
LINUX下磁碟IO效能監測分析
這兩天發現一臺測試用的伺服器經常負載很高,但cpu和記憶體消耗卻很少,很是奇怪,經過診斷髮現是由於大容量的測試資料導致高併發下的磁碟IO消耗比較大,由於快取是小檔案並且數量比較大,所以併發比較高的情況下Io消耗非常大。那怎樣才能快速的定位到併發高是由於磁碟io開銷大呢?
一、用 top 命令中的 資訊進行觀察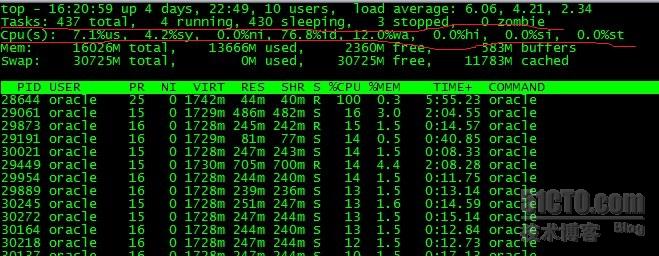
劃紅線的引數解釋如下:
Tasks: 437 total 程序總數
4 running 正在執行的程序數
430 sleeping 睡眠的程序數
3 stopped 停止的程序數
0 zombie 殭屍程序數
Cpu(s):
7.1% us 使用者空間佔用CPU百分比
4.2% sy 核心空間佔用CPU百分比
0.0% ni 使用者程序空間內改變過優先順序的程序佔用CPU百分比
76.8% id 空閒CPU百分比
12% wa 等待輸入輸出的CPU時間百分比
12% wa 的百分比可以大致的體現出當前等待輸入輸出的磁碟io請求過於頻繁。
為進一步分析,我們跟蹤關鍵程序定位程式
#strace -p 28644 (如圖示佔用CPU較高)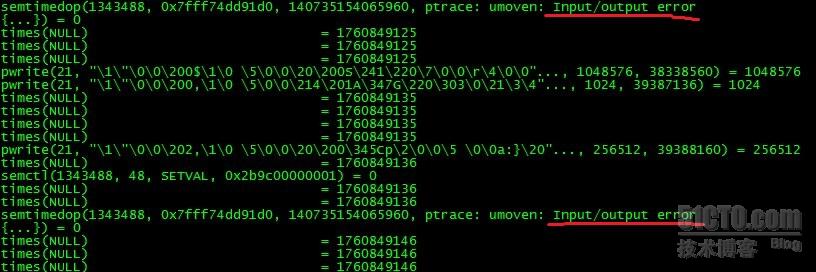
說明在多執行緒條件下,如果併發操作過於頻繁,semtimedop會呼叫失敗,Input/output 出錯。
進一步定位到程式 #ps -ef | grep 28644

可以知道是ora_lgwr_nms程式導致的讀寫開銷比較大。
二、利用IOSTAT命令觀察
磁碟的IO效能是衡量計算機總體效能的一個重要指標。Linux提供了iostat命令來獲卻磁碟輸入/輸出(即IO)統計資訊。
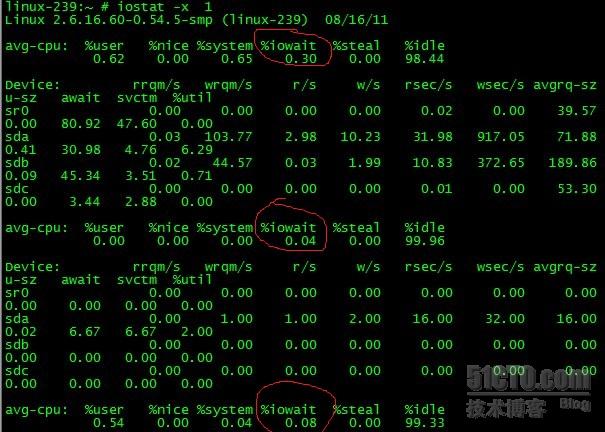
#iostat -x 1 統計完整的結果,每秒一次。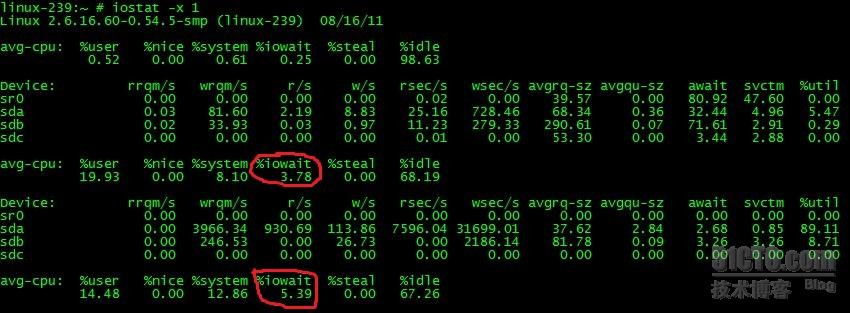
iowait的值比較大,說明讀寫頻繁。
#iostat -p 1統計各個分割槽的讀寫情況,每秒1次。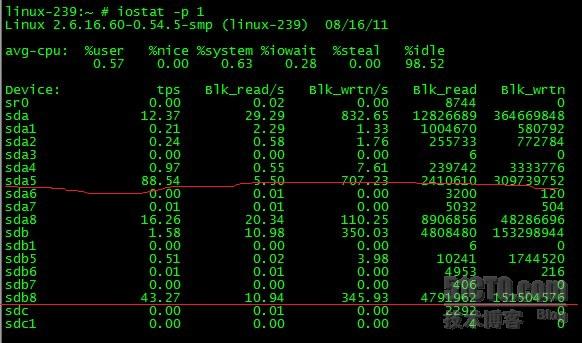
使用 #mount 命令,來對應查詢就知道sda5對應的/opt分割槽和sdb8對應的/data分割槽讀寫頻繁。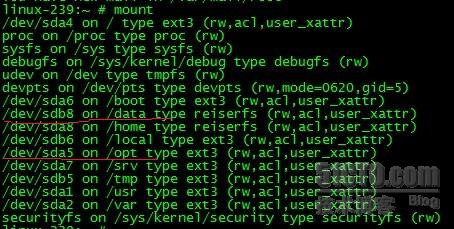
