
MySQL資料庫 詳解
阿新 • • 發佈:2019-02-19
資料型別
1> 整數型別

(1)指定型別顯示寬度:資料型別(顯示寬度) 如:INT(4) (2)ZEROFILL 屬性:用於資料不足的顯示空間由0來填補,可以大量用於所謂“流水號”的生成上 如:CREATE TABLE t1(id INT(6) ZEROFILL AUTO_INCREMENT PRIMARY KEY,col2 VARCHAR(32)); (3)AUTO_INCREMENT 屬性:是欄位成為自增欄位 (4)UNSIGNED 屬性:將整型轉換成無符號的
2> 浮點數型別和定點數型別
(1)指定浮點數和定點數的精度:資料型別(M,D) M引數的精度數,就是資料的長度 D引數的表弟,就是小數點後的長度
如:FLOAT(6,2) 3> 日期與時間型別

(1)YEAR以YYYY的形式顯示年份
注:使用2位字串表示,如:00 或 "00" 會轉換成 2000 (2)TIME以D HH:MM:SS形式儲存,但可以不按照嚴格方式儲存 如:HH:MM
(3)CURRENT_TIME 或 NOW() 表示當前系統時間
(4)DATE以YYYY-MM-DD 形式儲存,支援不嚴格語法如YYYY/MM/DD YYYY@MM@DD YYYY.MM.DD 會自動轉換成 YYYY-MM-DD 格式
注:DATETIME只能使用NOW()來傳遞當前系統時間
(6)TIMESTAMP也是以YYYY-MM-DD HH:MM:SS 形式儲存,但是其範圍比DATETIME要小
注:使用CURRENT_TIMESTAMP 或 NULL 或 無任何輸入,系統會輸入當前系統時間
4> 字串型別
包括 CHAR、VARCHAR、BLOB、TEXT、ENUM、SET 注:<1> 儲存路勁“\”會被系統過濾掉,需要轉義成 “\\”或“/” <2> MySQL儲存BOOLEAN或BOOL其最終會轉換成TINYINT(1)儲存
(1)CHAR 和 VARCHAR
都是在建立表時指定最大長度,形式:字串型別(M) M最大長度 VARCHAR是在範圍內長度可變用多少分配多少因此資源利用率高,而CHAR始終佔用指定長度的空間有點費空間但是查詢效率比VARCHAR快很多,因此CHAR適用於作主鍵 或 儲存固定長度字串資料 或 頻繁修改資料
(2)TEXT
用於儲存大量的文字資訊,佔用資源大,謹慎使用。各種TEXT型別僅僅在於儲存資料多少的差異
(3)ENUM
以列表的形式指定,形式為 屬性名 ENUM('value1','value2',...) 只能取其中一個
注:若加上NOT NULL則預設取列表中第一個元素 (4)SET
以列表的形式指定,形式為 屬性名 SET('value1','value2',...) 可取一個或多個,不同元素之間用逗號隔開,插入資料時系統會按照定義順序顯示,如:插入 ('C','B','D') 資料庫中以 B,C,D 形式儲存
5> 二進位制型別


6> BOOLEAN型別
BOOLEAN值時用1代表TRUE,0代表FALSE,boolean在MySQL裡的型別為tinyint(1),四個常量:true,false,TRUE,FALSE,它們分別代表1,0,1,0 如:insert into test(isOk) values(true); 操作資料庫 1> 資料庫登入 dos視窗連線資料庫 mysql -h localhost -u root -p 在輸入密碼 2> 資料庫建立、刪除、查詢操作 (1)建立資料庫 CREATE DATABASE 資料庫名;
(2)顯示系統中所有的資料庫SHOW DATABASES; (3)刪除資料庫 DROPDATABASE 資料庫名; 注:刪除資料庫指令將會刪除資料庫中所有的資料和表 (4)使用資料庫 USE 資料庫名稱; 3> 儲存引擎 (1)查詢系統中支援的儲存引擎 SHOW ENGINES;
注:<1> Engine屬性指儲存引擎名稱,Support屬性指是否支援該型別YES表示支援NO表示不支援DEFAULT表示預設,Comment屬性指對該引擎的評論,Transactions屬性指是否支援事務處理,XA屬性指是否分散式處理XA規範,Savepoints屬性指是否支援儲存點以便回滾到儲存點 <2> 一般使用預設 InnoDB 就可以 (2)常用的儲存引擎

4> 表的建立、修改、刪除 (1)建立表 CRETAE TABLE 表名(屬性名 資料型別 [完整性約束條件],...)
(2)完整性約束
<1> 單子段主鍵:屬性名 資料型別 PRIMARYKEY KEY 如:CREATE TABLE T1(id INTEGER PRIMARY KEY,name VARCHAR(20)); 多欄位主鍵:PRIMARY KEY(屬性名1,屬性名2,...) 如:CREATE TABLE T1(id INTEGER,name VARCHAR(20),PRIMARY KEY(id,name)); <2> 表的外來鍵(必須依賴於父表的主鍵,期可以為空):CONSTRAINT 外來鍵別名 FOREIGN KEY(屬性名1.1,屬性名1.2,...) REFERENCES 表名(屬性名2.1,屬性名2.2,...)
如:CREATE TABLE T1(id INTEGER PRIMARY KEY,name VARCHAR(20),CONSTRAINT c_fk FOREIGN KEY(id) REFERENCES T2(id)); <3> 非空約束:屬性名 資料型別 NOT NULL
<4> 唯一性約束:屬性名 資料型別 UNIQUE
<5> 自動增長(主要用於為新紀錄生成唯一ID且一個表只有一個AUTO_INCREMENT約束並是主鍵的一部分其是任何整數型別):屬性名 資料型別 AUTO_INCREMENT
<6> 預設值:屬性名 資料型別 DEFAULT 預設值
(3)查看錶結構: <1> 表基本結構:DESCRIBE 表名;
<2> 表詳細結構:SHOW CREATE TABLE 表名; (4)修改表 <1> 修改表名:ALTER TABLE 舊錶名 RENAME [TO] 新表名; <2> 修改資料型別:ALTER TABLE 表名 MODIFY 屬性名 資料型別; <3> 修改欄位名:ALTER TABLE 表名 CHANGE 舊屬性名 新屬性名 新資料型別; <4> 增加欄位:ALTER TABLE 表名 ADD 屬性名1 資料型別 [完整性約束] [FIRST|AFTER 屬性名];
<5> 刪除欄位:ALTER TABLE 表名 DROP 屬性名;
<6> 修改儲存引擎:ALTER TABLE 表名 ENGINE=儲存引擎名
(5)刪除表
<1> 沒有關聯的普通表:DROP TABLE 表名;
<2> 有關聯的父表:先刪除關聯表外來鍵約束 ALTER TABLE 表名 DROP FOREIGN KEY 外來鍵名 再刪除表
5> 事務,事務是一個最小的、不可分割的工作單元,不論成功與否都作為一個整體進行工作,其具有Atomic(原子性),Consistent(一致性),Isolated(隔離性),Durable(永續性)
語法規則: // 開啟事務 START TRANSACTION;
// 提交事務 COMMIT;
// 回滾 ROLLBACK; 索引
用於快速查詢資料庫表中的資料 優點:提高檢索資料的速度 缺點:索引需要佔用物理空間,因此在增加、刪除、修改資料時會造成維護速度降低 1> 索引的設計原則 (1)選擇唯一性索引,可更快通過索引確定某條記錄
(2)為經常需要排序ORDER BY、分組GROUP BY和聯合操作UNION的欄位建立索引
(3)為常作為查詢條件的欄位建立索引
(4)限制索引的數目,索引太多需要的磁碟空間就越大,修改表示對索引的重構和更新會很麻煩
(5)儘量使用資料量少的索引,對CHAR(100)全文索引肯定會比CHAR(10)耗時多
(6)儘量使用字首來索引
(7)刪除不再使用或者很少使用的索引
