
深度學習中解決過擬合的方法
1. 正則化(regularization)
正則化是指修改學習演算法,使其降低泛化誤差而非訓練誤差。
1) L2正則化,也稱權重衰減(weight decay),正則項為
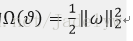
加入正則化後,總的目標函式為:
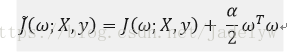
求其偏導:
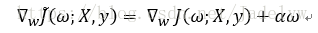
梯度下降更新權重:
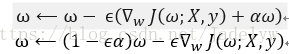
所以,加入權重衰減後會引起學習規則的修改,即在執行梯度更新之前先收縮權重向量。
過擬合,就是擬合函式需要考慮每一個點,最終形成的擬合函式波動過大,在某些小區間內,函式值的變化很劇烈,意味著函式的導數值的絕對值很大,所以相對來書權重係數很大。而L2正則化通過約束引數使其不要太大,所以在一定程度上緩解過擬合現象。
Pytorch中常用優化演算法為Adam,其中有權重衰減項,預設值為0, torch.optim.Adam(params, lr=0.001,betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
2) L1正則化,正則項為
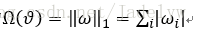
總的目標函式:
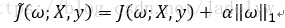
求其偏導:

代表各個元素的正負號
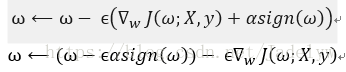
可以看到L1正則化並沒有收縮權重向量,當為正時,更新後的變小,當為負時,更新後的變大,因此它的效果就是讓w往0靠,使網路中的權重儘可能為0,也就相當於減小了網路複雜度,防止過擬合,L1的主要作用是產生稀疏模型,進行特徵選擇。
2. 資料增強(data augmention)
資料增強簡單的方法有影象水平翻轉(Horizontal Flip)、隨機摳取(random crops)、旋轉(rotating)、平移,新增噪聲。
Pytorch中對應的函式分別為:
torchvision.transforms.RandomHorizontalFlip(p=0.5)
torchvision.transforms.RandomCrop(size,padding=0, pad_if_needed=False)
torchvision.transforms.RandomRotation(degrees,resample=False, expand=False, center=None)
3. 隨機失活(Dropout)
Dropout是指在網路的訓練過程中,隨機使某些神經元失活,即隨機丟棄某些神經元。因為神經元是隨機失活的,所以每個mini-batch對應的網路會較大概率不同。Dropout一般用在全連線層的比較多,也可以用在中間層中的卷積層。一般預設為隨機失活概率p=0.5,
為什麼Dropout能防止過擬合?分為兩種觀點:1)類似於整合的方法,即訓練多個模型做組合,對於一個N節點的神經網路,加入Dropout後且當p=0.5時,就可以看作是個模型的集合了。2)直觀上看dropout是一種組合模型,實際上,是在一個神經網路中進行的,最後只訓練出一套模型引數,所以dropout可以解釋為,它強迫一個神經元和隨機挑選出來的其他神經元共同工作,達到更好的效果,消除減弱神經元節點間的聯合適應性,增強泛化能力。
Dropout在網路測試的時候神經元會產生方差偏移。
4. 批規範化(batch normalization)
1) 為什麼要歸一化?(泛化能力和訓練速度)
神經網路學習過程的本質就是學習資料的分佈,一旦訓練資料和測試資料的分佈不同,那麼網路的泛化能力就會很低;另一方面一旦每個batch 的訓練資料的分佈不同,網路就會學習不同的分佈,這樣就會大大降低網路的訓練效率。
2) 為什麼要Batch Normalization?