再定位到DATA分割槽,檢視資料庫歸檔情況,發現一分鐘內歸檔產生四個文件並且每個檔案有48M這麼大,寫入應該非常頻繁,導致磁碟IO開銷比較大。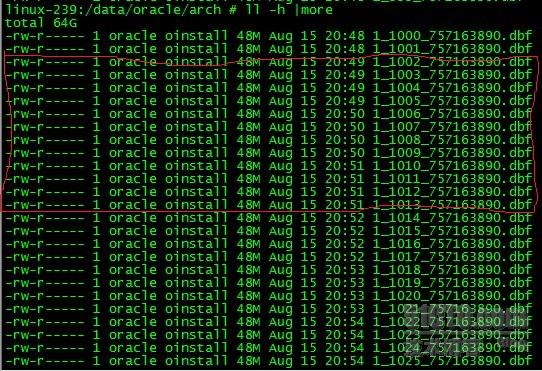
而OPT分割槽由於有FTP傳輸到導致磁碟開銷比較大。
分析定位完畢,針對相關問題調整FTP和資料庫歸檔,然後再看一下都正常了。
總結:TOP、IOSTAT都是比較常見的命令,通過基本命令的靈活應用來分析和定位問題是比較方便的,特別是基本命令的引數選擇和使用更是值得我們大家研究的。
補充:磁碟IOPS知識
傳統磁碟本質上一種機械裝置,如FC, SAS, SATA磁碟,轉速通常為5400/7200/10K/15K rpm不等。影響磁碟的關鍵因素是磁碟服務時間,即磁碟完成一個I/O請求所花費的時間,它由尋道時間、旋轉延遲和資料傳輸時間三部分構成。
尋道時間
旋轉延遲Trotation是指碟片旋轉將請求資料所在扇區移至讀寫磁頭下方所需要的時間。旋轉延遲取決於磁碟轉速,通常使用磁碟旋轉一週所需時間的1/2表示。比如,7200 rpm的磁碟平均旋轉延遲大約為60*1000/7200/2 = 4.17ms,而轉速為15000 rpm的磁碟其平均旋轉延遲約為2ms。
資料傳輸時間Ttransfer是指完成傳輸所請求的資料所需要的時間,它取決於資料傳輸率,其值等於資料大小除以資料傳輸率。目前IDE/ATA能達到133MB/s,SATA II可達到300MB/s的介面資料傳輸率,資料傳輸時間通常遠小於前兩部分時間。
因此,理論上可以計算出磁碟的最大IOPS,即IOPS = 1000 ms/ (Tseek + Troatation),忽略資料傳輸時間。假設磁碟平均物理尋道時間為3ms, 磁碟轉速為7200,10K,15K rpm,則磁碟IOPS理論最大值分別為,
IOPS = 1000 / (3 + 60000/7200/2) = 140
IOPS = 1000 / (3 + 60000/10000/2) = 167
IOPS = 1000 / (3 + 60000/15000/2) = 200
決定IOPS的主要取決與陣列的演算法,cache命中率,以及磁碟個數。陣列的演算法因為不同的陣列不同而不同.在raid5與raid10上,讀iops沒有差別,但是相同的業務,寫iops最終落在每塊磁碟上是有差別的,如果達到了每塊磁碟的寫的i0ps限制,效能會受到影響。對於raid5來說每一個寫實際發生了4個io,而raid10只發生了2次io,所以raid10比raid5在寫上要快一些。