2> 建立索引 建立表時建立索引,其最基本形式是 CREATE TABLE 表名(屬性名 資料型別 [完整性約束條件],屬性名 資料型別 [完整性約束條件]... 屬性名 資料型別 [UNIQUE|FULLTEXT|SPATIAL] INDEX|KEY [別名] (屬性名1 [(長度)] [ASC|DESC])) FULLTEXT是可選引數表示全文索引,SPATIAL是可選引數表示空間索引,INDEX和KEY指定那些欄位是索引二擇其一作用相同 (1)建立普通索引:如:CREATE TABLE T1(id INT,name VARCHAR(50),INDEX(id))
(2)建立唯一性索引:如:CREATE TABLE T1(id INT UNIQUE,name VARCHAR(50),INDEX(id ASC))
(3)建立全文索引:全文索引只建立在CHAR、VARCHAR或TEXT型別的欄位上,且只有MyISAM儲存支援全文索引 如:CREATE TABLE T1(id INT,name VARCHAR(50),FULLTEXT INDEX(name))
(4)建立單列索引:在單個欄位上的一部分建立索引只查詢前面若干索引 如:CREATE TABLE T1(id INT,name VARCHAR(50),INDEX(name(10)))
(5)建立多列索引:在表的多個欄位上建立一個索引 如:CREATE TABLE T1(id INT,name VARCHAR(50),INDEX(id,name))
注:只有在使用索引中的第一個欄位時才會觸發索引 (6)建立空間索引:
(7)在已存在的表上建立索引:CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名 ON 表名 (屬性名 [(長度)] [ASC|DESC])
(8)用ALTER TABLE語句來建立索引:ALTER TABLE 表名 ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名 ON 表名 (屬性名 [(長度)] [ASC|DESC])
如:ALTER TABLE Info_Pictures ADD INDEX pictures_index_userId(picturesUserId, picturesCreatetime ASC) 3> 刪除索引 基本形式是 DROP INDEX 索引名 ON 表名
檢視
檢視是一種虛擬的表由一個或多個表匯出,其可以從已存在的檢視基礎上定義,資料庫中只存放檢視的定義沒有存放檢視中的資料,資料依舊在原來的表中。使用檢視時會從原來的標中取出對應的資料,因此檢視中的資料依賴於原來的表中的資料,一旦表中的資料發生變化,顯示在檢視中的資料也會發生變化 1> 建立檢視 語法形式:CREATE [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW 檢視名 [(屬性清單)] AS SELECT 語句 [WITH [CASCADED|LOCAL] CHECK OPTION] ALGORITHM為可選引數表示檢視選擇的演算法其包括3個選項UNDEFINED(自動選所使用的演算法)、MERGE(使用檢視語句與檢視定義結合起來使得檢視定義的某一部分取代語句對應部分)、TEMPTABLE(將檢視的結果存入臨時表再使用零時表執行語句),WITH CHECK OPTION是可選引數表示更新檢視時要保證在該檢視的許可權範圍內 注:建立檢視時,最好加上WITH CHECK OPTION 和 CASCADED,這樣從檢視派生出來的新檢視後,更新新檢視需要考慮其父檢視的約束條件 (1)單表建立檢視:如:CREATE VIEW v1 AS SELECT * FROM t1;
(2)多表建立檢視:如:CREATE ALGORITHM=MERGE VIEW v1(name,age) AS SELECT name,age FROM t1,t2 WITH LOCLA CHECH OPTION;
2> 修改檢視
語法形式:CREATE OR REPLACE [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW 檢視名 [(屬性清單)] AS SELECT 語句 [WITH [CASCADED|LOCAL] CHECK OPTION]
或是使用ALERT語句 ALTER [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW 檢視名 [(屬性清單)] AS SELECT 語句 [WITH [CASCADED|LOCAL] CHECK OPTION] 注:只要有許可權,更新檢視中的資訊,對應的表中資料也將更新 無法更新檢視的情況 (1)檢視中包含SUN()、COUNT()、MAX()、MIN()等函式
(2)檢視中包含UNION、UNION ALL、DISTINCT、GROUP BY、HAVING
(3)常亮檢視
(4)檢視中包含SELECT子查詢
(5)由不可更新的試圖匯出的檢視
(6)建立檢視時,ALGORITHM為TEMPTABLE
3> 刪除檢視
語法形式:DROP VIEW [IF EXISTS] 檢視名 [RESTRICT|CASCADE]
觸發器
觸發器是由INSERT、UPDATE、DELETE語句觸發 1> 建立只有一個執行語句的觸發器,語法形式:CREATE TRIGGER 觸發器名 BEFORE|AFTER 觸發事件 ON 表名 FOR EACH ROW 執行語句; BEFORE指在觸發事件之前執行觸發語句,AFTER在觸發事件之後執行語句,觸發事件指觸發條件可以是INSERT、UPDATE、DELETE,表名指觸發事件操作的表的名稱,FOR EACH ROW表示任何一條記錄上的操作滿足觸發事件都會觸發該觸發器,執行語句指觸發器被觸發後執行的程式 如:CREATE TRIGGER trigger1 BEFORE INSERT ON t1 FOR EACH ROW INSERT INTO time VALUES(NOW());
2> 建立多個執行語句的觸發器,語法形式:CREATE TRIGGER 觸發器名 BEFORE|AFTER 觸發事件 ON 表名 FOR EACH ROW BEGIN 所有執行語句 END
注:1> 一般系統以“;”作為執行語句,在建立觸發器過程中需要用到“;”,可以使用DELIMITER語句防止多條執行語句結尾的“;”導致提前執行觸發器,如: DELIMITER
&& CREATE TRIGGER trigger1 AFTER DELETE ON t1 FOR EACH ROW BEGIN INSERT INTO t2(time) VALUES(NOW()); INSERT INTO t3(time) VALUES(NOW());
END
&&
DELIMITER;
2> 同一個表在相同觸發事件的相同觸發事件,只能建立一個觸發器,像是同一個表可建立INSERT事件的BEFORE和AFTER事件 3> 顯示觸發器,語法形式:SHOW TRIGGERS;
4> 觸發器的執行順序是BEFORE觸發器、表操作(INSERT、UPDATE和DELETE)和AFTER觸發器 5> 觸發器中不能包含START TRANSACTION、COMMIT、CLAA或ROLLBACK的關鍵詞,觸發器在執行過程中任何步驟出錯都會組織程式向下執行,對於普通表已更新過的記錄不能回滾,更新後的資料將繼續保持在表中 6> 刪除觸發器,語法形式:DROP TRIGGER 觸發器名; 查詢資料
1> 基本查詢語句,語法形式:SELECT 屬性列表 FROM 表名和檢視列表 [WHERE 條件表示式1] [GROUP BY 屬性名1 [HAVING 條件表示式2]] [ORDER BY 屬性名2 [ASC|DESC]]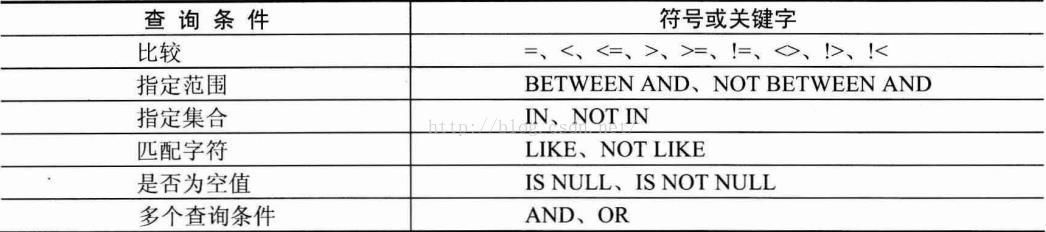
(1)語法規則:[NOT] IN(元素1,元素2,...)
(2)語法規則:[NOT] BETWEEN 取值1 AND 取值2 如:SELECT * FROM t1 WHERE age BETWEEN 15 AND 25;
(3)語法規則:[NOT] LIKE '字串' “%”代表任意長度的字串,“_”代表單個字串
(4)語法規則:IS [NOT] NULL 如:SELECT * FROM t1 WHERE column1 IS NULL;
(5)AND 同時滿足多條查詢條件,OR 滿足其中一條查詢條件
(6)查詢結果不重複,語法規則:SELECT DISTINCT 屬性名 如:SELECT DISTINCT column1 FROM t1;
(7)語法規則:ORDER BY 屬性名 [ASC|DESC]
(8)分組查詢,語法規則:GROUP BY 屬性名 [HAVING 條件表示式] [WITH ROLLUP] WITH ROLLUP關鍵字會在所有記錄的最後加上一條記錄,記錄所有記錄的總和,GROUP BY關鍵字通常與幾何函式一起使用COUNT()統計記錄總數、SUM()計算欄位的值的綜合、AVG()計算欄位值的平均值、MAX()查詢欄位的最大值、MIN()查詢欄位的最小值、GROUP_CONCAT()將分組中指定欄位值都顯示出來,如:SELECT GROUP_CONCAT(name) FROM t1 GROUP BY sex; 返回的資料是 name1,name2,name3 注:1> {1,2,3}就是升序,{3,2,1}就是降序,預設是ASC 2> *是所有欄位 2> LIMIT限制查詢結果數量 (1)不指定初始化位置,從第一條記錄開始顯示指定條數記錄,語法規則:LIMIT 記錄數 如:SELECT * FROM t1 LIMIT 2;
(2)指定初始化位置,位置基於0,語法規則:LIMIT 初始位置,記錄數 如:SELECT * FROM t1 LIMIT 0,2; SELECT * FROM table LIMIT 5,10; // 檢索記錄行 6-15 SELECT * FROM table LIMIT 95,-1; // 為了檢索從某一個偏移量到記錄集的結束所有的記錄行,可以指定第二個引數為 -1:檢索記錄行 96-last SELECT * FROM table LIMIT 5; // 如果只給定一個引數,它表示返回最大的記錄行數目,換句話說,LIMIT n 等價於 LIMIT 0,n:檢索前 5 個記錄行 3> 連線查詢 (1)內連線查詢,如:SELECT a.name,b.name FROM t1,t2 WHERE t1.id=t2.id;
(2)外連結查詢,語法規則:SELECT 屬性名列表 FROM 表名1 LEFT|RIGHT JOIN 表名2 ON 表名1.屬性=表名2.屬性;
4> 子查詢 (1)帶IN關鍵字的子查詢,如:SELECT * FROM t2 WHERE column1 IN(SELECT column1 FROM t2)
(2)帶比較運算子的子查詢,如:SELECT * FROM t2 WHERE column1>=(SELECTcolumn1 FROM t2)
(3)帶EXISTS的子查詢,如:SELECT * FROM t2 WHERE EXISTS(SELECTcolumn1 FROM t2)
(4)帶ANY關鍵字的子查詢,ANY關鍵字表示滿足其中任一條件,如:SELECT * FROM t2 WHERE column1>=ANY(SELECTcolumn1 FROM t2)
(5)帶ALL關鍵字的子查詢,ALL關鍵字表示滿足所有條件,如:SELECT * FROM t2 WHERE column1>=ALL(SELECTcolumn1 FROM t2) 5> 合併查詢結果 語法規則:SELECT 語句1 UNION|UNION ALL SELECT 語句2 UNION|UNION ALL... 如:SELECT id FROM t1 UNION SELECT id FROM t2 注:UNION關鍵字會將所有查詢出的結果合併到一起,再去除所有相同記錄,而UNION ALL 則可能存在相同記錄 6> 位欄位取別名 語法規則:屬性名 [AS] 別名 7> 正則表示式查詢,語法規則:屬性名 REGEXP '匹配方式'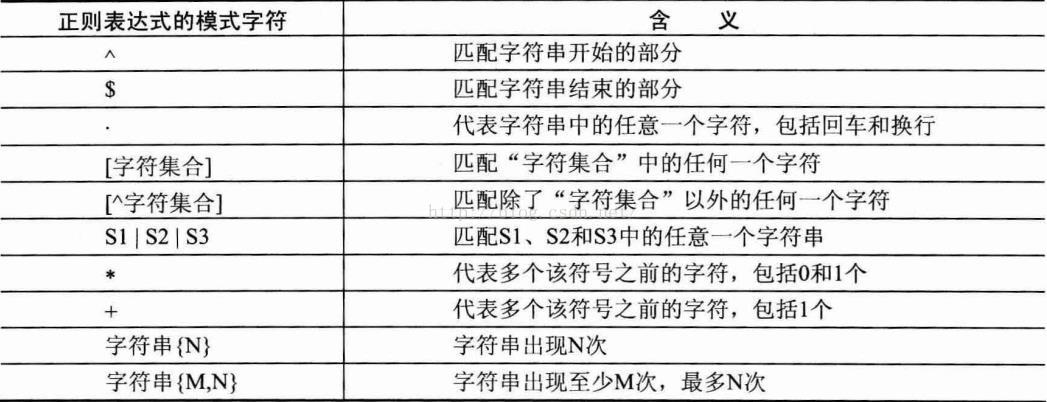
插入、更新與刪除資料
1> 插入資料 (1)不指定具體欄位名,語法規則:INSERT INTO 表名 VALUES(值1,值2...)
(2)指定具體欄位名,語法規則:INSERT INTO 表名(屬性1,屬性2...) VALUES(值1,值2...)
(3)同時插入多條資料,語法規則:INSERT INTO 表名[(屬性列表)] VALUES(值列表1),(值列表2)...
