機器的工作,根據需要 啟動/關閉工作程序。每一個工作程序執行一個Topology(類似 Job)的一個子集;一個執行的Topology由執行在很多機器上的很多工作程序 Worker(類似 Child)組成。

storm topology結構
Storm VS MapReduce
Nimbus和Supervisor之間的所有協調工作都是通過一個Zookeeper叢集來完成。並且,nimbus程序和supervisor都是快速失敗(fail-fast)和無狀態的。所有的狀態要麼在Zookeeper裡面, 要麼在本地磁碟上。這也就意味著你可以用kill -9來殺死nimbus和supervisor程序, 然後再重啟它們,它們可以繼續工作, 就好像什麼都沒有發生過似的。這個設計使得storm不可思議的穩定。
3、Topologies
為了在storm上面做實時計算, 你要去建立一些topologies。一個topology就是一個計算節點所組成的圖。Topology裡面的每個處理節點都包含處理邏輯, 而節點之間的連線則表示資料流動的方向。
執行一個Topology是很簡單的。首先,把你所有的程式碼以及所依賴的jar打進一個jar包。然後執行類似下面的這個命令。
1 |
strom
jar all-your-code.jar backtype.storm.MyTopology arg1 arg2 |
這個命令會執行主類: backtype.strom.MyTopology, 引數是arg1, arg2。這個類的main函式定義這個topology並且把它提交給Nimbus。storm jar負責連線到nimbus並且上傳jar檔案。
因為topology的定義其實就是一個Thrift結構並且nimbus就是一個Thrift服務, 有可以用任何語言建立並且提交topology。上面的方面是用JVM
-based語言提交的最簡單的方法, 看一下文章: 在生產叢集上執行topology去看看怎麼啟動以及停止topologies。
4、Stream
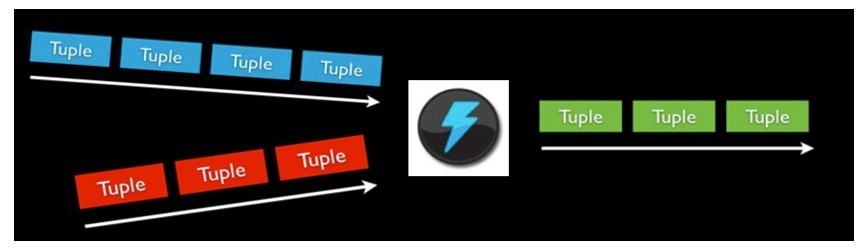
Stream是storm裡面的關鍵抽象。一個stream是一個沒有邊界的tuple序列。storm提供一些原語來分散式地、可靠地把一個stream傳輸進一個新的stream。比如: 你可以把一個tweets流傳輸到熱門話題的流。
storm提供的最基本的處理stream的原語是spout和bolt。你可以實現Spout和Bolt對應的介面以處理你的應用的邏輯。
spout的流的源頭。比如一個spout可能從Kestrel佇列裡面讀取訊息並且把這些訊息發射成一個流。又比如一個spout可以呼叫twitter的一個api並且把返回的tweets發射成一個流。
通常Spout會從外部資料來源(佇列、資料庫等)讀取資料,然後封裝成Tuple形式,之後傳送到Stream中。Spout是一個主動的角色,在介面內部有個nextTuple函式,Storm框架會不停的呼叫該函式。

bolt可以接收任意多個輸入stream, 作一些處理, 有些bolt可能還會發射一些新的stream。一些複雜的流轉換, 比如從一些tweet裡面計算出熱門話題, 需要多個步驟, 從而也就需要多個bolt。 Bolt可以做任何事情: 執行函式, 過濾tuple, 做一些聚合, 做一些合併以及訪問資料庫等等。
Bolt處理輸入的Stream,併產生新的輸出Stream。Bolt可以執行過濾、函式操作、Join、操作資料庫等任何操作。Bolt是一個被動的角色,其介面中有一個execute(Tuple input)方法,在接收到訊息之後會呼叫此函式,使用者可以在此方法中執行自己的處理邏輯。
spout和bolt所組成一個網路會被打包成topology, topology是storm裡面最高一級的抽象(類似 Job), 你可以把topology提交給storm的叢集來執行。topology的結構在Topology那一段已經說過了,這裡就不再贅述了。

topology結構
topology裡面的每一個節點都是並行執行的。 在你的topology裡面, 你可以指定每個節點的並行度, storm則會在叢集裡面分配那麼多執行緒來同時計算。
一個topology會一直執行直到你顯式停止它。storm自動重新分配一些執行失敗的任務, 並且storm保證你不會有資料丟失, 即使在一些機器意外停機並且訊息被丟掉的情況下。
5、資料模型(Data Model)
storm使用tuple來作為它的資料模型。每個tuple是一堆值,每個值有一個名字,並且每個值可以是任何型別, 在我的理解裡面一個tuple可以看作一個沒有方法的java物件。總體來看,storm支援所有的基本型別、字串以及位元組陣列作為tuple的值型別。你也可以使用你自己定義的型別來作為值型別, 只要你實現對應的序列化器(serializer)。
一個Tuple代表資料流中的一個基本的處理單元,例如一條cookie日誌,它可以包含多個Field,每個Field表示一個屬性。

Tuple本來應該是一個Key-Value的Map,由於各個元件間傳遞的tuple的欄位名稱已經事先定義好了,所以Tuple只需要按序填入各個Value,所以就是一個Value List。
一個沒有邊界的、源源不斷的、連續的Tuple序列就組成了Stream。

topology裡面的每個節點必須定義它要發射的tuple的每個欄位。 比如下面這個bolt定義它所發射的tuple包含兩個欄位,型別分別是: double和triple。
01 |
publicclassDoubleAndTripleBoltimplementsIRichBolt
{ |
02 |
privateOutputCollectorBase
_collector; |
03 |
04 |
@Override |
05 |
publicvoidprepare(Map
conf, TopologyContext context, OutputCollectorBase collector) { |
06 |
_collector
= collector; |
07 |
} |
08 |
09 |
@Override |
10 |
publicvoidexecute(Tuple
input) { |
11 |
intval
= input.getInteger(
|