
28-TCP 協議(超時與重傳)
TCP 超時與重傳應該是 TCP 最複雜的部分之一了。Windows 和 Linux 對這部分的實現還有所不同,但是演算法基本上還是差不多的。
超時重傳是 TCP 保證可靠傳輸的基礎。當 TCP 在傳送資料時,資料和 ack 都有可能會丟失,因此,TCP 通過在傳送時設定一個定時器來解決這種問題。如果定時器溢位還沒有收到確認,它就重傳資料。
無論是 Windows 還是 Linux,關鍵之處就在於超時和重傳的策略,需要考慮兩方面:
- 超時時間設定
- 重傳的頻率(次數)
目前來說,在 Linux 較高的核心版本中,比如 3.15 中,已經有了至少 9 個定時器:超時重傳定時器,持續定時器,ER延遲定時器,PTO定時器,ACK延遲定時器,SYNACK定時器,保活定時器,FIN_WAIT2定時器,TIME_WAIT定時器。
這實在是太多了,對初學者來說,我們重點掌握以下 4 個:
- 超時重傳定時器(retransmit)
- 持續定時器(persist)
- 保活定時器(keepalive,這和 HTTP 協議中的 keepalive 不是同一個概念)
- TIME_WAIT 定時器
1. 一個超時重傳的例子
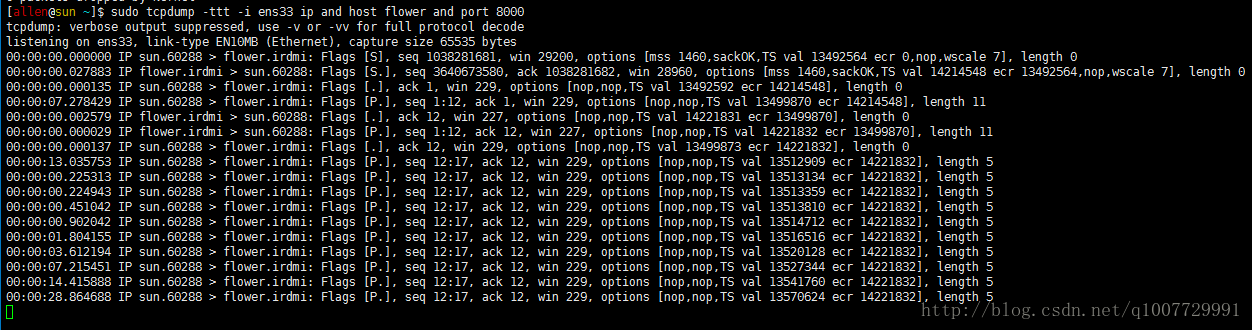
圖1 超時重傳
本實驗所使用的程式路徑為 unp/program/echo/processzombie/echo.cc,你可以直接使用 make 命令進行編譯。
- 伺服器端啟動方式
$ ./echo -s -h flower // 或者你可以這樣寫 ./echo -s -h 192.168.166.47 - 客戶端啟動方式
$ ./echo -h flower // 或者你可以寫 ./echo -h 192.168.166.47當客戶端連線成功後,傳送一行資料'helloworld',對方回射回來,一切正常,接下來,將伺服器主機 flower 斷網,然後客戶端再次傳送資料 'hehe'。
大約等等了 16 分鐘左右(圖2),客戶端返回一個錯誤:No route to host.
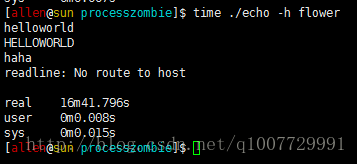
圖2 客戶端等待約 16 分鐘後返回錯誤
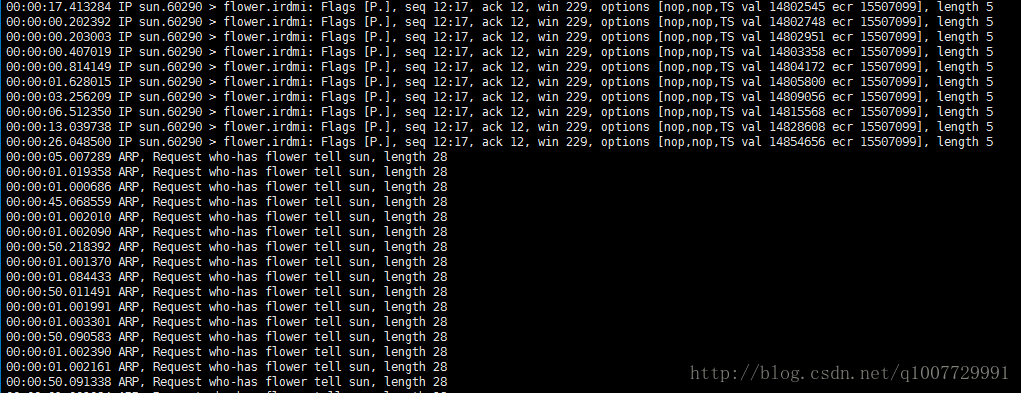
圖3 第 9 次重傳後,主機親自發送 ARP 協議詢問對方 MAC 地址
做這個實驗時,兩個主機都屬於同一個網段,有機會,我會將兩個主機放到不同的網段再試一次,看看結果是否還是這樣。因為在同一個網段,主機 sun 傳送了
實驗反映的現象已經和 《TCP/IP 詳解卷1:協議》(後面簡稱《詳解》)不再一致。
《詳解》中的第 21 章的例子(圖 21-1),是在經歷了 12 次重傳後放棄(約 9 分鐘),向對方傳送 RST 段。
《詳解》這本書由 W.Richard Stevens(1951-1999) 在 1993 年編寫,時隔 24 年,TCP/IP 協議早已經歷了無數次的演化,這和書上描述的現象不一致太正常了。然而,Stevens 先生不幸在 1999 年去逝(據說是攀巖失足?),這是電腦科學界和教育界最重大的損失。
雖然超時重傳演算法今非昔比,但是如果直接拿到現在所使用的演算法來講解,初學者也會因為太複雜而放棄學習,所以,還是按照 Stevens 先生在《詳解》敘述的演算法來學習吧!
2. 往返時間(RTT)
超時重傳時間(Retransmission TimeOut, RTO)要怎麼設定呢?
資料包過去,到 ack 返回,這個時間一般約等於 RTT 時間,如果一個 RTT 時間內沒有收到 ack,很可能對方就沒有收到資料,或者回送的 ack 丟失。
所以,最直觀的想法是,RTO 應該比 RTT 稍稍大一點。
比如:
當然,這只是我們自己臆想的公式,說不定,TCP 一開始創造出來的時候,RTO 真的是這麼算的呢?
2.1 RTT 測量
可是,在公式中,RTT 是如何測量呢?在 TCP 中,每一次資料包傳送過去到接收到對方的 ack 這個時間差,就會被 TCP 記錄,然後儲存到一個變數
在區域網中,我們的網路一般是很穩定的,每次重新計算一個 RTT,基本上變化不太大,但是在廣域網中,網路就會變得異常複雜,這一次的 RTT 為 100ms,說不定下一次就變 800 ms 了,這時候,採用實時計算的 RTT 就會不合理,在 RFC 中,使用了加權的 RTT。它的公式如下:
RFC 2988 建議
舉個例子,當前
2.2 Δt 怎麼定義
在前面,我們臆想了一個公式:
現在我們將其更新為
因此,按照上面的定義,
實際上,
RFC 推薦
2.3 指數退避
假設在某一次傳送資料的時候,資料丟失了,根據前面的公式,我們計算出了一個 RTO 值。如果和重傳後,還是沒有等到對方的 ack,那麼 RTO 的值就會翻倍。只要重傳的的資料沒有 ack,那麼 RTO 就會一直翻倍。
則第 n 次重傳的
2.3 Karn 演算法
假設一個分組被髮送,經過若干次和重傳後,收到了對方的 ack,則新的 RTT 如何計算呢?實際上,我們根本沒有辦法知道這個 ack 是對哪一次重傳資料的確認,因此,Karn 演算法規定:此時不更新
如果下一次再發生重傳,使用退避後的 RTO 的值。
3. 回到圖 1
在圖 1 中,我們發現,第一次重傳的
另一方面,如果我們按照前面的
#define TCP_RTO_MAX ((unsigned)(120*HZ)) // 120秒
#define TCP_RTO_MIN ((unsigned)(HZ/5)) // 0.2s另一方面,為什麼 Linux 中的 TCP 重傳 8 次後就在那停住,還得去看核心到底是怎麼實現的了。相信大家在掌握了基本的 TCP 超時原理後,一定會找出這個答案的。
4. 總結
- 理解超時重傳時間如何計算