(4)將查詢結果插入到表中,語法規則:INSERT INTO 表名1(屬性列表1) SELECT 屬性列表2 FROM 表名2 WHERE 條件表示式;
2> 更新資料 語法規則:UPDATE 表名 SET 屬性1=值1,... WHERE 條件表示式
3> 刪除資料 語法規則:DELETE FROM 表名 [WHERE 條件表示式] 運算子
1> 算術運算子
如:SELECT a,a+10,a-5 FROM t1 2> 比較運算子
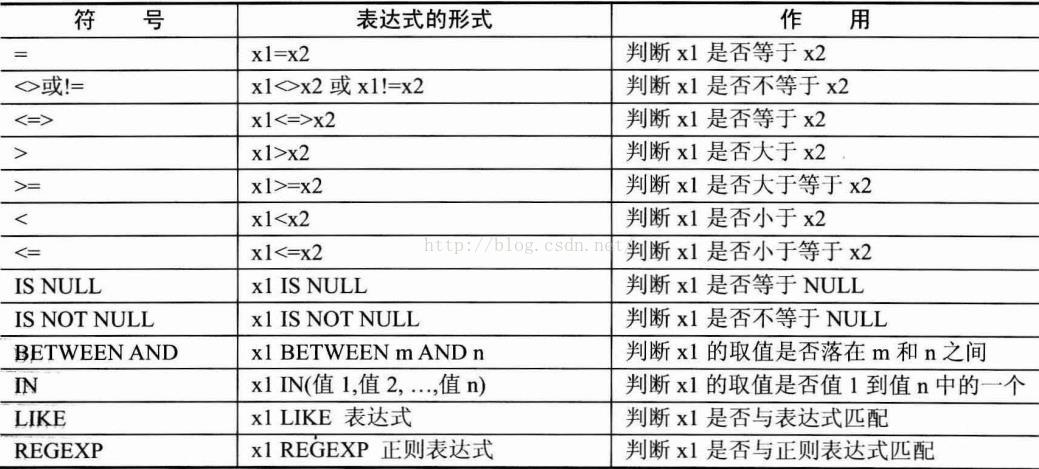
3> 邏輯運算子

4> 位運算子

函式
1> 數學函式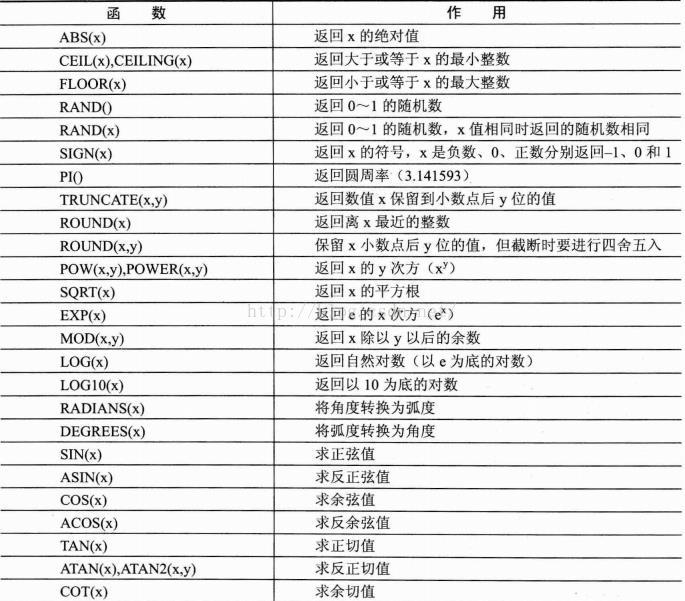
2> 字串函式
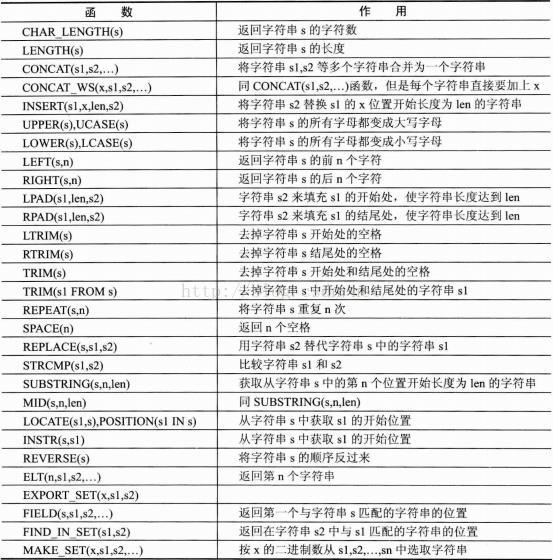
3> 日期時間函式
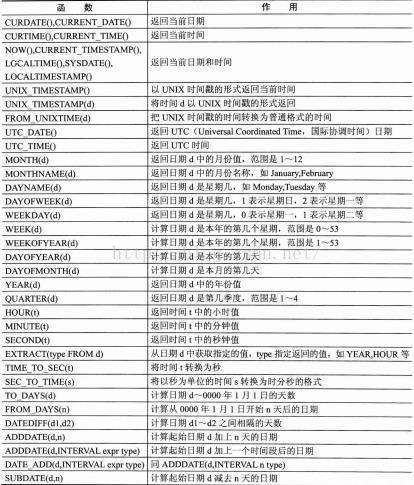
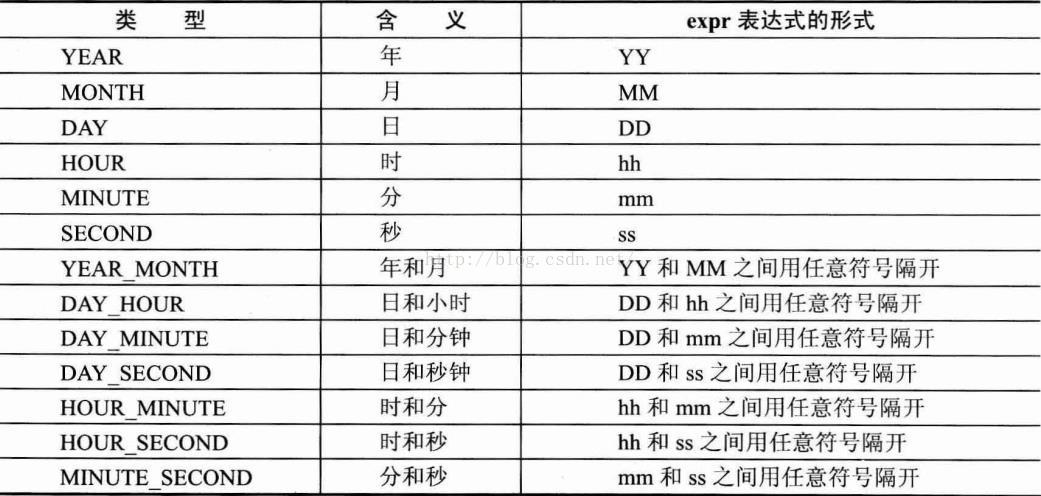

4> 條件判斷函式
(1)IF(expr,v1,v2)函式:如果表示式expr成立返回v1否則返回v2,如:SELECT id,IF(grade>=60,'PASS','FAIL') from t1;
(2)IFNULL(v1,v2)函式:v1不為空則返回v1否則返回v2
(3)CASE函式
<1> CASE WHEN expr1 THEN v1 [WHEN e2 THEN v2...] [ELSE vn] END CASE表示開始,END表示函式結束,expr1成立返回v1,依次類推,最後ELESE時返回vn 如:SELECT id,grade,CASE WHEN grade>60 THEN 'GOOD' WHEN grade=60 THEN 'PASS' ELSE 'FAIL' END level FROM t6; <2> CASE expr WHEN e1 THEN v1 [WHEN e2 THEN v2...] [ELSE vn] END 如果欄位expr等於e1返回v1依次類推
如:SELECT id,grade,CASE grad WHEN grade>60 THEN 'GOOD' WHEN grade=60 THEN 'PASS' ELSE 'FAIL' END level FROM t6;
5> 系統資訊函式
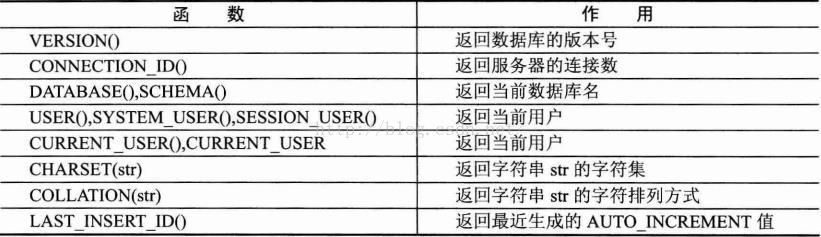
6> 加密函式
(1)PASSWORD(str):對字串加密 如:SELECT PASSWORD('abcde') (2)MD5(str):MD5對str加密 (3)ENCODE(str,pswd_str):使用字串pswd_str來加密字串str,加密結果是二進位制數,必須使用BLOB型別儲存
(4)DECODE(crypt_str,pswd_str):使用pswd_str來為crypt_str解密
7> 其它函式
(1)FORMAT(x,n):數字x進行格式化,將x保留小數點後n位 儲存過程和函式
儲存過程和函式是在資料庫中定義一些SQL語句的集合,然後直接呼叫這些儲存過程和函式來執行已經定義好的SQL語句。儲存過程可以避免開發人員重複的編寫相同的SQL語句。而且,儲存過程和函式是在MySQL伺服器中儲存和執行的,可以減少客戶端和伺服器端的傳輸資料 1> 建立儲存過程:CREATE PROCEDURE sp_name([proc_parameter[,...]]) [characteristic...] routine_body sp_name是儲存過程名稱 proc_parameter是儲存過程的引數列表每個引數有3個部分組成分別是輸入輸出型別、引數名稱和引數型別心事如:[IN|OUT|INOUT] param_name type characteristic是儲存過程的特性 注:系統預設指定CONTAINS SQL,表示使用SQL語句,如果沒有使用SQL,最好設定為NO SQL
routine_body是程式碼的內容,可以用BEGIN...END來標誌SQL程式碼的開始和結束
如:
DELIMITER
&&
CREATE PROCEDURE num_from_employee(IN emp_id INT,OUT count_num INT)
READS SQL DATA
BEGIN
SELECT COUNT(*) INTO count_num FROM employee WHERE d_id=emp_id;
END
&&
DELIMITER
注:系統預設指定CONTAINS SQL,表示使用SQL語句,如果沒有使用SQL,最好設定為NO SQL
routine_body是程式碼的內容,可以用BEGIN...END來標誌SQL程式碼的開始和結束
如:
DELIMITER
&&
CREATE PROCEDURE num_from_employee(IN emp_id INT,OUT count_num INT)
READS SQL DATA
BEGIN
SELECT COUNT(*) INTO count_num FROM employee WHERE d_id=emp_id;
END
&&
DELIMITER
2> 建立儲存函式:CREATE FUNCTION sp_name([func_parameter[,....]]) RETURANS type [characteristic...] routine_body
如: DELIMITER && CREATE FUNCTION name_from_employee(emp_id INT) RETURNS VARCHAR(20)
BEGIN RETUEN (SELECT name FROM employee WHERE num=emp_id); END && DELIMITER
3> 變數使用 (1)定義變數,語法規則:DECLARE var_name[,...] type [DEFAULT value] DECLARE關鍵字用來宣告變數,var_name是變數名稱,type是變數型別,DEFAULT value是預設值沒有預設是NULL
如:DECLARE my_sql INT DEFAULT 10; (2)變數賦值,語法規則:SET var_name=expr[,var_name=expr]... 如:SET my_sql=30;
SELECT col_name[,...] INTO var_name[,...] FROM table_name WHERE condition 如:SELECT d_id INTO my_sql FROM employee WHERE id=2 5> 流程控制使用
(1)IF語句,基本語法形式:IF search_condition THEN statement_list
[ELSEIF search_condition THEN statement_list]... END IF 如:IF age>20 THEN SET @count=@count+1; ELSEIF age=20 THEN @count2=@count2+1; ELSE @count3=@count3+1; END IF; (2)CASE語句,可以實現比IF語句更復雜的條件判斷,語法形式:
CASE case_value WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list]...
[ELSE statement_list]
END CASE
或是 CASE WHEN search_value THEN statement_list
[WHEN search_value THEN statement_list]...
[ELSE statement_list]
END CASE 如:CASE age
WHEN 20 THEN SET @count1=@count1+1; ELSE SET @count2=@count2+1;
END CASE;
或是
CASE
WHEN age=20 THEN SET @count1=@count1+1; ELSE SET @count2=@count2+1;
END CASE; (3)LOOP語句,迴圈執行,必須使用LEAVE停止迴圈,語法形式:
[begin_label:]LOOP
statement_list END LOOP [end_label]
如:
add_num:LOOP
SET @count=@count+1; IF @count=100 THEN LEAVE ad_num;
END LOOP add_num;
(4)ITERATE語句:跳出本次迴圈,進入下一次迴圈,語法格式:ITERATE label
如:
add_num:LOOP
SET @count=@count+1;
IF @count=100 THEN LEAVE add_num;
ELSE IF MOD(@count,3)=0 THEN ITERATE add_num;
SELECT * FROM employee;
END LOOP add_num;
(4)REPEADT語句,滿足條件時跳出迴圈語句,語法格式:
[begin_label] REPEAT
statement_list
UNTIL search_condition
END REPEAT [end_label]
如: REPEAT
SET @count=@count+1; UNTIL @count=100; END REPEAT; (5)WHILE語句,當滿足條件執行迴圈內的語句,語法格式:
[begin_label:] WHILE search_condition DO
statement_list END WHILE [end_label]
如:
WHILE @count<100 DO
SET @count=@count+1;
END WHILE;
6> 呼叫儲存過程和函式
(1)呼叫儲存過程,系統執行儲存過程中的語句,然後將結果返回,基本語法:
CALL sp_name([parameter[,...]])
如:
// 建立儲存過程 DELIMITER &&
CASER PROCEDURE num_from_employee(IN emp_id,OUT count_num INT)
READS SQL DATA BEGIN
SELECT COUNT(*) INTO count_num FROM employee WHERE d_id=emp_id;
END &&
DELIMITER;
// 呼叫儲存過程
CALL num_from_employee(1002,@n);
// 查詢返回結果
SELECT @n;
(2)呼叫儲存過程,如:
// 建立儲存函式 DELIMITER &&
CREATE FUNCTION name_from_employee(emp_id INT)
RETURNS VARCHAR(20) BEGIN
RETURN (SELECT name FROM employee WHERE num=emp_id);
END&&
DELIMITER;
// 呼
(1)指定型別顯示寬度:資料型別(顯示寬度) 如:INT(4) (2)ZEROFILL 屬性:用於資料不足的顯示空間由0來填補,可以大量用於所謂“流水號”的生成上 如:CREATE TABLE t1(id INT(6) ZEROFILL AUTO_INCREMENT PRIMARY KEY,col2 VARCHAR(32)); (3)AUTO_INCREMENT 屬性:是欄位成為自增欄位 (4)UNSIGNED 屬性:將整型轉換成無符號的
2> 浮點數型別和定點數型別
(1)指定浮點數和定點數的精度:資料型別(M,D) M引數的精度數,就是資料的長度 D引數的表弟,就是小數點後的長度
如:FLOAT(6,2) 3> 日期與時間型別
(1)YEAR以YYYY的形式顯示年份
注:使用2位字串表示,如:00 或 "00" 會轉換成 2000 (2)TIME以D HH:MM:SS形式儲存,但可以不按照嚴格方式儲存 如:HH:MM
(3)CURRENT_TIME 或 NOW() 表示當前系統時間
(4)DATE以YYYY-MM-DD 形式儲存,支援不嚴格語法如YYYY/MM/DD YYYY@MM@DD YYYY.MM.DD 會自動轉換成 YYYY-MM-DD 格式
注:DATETIME只能使用NOW()來傳遞當前系統時間
(6)TIMESTAMP也是以YYYY-MM-DD HH:MM:SS 形式儲存,但是其範圍比DATETIME要小
注:使用CURRENT_TIMESTAMP 或 NULL 或 無任何輸入,系統會輸入當前系統時間
4> 字串型別
包括 CHAR、VARCHAR、BLOB、TEXT、ENUM、SET 注:<1> 儲存路勁“\”會被系統過濾掉,需要轉義成 “\\”或“/” <2> MySQL儲存BOOLEAN或BOOL其最終會轉換成TINYINT(1)儲存
(1)CHAR 和 VARCHAR
都是在建立表時指定最大長度,形式:字串型別(M) M最大長度 VARCHAR是在範圍內長度可變用多少分配多少因此資源利用率高,而CHAR始終佔用指定長度的空間有點費空間但是查詢效率比VARCHAR快很多,因此CHAR適用於作主鍵 或 儲存固定長度字串資料 或 頻繁修改資料
(2)TEXT
用於儲存大量的文字資訊,佔用資源大,謹慎使用。各種TEXT型別僅僅在於儲存資料多少的差異
(3)ENUM
以列表的形式指定,形式為 屬性名 ENUM('value1','value2',...) 只能取其中一個
注:若加上NOT NULL則預設取列表中第一個元素 (4)SET
以列表的形式指定,形式為 屬性名 SET('value1','value2',...) 可取一個或多個,不同元素之間用逗號隔開,插入資料時系統會按照定義順序顯示,如:插入 ('C','B','D') 資料庫中以 B,C,D 形式儲存
5> 二進位制型別
6> BOOLEAN型別
BOOLEAN值時用1代表TRUE,0代表FALSE,boolean在MySQL裡的型別為tinyint(1),四個常量:true,false,TRUE,FALSE,它們分別代表1,0,1,0 如:insert into test(isOk) values(true); 操作資料庫 1> 資料庫登入 dos視窗連線資料庫 mysql -h localhost -u root -p 在輸入密碼 2> 資料庫建立、刪除、查詢操作 (1)建立資料庫 CREATE DATABASE 資料庫名;
(2)顯示系統中所有的資料庫SHOW DATABASES; (3)刪除資料庫 DROPDATABASE 資料庫名; 注:刪除資料庫指令將會刪除資料庫中所有的資料和表 (4)使用資料庫 USE 資料庫名稱; 3> 儲存引擎 (1)查詢系統中支援的儲存引擎 SHOW ENGINES;
注:<1> Engine屬性指儲存引擎名稱,Support屬性指是否支援該型別YES表示支援NO表示不支援DEFAULT表示預設,Comment屬性指對該引擎的評論,Transactions屬性指是否支援事務處理,XA屬性指是否分散式處理XA規範,Savepoints屬性指是否支援儲存點以便回滾到儲存點 <2> 一般使用預設 InnoDB 就可以 (2)常用的儲存引擎
4> 表的建立、修改、刪除 (1)建立表 CRETAE TABLE 表名(屬性名 資料型別 [完整性約束條件],...)
(2)完整性約束
<1> 單子段主鍵:屬性名 資料型別 PRIMARYKEY KEY 如:CREATE TABLE T1(id INTEGER PRIMARY KEY,name VARCHAR(20)); 多欄位主鍵:PRIMARY KEY(屬性名1,屬性名2,...) 如:CREATE TABLE T1(id INTEGER,name VARCHAR(20),PRIMARY KEY(id,name)); <2> 表的外來鍵(必須依賴於父表的主鍵,期可以為空):CONSTRAINT 外來鍵別名 FOREIGN KEY(屬性名1.1,屬性名1.2,...) REFERENCES 表名(屬性名2.1,屬性名2.2,...)
如:CREATE TABLE T1(id INTEGER PRIMARY KEY,name VARCHAR(20),CONSTRAINT c_fk FOREIGN KEY(id) REFERENCES T2(id)); <3> 非空約束:屬性名 資料型別 NOT NULL
<4> 唯一性約束:屬性名 資料型別 UNIQUE
<5> 自動增長(主要用於為新紀錄生成唯一ID且一個表只有一個AUTO_INCREMENT約束並是主鍵的一部分其是任何整數型別):屬性名 資料型別 AUTO_INCREMENT
<6> 預設值:屬性名 資料型別 DEFAULT 預設值
(3)查看錶結構: <1> 表基本結構:DESCRIBE 表名;
<2> 表詳細結構:SHOW CREATE TABLE 表名; (4)修改表 <1> 修改表名:ALTER TABLE 舊錶名 RENAME [TO] 新表名; <2> 修改資料型別:ALTER TABLE 表名 MODIFY 屬性名 資料型別; <3> 修改欄位名:ALTER TABLE 表名 CHANGE 舊屬性名 新屬性名 新資料型別; <4> 增加欄位:ALTER TABLE 表名 ADD 屬性名1 資料型別 [完整性約束] [FIRST|AFTER 屬性名];
<5> 刪除欄位:ALTER TABLE 表名 DROP 屬性名;
<6> 修改儲存引擎:ALTER TABLE 表名 ENGINE=儲存引擎名
(5)刪除表
<1> 沒有關聯的普通表:DROP TABLE 表名;
<2> 有關聯的父表:先刪除關聯表外來鍵約束 ALTER TABLE 表名 DROP FOREIGN KEY 外來鍵名 再刪除表
5> 事務,事務是一個最小的、不可分割的工作單元,不論成功與否都作為一個整體進行工作,其具有Atomic(原子性),Consistent(一致性),Isolated(隔離性),Durable(永續性)
語法規則: // 開啟事務 START TRANSACTION;
// 提交事務 COMMIT;
// 回滾 ROLLBACK; 索引
用於快速查詢資料庫表中的資料 優點:提高檢索資料的速度 缺點:索引需要佔用物理空間,因此在增加、刪除、修改資料時會造成維護速度降低 1> 索引的設計原則 (1)選擇唯一性索引,可更快通過索引確定某條記錄
(2)為經常需要排序ORDER BY、分組GROUP BY和聯合操作UNION的欄位建立索引
(3)為常作為查詢條件的欄位建立索引
(4)限制索引的數目,索引太多需要的磁碟空間就越大,修改表示對索引的重構和更新會很麻煩
(5)儘量使用資料量少的索引,對CHAR(100)全文索引肯定會比CHAR(10)耗時多
(6)儘量使用字首來索引
(7)刪除不再使用或者很少使用的索引
2> 建立索引 建立表時建立索引,其最基本形式是 CREATE TABLE 表名(屬性名 資料型別 [完整性約束條件],屬性名 資料型別 [完整性約束條件]... 屬性名 資料型別 [UNIQUE|FULLTEXT|SPATIAL] INDEX|KEY [別名] (屬性名1 [(長度)] [ASC|DESC])) FULLTEXT是可選引數表示全文索引,SPATIAL是可選引數表示空間索引,INDEX和KEY指定那些欄位是索引二擇其一作用相同 (1)建立普通索引:如:CREATE TABLE T1(id INT,name VARCHAR(50),INDEX(id))
(2)建立唯一性索引:如:CREATE TABLE T1(id INT UNIQUE,name VARCHAR(50),INDEX(id ASC))
(3)建立全文索引:全文索引只建立在CHAR、VARCHAR或TEXT型別的欄位上,且只有MyISAM儲存支援全文索引 如:CREATE TABLE T1(id INT,name VARCHAR(50),FULLTEXT INDEX(name))
(4)建立單列索引:在單個欄位上的一部分建立索引只查詢前面若干索引 如:CREATE TABLE T1(id INT,name VARCHAR(50),INDEX(name(10)))
(5)建立多列索引:在表的多個欄位上建立一個索引 如:CREATE TABLE T1(id INT,name VARCHAR(50),INDEX(id,name))
注:只有在使用索引中的第一個欄位時才會觸發索引 (6)建立空間索引:
(7)在已存在的表上建立索引:CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名 ON 表名 (屬性名 [(長度)] [ASC|DESC])
(8)用ALTER TABLE語句來建立索引:ALTER TABLE 表名 ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名 ON 表名 (屬性名 [(長度)] [ASC|DESC])
如:ALTER TABLE Info_Pictures ADD INDEX pictures_index_userId(picturesUserId, picturesCreatetime ASC) 3> 刪除索引 基本形式是 DROP INDEX 索引名 ON 表名
檢視
檢視是一種虛擬的表由一個或多個表匯出,其可以從已存在的檢視基礎上定義,資料庫中只存放檢視的定義沒有存放檢視中的資料,資料依舊在原來的表中。使用檢視時會從原來的標中取出對應的資料,因此檢視中的資料依賴於原來的表中的資料,一旦表中的資料發生變化,顯示在檢視中的資料也會發生變化 1> 建立檢視 語法形式:CREATE [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW 檢視名 [(屬性清單)] AS SELECT 語句 [WITH [CASCADED|LOCAL] CHECK OPTION] ALGORITHM為可選引數表示檢視選擇的演算法其包括3個選項UNDEFINED(自動選所使用的演算法)、MERGE(使用檢視語句與檢視定義結合起來使得檢視定義的某一部分取代語句對應部分)、TEMPTABLE(將檢視的結果存入臨時表再使用零時表執行語句),WITH CHECK OPTION是可選引數表示更新檢視時要保證在該檢視的許可權範圍內 注:建立檢視時,最好加上WITH CHECK OPTION 和 CASCADED,這樣從檢視派生出來的新檢視後,更新新檢視需要考慮其父檢視的約束條件 (1)單表建立檢視:如:CREATE VIEW v1 AS SELECT * FROM t1;
(2)多表建立檢視:如:CREATE ALGORITHM=MERGE VIEW v1(name,age) AS SELECT name,age FROM t1,t2 WITH LOCLA CHECH OPTION;
2> 修改檢視
語法形式:CREATE OR REPLACE [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW 檢視名 [(屬性清單)] AS SELECT 語句 [WITH [CASCADED|LOCAL] CHECK OPTION]
或是使用ALERT語句 ALTER [ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}] VIEW 檢視名 [(屬性清單)] AS SELECT 語句 [WITH [CASCADED|LOCAL] CHECK OPTION] 注:只要有許可權,更新檢視中的資訊,對應的表中資料也將更新 無法更新檢視的情況 (1)檢視中包含SUN()、COUNT()、MAX()、MIN()等函式
(2)檢視中包含UNION、UNION ALL、DISTINCT、GROUP BY、HAVING
(3)常亮檢視
(4)檢視中包含SELECT子查詢
(5)由不可更新的試圖匯出的檢視
(6)建立檢視時,ALGORITHM為TEMPTABLE
3> 刪除檢視
語法形式:DROP VIEW [IF EXISTS] 檢視名 [RESTRICT|CASCADE]
觸發器
觸發器是由INSERT、UPDATE、DELETE語句觸發 1> 建立只有一個執行語句的觸發器,語法形式:CREATE TRIGGER 觸發器名 BEFORE|AFTER 觸發事件 ON 表名 FOR EACH ROW 執行語句; BEFORE指在觸發事件之前執行觸發語句,AFTER在觸發事件之後執行語句,觸發事件指觸發條件可以是INSERT、UPDATE、DELETE,表名指觸發事件操作的表的名稱,FOR EACH ROW表示任何一條記錄上的操作滿足觸發事件都會觸發該觸發器,執行語句指觸發器被觸發後執行的程式 如:CREATE TRIGGER trigger1 BEFORE INSERT ON t1 FOR EACH ROW INSERT INTO time VALUES(NOW());
2> 建立多個執行語句的觸發器,語法形式:CREATE TRIGGER 觸發器名 BEFORE|AFTER 觸發事件 ON 表名 FOR EACH ROW BEGIN 所有執行語句 END
注:1> 一般系統以“;”作為執行語句,在建立觸發器過程中需要用到“;”,可以使用DELIMITER語句防止多條執行語句結尾的“;”導致提前執行觸發器,如: DELIMITER
&& CREATE TRIGGER trigger1 AFTER DELETE ON t1 FOR EACH ROW BEGIN INSERT INTO t2(time) VALUES(NOW()); INSERT INTO t3(time) VALUES(NOW());
END
&&
DELIMITER;
2> 同一個表在相同觸發事件的相同觸發事件,只能建立一個觸發器,像是同一個表可建立INSERT事件的BEFORE和AFTER事件 3> 顯示觸發器,語法形式:SHOW TRIGGERS;
4> 觸發器的執行順序是BEFORE觸發器、表操作(INSERT、UPDATE和DELETE)和AFTER觸發器 5> 觸發器中不能包含START TRANSACTION、COMMIT、CLAA或ROLLBACK的關鍵詞,觸發器在執行過程中任何步驟出錯都會組織程式向下執行,對於普通表已更新過的記錄不能回滾,更新後的資料將繼續保持在表中 6> 刪除觸發器,語法形式:DROP TRIGGER 觸發器名; 查詢資料
1> 基本查詢語句,語法形式:SELECT 屬性列表 FROM 表名和檢視列表 [WHERE 條件表示式1] [GROUP BY 屬性名1 [HAVING 條件表示式2]] [ORDER BY 屬性名2 [ASC|DESC]]
(1)語法規則:[NOT] IN(元素1,元素2,...)
(2)語法規則:[NOT] BETWEEN 取值1 AND 取值2 如:SELECT * FROM t1 WHERE age BETWEEN 15 AND 25;
(3)語法規則:[NOT] LIKE '字串' “%”代表任意長度的字串,“_”代表單個字串
(4)語法規則:IS [NOT] NULL 如:SELECT * FROM t1 WHERE column1 IS NULL;
(5)AND 同時滿足多條查詢條件,OR 滿足其中一條查詢條件
(6)查詢結果不重複,語法規則:SELECT DISTINCT 屬性名 如:SELECT DISTINCT column1 FROM t1;
(7)語法規則:ORDER BY 屬性名 [ASC|DESC]
(8)分組查詢,語法規則:GROUP BY 屬性名 [HAVING 條件表示式] [WITH ROLLUP] WITH ROLLUP關鍵字會在所有記錄的最後加上一條記錄,記錄所有記錄的總和,GROUP BY關鍵字通常與幾何函式一起使用COUNT()統計記錄總數、SUM()計算欄位的值的綜合、AVG()計算欄位值的平均值、MAX()查詢欄位的最大值、MIN()查詢欄位的最小值、GROUP_CONCAT()將分組中指定欄位值都顯示出來,如:SELECT GROUP_CONCAT(name) FROM t1 GROUP BY sex; 返回的資料是 name1,name2,name3 注:1> {1,2,3}就是升序,{3,2,1}就是降序,預設是ASC 2> *是所有欄位 2> LIMIT限制查詢結果數量 (1)不指定初始化位置,從第一條記錄開始顯示指定條數記錄,語法規則:LIMIT 記錄數 如:SELECT * FROM t1 LIMIT 2;
(2)指定初始化位置,位置基於0,語法規則:LIMIT 初始位置,記錄數 如:SELECT * FROM t1 LIMIT 0,2; SELECT * FROM table LIMIT 5,10; // 檢索記錄行 6-15 SELECT * FROM table LIMIT 95,-1; // 為了檢索從某一個偏移量到記錄集的結束所有的記錄行,可以指定第二個引數為 -1:檢索記錄行 96-last SELECT * FROM table LIMIT 5; // 如果只給定一個引數,它表示返回最大的記錄行數目,換句話說,LIMIT n 等價於 LIMIT 0,n:檢索前 5 個記錄行 3> 連線查詢 (1)內連線查詢,如:SELECT a.name,b.name FROM t1,t2 WHERE t1.id=t2.id;
(2)外連結查詢,語法規則:SELECT 屬性名列表 FROM 表名1 LEFT|RIGHT JOIN 表名2 ON 表名1.屬性=表名2.屬性;
4> 子查詢 (1)帶IN關鍵字的子查詢,如:SELECT * FROM t2 WHERE column1 IN(SELECT column1 FROM t2)
(2)帶比較運算子的子查詢,如:SELECT * FROM t2 WHERE column1>=(SELECTcolumn1 FROM t2)
(3)帶EXISTS的子查詢,如:SELECT * FROM t2 WHERE EXISTS(SELECTcolumn1 FROM t2)
(4)帶ANY關鍵字的子查詢,ANY關鍵字表示滿足其中任一條件,如:SELECT * FROM t2 WHERE column1>=ANY(SELECTcolumn1 FROM t2)
(5)帶ALL關鍵字的子查詢,ALL關鍵字表示滿足所有條件,如:SELECT * FROM t2 WHERE column1>=ALL(SELECTcolumn1 FROM t2) 5> 合併查詢結果 語法規則:SELECT 語句1 UNION|UNION ALL SELECT 語句2 UNION|UNION ALL... 如:SELECT id FROM t1 UNION SELECT id FROM t2 注:UNION關鍵字會將所有查詢出的結果合併到一起,再去除所有相同記錄,而UNION ALL 則可能存在相同記錄 6> 位欄位取別名 語法規則:屬性名 [AS] 別名 7> 正則表示式查詢,語法規則:屬性名 REGEXP '匹配方式'
插入、更新與刪除資料
1> 插入資料 (1)不指定具體欄位名,語法規則:INSERT INTO 表名 VALUES(值1,值2...)
(2)指定具體欄位名,語法規則:INSERT INTO 表名(屬性1,屬性2...) VALUES(值1,值2...)
(3)同時插入多條資料,語法規則:INSERT INTO 表名[(屬性列表)] VALUES(值列表1),(值列表2)...
(4)將查詢結果插入到表中,語法規則:INSERT INTO 表名1(屬性列表1) SELECT 屬性列表2 FROM 表名2 WHERE 條件表示式;
2> 更新資料 語法規則:UPDATE 表名 SET 屬性1=值1,... WHERE 條件表示式
3> 刪除資料 語法規則:DELETE FROM 表名 [WHERE 條件表示式] 運算子
1> 算術運算子
如:SELECT a,a+10,a-5 FROM t1 2> 比較運算子
3> 邏輯運算子
4> 位運算子
函式
1> 數學函式
2> 字串函式
3> 日期時間函式
4> 條件判斷函式
(1)IF(expr,v1,v2)函式:如果表示式expr成立返回v1否則返回v2,如:SELECT id,IF(grade>=60,'PASS','FAIL') from t1;
(2)IFNULL(v1,v2)函式:v1不為空則返回v1否則返回v2
(3)CASE函式
<1> CASE WHEN expr1 THEN v1 [WHEN e2 THEN v2...] [ELSE vn] END CASE表示開始,END表示函式結束,expr1成立返回v1,依次類推,最後ELESE時返回vn 如:SELECT id,grade,CASE WHEN grade>60 THEN 'GOOD' WHEN grade=60 THEN 'PASS' ELSE 'FAIL' END level FROM t6; <2> CASE expr WHEN e1 THEN v1 [WHEN e2 THEN v2...] [ELSE vn] END 如果欄位expr等於e1返回v1依次類推
如:SELECT id,grade,CASE grad WHEN grade>60 THEN 'GOOD' WHEN grade=60 THEN 'PASS' ELSE 'FAIL' END level FROM t6;
5> 系統資訊函式
6> 加密函式
(1)PASSWORD(str):對字串加密 如:SELECT PASSWORD('abcde') (2)MD5(str):MD5對str加密 (3)ENCODE(str,pswd_str):使用字串pswd_str來加密字串str,加密結果是二進位制數,必須使用BLOB型別儲存
(4)DECODE(crypt_str,pswd_str):使用pswd_str來為crypt_str解密
7> 其它函式
(1)FORMAT(x,n):數字x進行格式化,將x保留小數點後n位 儲存過程和函式
儲存過程和函式是在資料庫中定義一些SQL語句的集合,然後直接呼叫這些儲存過程和函式來執行已經定義好的SQL語句。儲存過程可以避免開發人員重複的編寫相同的SQL語句。而且,儲存過程和函式是在MySQL伺服器中儲存和執行的,可以減少客戶端和伺服器端的傳輸資料 1> 建立儲存過程:CREATE PROCEDURE sp_name([proc_parameter[,...]]) [characteristic...] routine_body sp_name是儲存過程名稱 proc_parameter是儲存過程的引數列表每個引數有3個部分組成分別是輸入輸出型別、引數名稱和引數型別心事如:[IN|OUT|INOUT] param_name type characteristic是儲存過程的特性
注:系統預設指定CONTAINS SQL,表示使用SQL語句,如果沒有使用SQL,最好設定為NO SQL
routine_body是程式碼的內容,可以用BEGIN...END來標誌SQL程式碼的開始和結束
如:
DELIMITER
&&
CREATE PROCEDURE num_from_employee(IN emp_id INT,OUT count_num INT)
READS SQL DATA
BEGIN
SELECT COUNT(*) INTO count_num FROM employee WHERE d_id=emp_id;
END
&&
DELIMITER2> 建立儲存函式:CREATE FUNCTION sp_name([func_parameter[,....]]) RETURANS type [characteristic...] routine_body
如: DELIMITER && CREATE FUNCTION name_from_employee(emp_id INT) RETURNS VARCHAR(20)
BEGIN RETUEN (SELECT name FROM employee WHERE num=emp_id); END && DELIMITER
3> 變數使用 (1)定義變數,語法規則:DECLARE var_name[,...] type [DEFAULT value] DECLARE關鍵字用來宣告變數,var_name是變數名稱,type是變數型別,DEFAULT value是預設值沒有預設是NULL
如:DECLARE my_sql INT DEFAULT 10; (2)變數賦值,語法規則:SET var_name=expr[,var_name=expr]... 如:SET my_sql=30;
SELECT col_name[,...] INTO var_name[,...] FROM table_name WHERE condition 如:SELECT d_id INTO my_sql FROM employee WHERE id=2 5> 流程控制使用
(1)IF語句,基本語法形式:IF search_condition THEN statement_list
[ELSEIF search_condition THEN statement_list]... END IF 如:IF age>20 THEN SET @count=@count+1; ELSEIF age=20 THEN @count2=@count2+1; ELSE @count3=@count3+1; END IF; (2)CASE語句,可以實現比IF語句更復雜的條件判斷,語法形式:
CASE case_value WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list]...
[ELSE statement_list]
END CASE
或是 CASE WHEN search_value THEN statement_list
[WHEN search_value THEN statement_list]...
[ELSE statement_list]
END CASE 如:CASE age
WHEN 20 THEN SET @count1=@count1+1; ELSE SET @count2=@count2+1;
END CASE;
或是
CASE
WHEN age=20 THEN SET @count1=@count1+1; ELSE SET @count2=@count2+1;
END CASE; (3)LOOP語句,迴圈執行,必須使用LEAVE停止迴圈,語法形式:
[begin_label:]LOOP
statement_list END LOOP [end_label]
如:
add_num:LOOP
SET @count=@count+1; IF @count=100 THEN LEAVE ad_num;
END LOOP add_num;
(4)ITERATE語句:跳出本次迴圈,進入下一次迴圈,語法格式:ITERATE label
如:
add_num:LOOP
SET @count=@count+1;
IF @count=100 THEN LEAVE add_num;
ELSE IF MOD(@count,3)=0 THEN ITERATE add_num;
SELECT * FROM employee;
END LOOP add_num;
(4)REPEADT語句,滿足條件時跳出迴圈語句,語法格式:
[begin_label] REPEAT
statement_list
UNTIL search_condition
END REPEAT [end_label]
如: REPEAT
SET @count=@count+1; UNTIL @count=100; END REPEAT; (5)WHILE語句,當滿足條件執行迴圈內的語句,語法格式:
[begin_label:] WHILE search_condition DO
statement_list END WHILE [end_label]
如:
WHILE @count<100 DO
SET @count=@count+1;
END WHILE;
6> 呼叫儲存過程和函式
(1)呼叫儲存過程,系統執行儲存過程中的語句,然後將結果返回,基本語法:
CALL sp_name([parameter[,...]])
如:
// 建立儲存過程 DELIMITER &&
CASER PROCEDURE num_from_employee(IN emp_id,OUT count_num INT)
READS SQL DATA BEGIN
SELECT COUNT(*) INTO count_num FROM employee WHERE d_id=emp_id;
END &&
DELIMITER;
// 呼叫儲存過程
CALL num_from_employee(1002,@n);
// 查詢返回結果
SELECT @n;
(2)呼叫儲存過程,如:
// 建立儲存函式 DELIMITER &&
CREATE FUNCTION name_from_employee(emp_id INT)
RETURNS VARCHAR(20) BEGIN
RETURN (SELECT name FROM employee WHERE num=emp_id);
END&&
DELIMITER;
// 呼