
C#語法:正則表示式 --Trim()的實現
正則表示式匹配輸入文字的模式
常用元字元
| 程式碼 | 說明 |
| . | 匹配除換行符以外的任意字元。 |
| \w | 匹配字母或數字或下劃線或漢字。 |
| \s | 匹配任意的空白符。 |
| \d | 匹配數字。 |
| \b | 匹配單詞的開始或結束。 |
| [ck] | 匹配包含括號內元素的字元 |
| ^ | 匹配行的開始。 |
| $ | 匹配行的結束。 |
| \ | 對下一個字元轉義。比如$是個特殊的字元。要匹配$的話就得用\$ |
| | | 分支條件,如:x|y匹配 x 或 y。 |
反義元字元
| 程式碼 | 說明 |
| \W | 匹配任意不是字母,數字,下劃線,漢字的字元。 |
| \S | 匹配任意不是空白符的字元。等價於 [^ \f\n\r\t\v]。 |
| \D | 匹配任意非數字的字元。等價於 [^0-9]。 |
| \B | 匹配不是單詞開頭或結束的位置。 |
| [^CK] | 匹配除了CK以外的任意字元。 |
特殊元字元
| 程式碼 | 說明 |
| \f | 匹配一個換頁符。等價於 \x0c 和 \cL。 |
| \n | 匹配一個換行符。等價於 \x0a 和 \cJ。 |
| \r | 匹配一個回車符。等價於 \x0d 和 \cM。 |
| \t | 匹配一個製表符。等價於 \x09 和 \cI。 |
| \v | 匹配一個垂直製表符。等價於 \x0b 和 \cK。 |
限定符
| 程式碼 | 說明 |
| * | 匹配前面的子表示式零次或多次。 |
| + | 匹配前面的子表示式一次或多次。 |
| ? | 匹配前面的子表示式零次或一次。 |
| {n} | n 是一個非負整數。匹配確定的 n 次。 |
| {n,} | n 是一個非負整數。至少匹配n 次。 |
| {n,m} | m 和 n 均為非負整數,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
懶惰限定符
| 程式碼 | 說明 |
| *? |
重複任意次,但儘可能少重複。 如 "acbacb" 正則 "a.*?b" 只會取到第一個"acb" 原本可以全部取到但加了限定符後,只會匹配儘可能少的字元 ,而"acbacb"最少字元的結果就是"acb" 。 |
| +? | 重複1次或更多次,但儘可能少重複。與上面一樣,只是至少要重複1次。 |
| ?? |
重複0次或1次,但儘可能少重複。 如 "aaacb" 正則 "a.??b" 只會取到最後的三個字元"acb"。 |
| {n,m}? |
重複n到m次,但儘可能少重複。 如 "aaaaaaaa" 正則 "a{0,m}" 因為最少是0次所以取到結果為空。 |
| {n,}? |
重複n次以上,但儘可能少重複。 如 "aaaaaaa" 正則 "a{1,}" 最少是1次所以取到結果為 "a"。 |
捕獲分組
| 程式碼 | 說明 |
| (exp) | 匹配exp,並捕獲文字到自動命名的組裡。 |
| (?<name>exp) | 匹配exp,並捕獲文字到名稱為name的組裡。 |
| (?:exp) | 匹配exp,不捕獲匹配的文字,也不給此分組分配組號以下為零寬斷言。 |
| (?=exp) |
匹配exp前面的位置。 如 "How are you doing" 正則"(?<txt>.+(?=ing))" 這裡取ing前所有的字元,並定義了一個捕獲分組名字為 "txt" 而"txt"這個組裡的值為"How are you do"; |
| (?<=exp) |
匹配exp後面的位置。 如 "How are you doing" 正則"(?<txt>(?<=How).+)" 這裡取"How"之後所有的字元,並定義了一個捕獲分組名字為 "txt" 而"txt"這個組裡的值為" are you doing"; |
| (?!exp) |
匹配後面跟的不是exp的位置。 如 "123abc" 正則 "\d{3}(?!\d)"匹配3位數字後非數字的結果 |
| (?<!exp) |
匹配前面不是exp的位置。 如 "abc123 " 正則 "(?<![0-9])123" 匹配"123"前面是非數字的結果也可寫成"(?!<\d)123" |
我們先用例子來說明吧。
在C#中,用正則需要引入名稱空間 System.Text.RegularExpressions
private static string Trim(string str)
{
return System.Text.RegularExpressions.Regex.Match(str, @"\S.*\S|\S").ToString();
}Match():搜尋第一個匹配項。
這段程式碼是用一句話用正則表示式來實現刪除字串兩端空白。其中 @ 符號作用防止轉義。對照上面表,'\S'為匹配非空格字元, ' . '為任意字元,和 '*'搭配,'.*'則為任意字串。實現此功能的思路就是:當字串字母個數大於1時第一個字元為非空白符,最後一個字元為非空白符,中間為任意字串。當字母個數為1時,直接獲取那個字母就行。
又例如:
var arrstr = Regex.Matches(" hahha90687h987f87 ", @"\S[^0-9]*\S");
Console.WriteLine(@" hahha90687h987f87 :");
foreach (var s in arrstr)
{
Console.WriteLine(s);
}輸出結果
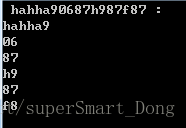
[^0-9]:是匹配不是0到9的字元,和\D是一樣的效果(注意是 '-'號而不是'~'號)
又例如:
var arrstr = Regex.Matches("hello.txt world.doc ", @".*[.]txt");
Console.WriteLine(@"hello.txt world.doc:");
foreach (var s in arrstr)
{
Console.WriteLine(s);
}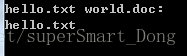
[.]:代表匹配方括號內的'.'字元