假設網路的輸入資料已經歸一化,但隨著網路引數的調整,網路各層的輸出資料即下一層的輸入資料則不斷變化,那麼各層的訓練就需要不斷改變以適應這種新的資料的分佈,從而造成訓練困難,難以擬合的問題。
BN演算法通過對每一層的輸入進行歸一化,保證每一層的輸入資料是穩定的,從而達到加速訓練的目的。
3) BN演算法
(1) 對輸入資料進行歸一化處理,歸一化為均值為0,方差為1的分佈

(2) 當對每一層的資料進行歸一化操作以後,有一個問題就是每層的資料分佈是固定的,這樣與網路所學習的特徵就不一致了,破壞了現有的學習到的特徵。所以加入兩個可學習變數去還原學習到的特徵。
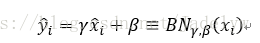
總的來說就是先求該層輸入的歸一化,然後學習引數去還原資料的輸入。
5. Bagging和其他整合方法
Bagging是通過結合幾個模型降低泛化誤差的技術,主要想法是分別訓練幾個不同的模型,然後讓所有模型表決測試樣例的輸出,模型平均奏效的原因是不同的模型通常不會在測試集上產生完全相同的誤差。
Bagging具體的操作是對原始資料集進行有放回的隨機抽樣,得到若干個與原資料集相同大小的新資料集的一種技術。在得到k個數據集後,最簡單的方法就是用模型某型分別作用於k個數據集,從而得到k個分類器,最後對k個分類器的分類結果進行表決得到最終的結果。
Boosting方法通過改變訓練樣本的權重,序列訓練多個分類器,並將這些分類器進行線性組合來構建強分類器。其具體的方法表現為:boosting構建分類器的過程中,每個新分類器都是根據已訓練出的分類器的效能來進行訓練的,即將被已有分類器錯分的那些資料的權重增大,而被正確分類的資料權重減小。最終在訓練得到m個分類器後,依據各分類器的分類效能給予相應的權重,並組合得到最終的分類器。
兩者的不同在於:1)訓練例項構建:Bagging為隨機重抽樣,Boosting根據已訓練出的分類器效能調整權重;2)子分類器構建: Bagging基於重抽樣的資料集構建,相互獨立,Boosting根據權重調整後的資料集構建,序列,相互依賴;
3)產生最終分類器:Bagging多數表決的投票法,Boosting權重依賴子分類器效能的加權組合。
6. 提前終止
過擬合的現象就是訓練誤差越來越小,而測試誤差與訓練誤差的間距越來越大,即測試誤差先從大變小,然後有從小變大,在某一臨界點出,達到最佳的測試誤差。而這個臨界點就由驗證集的測試誤差來確定。
在訓練模型的過程中,每迭代一定的次數就求取驗證集的測試誤差,如果每次驗證集的誤差有所改善,就儲存模型引數;當驗證集的誤差在事先制定的允許次數內沒有進一步的改善,就終止演算法,最終返回模型引數。
7. 微調(fine-tuning)
微調策略可以看作是遷移學習中的一種方法,它主要是通過在規模比較大的資料集上訓練的模型作為小資料集上的模型的初,然後在小資料集上進行訓練。微調的方式有多種,比如只訓練softmax層,訓練中間層+softmax層,訓練所有層。
總結,模型過擬合說到底還是因為資料跟模型的引數不匹配,所以防止模型過擬合的方法大概可以分為四大類:資料方面、模型方面、損失函式、訓練技巧方面。
1) 資料方面:準備大量的資料,還可以用資料增強的方式產生大量資料;
2) 模型方面:(1)設計合適的模型,(2)選擇預訓練模型進行微調;(3)在模型的中間使用BN層;(4)在模型的fc層處使用dropout;
3) 損失函式方面:通過在損失函式上新增正則項,要控制w的快速衰減,所以有L1、L2正則的方法;
4) 訓練技巧方面:(1)因為在訓練時,訓練誤差是一直減小的,而測試誤差是先減小再增大,所以在合適的時間(測試誤差最小)停止訓練;(2)bagging和其他整合方法
Bagging和Boosting參考網址:
Batch Normalization參考網址:
BN和Dropout聯合使用參考網址: