
rabbitMQ、activeMQ、zeroMQ、Kafka、Redis 的比較
Kafka作為時下最流行的開源訊息系統,被廣泛地應用在資料緩衝、非同步通訊、彙集日誌、系統解耦等方面。相比較於RocketMQ等其他常見訊息系統,Kafka在保障了大部分功能特性的同時,還提供了超一流的讀寫效能。
-
Topic:用於劃分Message的邏輯概念,一個Topic可以分佈在多個Broker上。
-
Partition:是Kafka中橫向擴充套件和一切並行化的基礎,每個Topic都至少被切分為1個Partition。
-
Offset:訊息在Partition中的編號,編號順序不跨Partition。
-
Consumer:用於從Broker中取出/消費Message。
-
Producer:用於往Broker中傳送/生產Message。
-
Replication:Kafka支援以Partition為單位對Message進行冗餘備份,每個Partition都可以配置至少1個Replication(當僅1個Replication時即僅該Partition本身)。
-
Leader:每個Replication集合中的Partition都會選出一個唯一的Leader,所有的讀寫請求都由Leader處理。其他Replicas從Leader處把資料更新同步到本地,過程類似大家熟悉的MySQL中的Binlog同步。
-
Broker:Kafka中使用Broker來接受Producer和Consumer的請求,並把Message持久化到本地磁碟。每個Cluster當中會選舉出一個Broker來擔任Controller,負責處理Partition的Leader選舉,協調Partition遷移等工作。
-
ISR(In-Sync Replica):是Replicas的一個子集,表示目前Alive且與Leader能夠“Catch-up”的Replicas集合。由於讀寫都是首先落到Leader上,所以一般來說通過同步機制從Leader上拉取資料的Replica都會和Leader有一些延遲(包括了延遲時間和延遲條數兩個維度),任意一個超過閾值都會把該Replica踢出ISR。每個Partition都有它自己獨立的ISR。
****************************************************
****************************************************
Kafka是一種分散式的,基於釋出/訂閱的訊息系統。主要設計目標如下:
以時間複雜度為O(1)的方式提供訊息持久化能力,即使對TB級以上資料也能保證常數時間複雜度的訪問效能。
高吞吐率。即使在非常廉價的商用機器上也能做到單機支援每秒100K條以上訊息的傳輸。
支援Kafka Server間的訊息分割槽,及分散式消費,同時保證每個Partition內的訊息順序傳輸。
同時支援離線資料處理和實時資料處理。
Scale out:支援線上水平擴充套件。
RabbitMQ
RabbitMQ是使用Erlang編寫的一個開源的訊息佇列,本身支援很多的協議:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量級,更適合於企業級的開發。同時實現了Broker構架,這意味著訊息在傳送給客戶端時先在中心佇列排隊。對路由,負載均衡或者資料持久化都有很好的支援。
Redis
Redis是一個基於Key-Value對的NoSQL資料庫,開發維護很活躍。雖然它是一個Key-Value資料庫儲存系統,但它本身支援MQ功能,所以完全可以當做一個輕量級的佇列服務來使用。對於RabbitMQ和Redis的入隊和出隊操作,各執行100萬次,每10萬次記錄一次執行時間。測試資料分為128Bytes、512Bytes、1K和10K四個不同大小的資料。實驗表明:入隊時,當資料比較小時Redis的效能要高於RabbitMQ,而如果資料大小超過了10K,Redis則慢的無法忍受;出隊時,無論資料大小,Redis都表現出非常好的效能,而RabbitMQ的出隊效能則遠低於Redis。
ZeroMQ
ZeroMQ號稱最快的訊息佇列系統,尤其針對大吞吐量的需求場景。ZeroMQ能夠實現RabbitMQ不擅長的高階/複雜的佇列,但是開發人員需要自己組合多種技術框架,技術上的複雜度是對這MQ能夠應用成功的挑戰。ZeroMQ具有一個獨特的非中介軟體的模式,你不需要安裝和執行一個訊息伺服器或中介軟體,因為你的應用程式將扮演這個伺服器角色。你只需要簡單的引用ZeroMQ程式庫,可以使用NuGet安裝,然後你就可以愉快的在應用程式之間傳送訊息了。但是ZeroMQ僅提供非永續性的佇列,也就是說如果宕機,資料將會丟失。其中,Twitter的Storm
0.9.0以前的版本中預設使用ZeroMQ作為資料流的傳輸(Storm從0.9版本開始同時支援ZeroMQ和Netty作為傳輸模組)。
ActiveMQ
ActiveMQ是Apache下的一個子專案。 類似於ZeroMQ,它能夠以代理人和點對點的技術實現佇列。同時類似於RabbitMQ,它少量程式碼就可以高效地實現高階應用場景。
Kafka/Jafka
Kafka是Apache下的一個子專案,是一個高效能跨語言分散式釋出/訂閱訊息佇列系統,而Jafka是在Kafka之上孵化而來的,即Kafka的一個升級版。具有以下特性:快速持久化,可以在O(1)的系統開銷下進行訊息持久化;高吞吐,在一臺普通的伺服器上既可以達到10W/s的吞吐速率;完全的分散式系統,Broker、Producer、Consumer都原生自動支援分散式,自動實現負載均衡;支援Hadoop資料並行載入,對於像Hadoop的一樣的日誌資料和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka通過Hadoop的並行載入機制統一了線上和離線的訊息處理。Apache
Kafka相對於ActiveMQ是一個非常輕量級的訊息系統,除了效能非常好之外,還是一個工作良好的分散式系統。
****************************************************
****************************************************
什麼是Kafka?
引用官方原文: “ Kafka is a distributed, partitioned, replicated commit log service. ”
它提供了一個非常特殊的訊息機制,不同於傳統的mq。
官網:https://kafka.apache.org
它與傳統的mq區別?
- 更快!單機上萬TPS
- 傳統的MQ,訊息被消化掉後會被mq刪除,而kafka中訊息被消化後不會被刪除,而是到配置的expire時間後,才刪除
- 傳統的MQ,訊息的Offset是由MQ維護,而kafka中訊息的Offset是由客戶端自己維護
- 分散式,把寫入壓力均攤到各個節點。可以通過增加節點降低壓力
基本術語
為方便理解,我用對比傳統MQ的方式闡述這些基本術語。
Producer Consumer這兩個與傳統的MQ一樣,不解釋了
TopicKafka中的topic其實對應傳統MQ的channel,即訊息管道,例如同一業務用同一根管道
Broker叢集中的KafkaServer,用來提供Partition服務
Partition假如說傳統的MQ,傳輸訊息的通道(channel)是一條雙車道公路,那麼Kafka中,Topic就是一個N車道的高速公路。每個車道都可以行車,而每個車道就是Partition。
- 一個Topic中可以有一個或多個partition。
- 一個Broker上可以跑一個或多個Partition。叢集中儘量保證partition的均勻分佈,例如定義了一個有3個partition的topic,而只有兩個broker,那麼一個broker上跑兩個partition,而另一個是1個。但是如果有3個broker,必然是3個broker上各跑一個partition。
- Partition中嚴格按照訊息進入的順序排序
- 一個從Producer傳送來的訊息,只會進入Topic的某一個Partition(除非特殊實現Producer要求訊息進入所有Partition)
- Consumer可以自己決定從哪個Partition讀取資料
單個Partition中的訊息的順序ID,例如第一個進入的Offset為0,第二個為1,以此類推。傳統的MQ,Offset是由MQ自己維護,而kafka是由client維護
ReplicaKafka從0.8版本開始,支援訊息的HA,通過訊息複製的方式。在建立時,我們可以指定一個topic有幾個partition,以及每個partition有幾個複製。複製的過程有同步和非同步兩種,根據效能需要選取。 正常情況下,寫和讀都是訪問leader,只有當leader掛掉或者手動要求重新選舉,kafka會從幾個複製中選舉新的leader。
Kafka會統計replica與leader的同步情況。當一個replica與leader資料相差不大,會被認為是一個"in-sync" replica。只有"in-sync" replica才有資格參與重新選舉。
ConsumerGroup一個或多個Consumer構成一個ConsumerGroup,一個訊息應該只能被同一個ConsumerGroup中的一個Consumer消化掉,但是可以同時傳送到不同ConsumerGroup。
通常的做法,一個Consumer去對應一個Partition。
傳統MQ中有queuing(訊息)和publish-subscribe(訂閱)模式,Kafka中也支援:
- 當所有Consumer具有相同的ConsumerGroup時,該ConsumerGroup中只有一個Consumer能收到訊息,就是 queuing 模式
- 當所有Consumer具有不同的ConsumerGroup時,每個ConsumerGroup會收到相同的訊息,就是 publish-subscribe 模式
基本互動原理
每個Topic被建立後,在zookeeper上存放有其metadata,包含其分割槽資訊、replica資訊、LogAndOffset等
預設路徑/brokers/topics/<topic_id>/partitions/<partition_index>/state
Producer可以通過zookeeper獲得topic的broker資訊,從而得知需要往哪寫資料。
Consumer也從zookeeper上獲得該資訊,從而得知要監聽哪個partition。
基本CLI操作
1. 建立Topic./kafka-create-topic.sh --zookeeper 10.1.110.21:2181 --replica 2 --partition 3 --topic test
2. 檢視Topic資訊
./kafka-list-topic.sh --topic test --zookeeper 10.1.110.24:2181
3. 增加Partition
./kafka-add-partitions.sh --partition 4 --topic test --zookeeper 10.1.110.24:2181
建立一個Producer
Kafka提供了java api,Producer特別的簡單,舉傳輸byte[] 為例
Properties p = new Properties();
props.put("metadata.broker.list", "10.1.110.21:9092");
ProducerConfig config = new ProducerConfig(props);
Producer producer = new Producer<String, byte[]>(config);
producer.send(byte[] msg);
更具體的參見:https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+Producer+Example
建立一個Consumer
Kafka提供了兩種java的Consumer API:High Level Consumer和Simple Consumer
看上去前者似乎要更牛B一點,事實上,前者做了更多的封裝,比後者要Simple的多……
具體例子我就不寫了,參見
****************************************************
****************************************************
如何保證kafka的高容錯性?
- producer不使用批量介面,並採用同步模型持久化訊息。
- consumer不採用批量化,每消費一次就更新offset
| ActiveMq | RabbitMq | Kafka | |
|---|---|---|---|
| producer容錯,是否會丟資料 | 有ack模型,也有事務模型,保證至少不會丟資料。ack模型可能會有重複訊息,事務模型則保證完全一致 | 批量形式下,可能會丟資料。 非批量形式下, 1. 使用同步模式,可能會有重複資料。 2. 非同步模式,則可能會丟資料。 | |
| consumer容錯,是否會丟資料 | 有ack模型,資料不會丟,但可能會重複處理資料。 | 批量形式下,可能會丟資料。非批量形式下,可能會重複處理資料。(ZK寫offset是非同步的) | |
| 架構模型 | 基於JMS協議 | 基於AMQP模型,比較成熟,但更新超慢。RabbitMQ的broker由Exchange,Binding,queue組成,其中exchange和binding組成了訊息的路由鍵;客戶端Producer通過連線channel和server進行通訊,Consumer從queue獲取訊息進行消費(長連線,queue有訊息會推送到consumer端,consumer迴圈從輸入流讀取資料)。rabbitMQ以broker為中心;有訊息的確認機制 | producer,broker,consumer,以consumer為中心,訊息的消費資訊儲存的客戶端consumer上,consumer根據消費的點,從broker上批量pull資料;無訊息確認機制。 |
| 吞吐量 | rabbitMQ在吞吐量方面稍遜於kafka,他們的出發點不一樣,rabbitMQ支援對訊息的可靠的傳遞,支援事務,不支援批量的操作;基於儲存的可靠性的要求儲存可以採用記憶體或者硬碟。 | kafka具有高的吞吐量,內部採用訊息的批量處理,zero-copy機制,資料的儲存和獲取是本地磁碟順序批量操作,具有O(1)的複雜度,訊息處理的效率很高 | |
| 可用性 | rabbitMQ支援miror的queue,主queue失效,miror queue接管 | kafka的broker支援主備模式 | |
| 叢集負載均衡 | rabbitMQ的負載均衡需要單獨的loadbalancer進行支援 | kafka採用zookeeper對叢集中的broker、consumer進行管理,可以註冊topic到zookeeper上;通過zookeeper的協調機制,producer儲存對應topic的broker資訊,可以隨機或者輪詢傳送到broker上;並且producer可以基於語義指定分片,訊息傳送到broker的某分片上 |
****************************************************
****************************************************
MQ框架非常之多,比較流行的有RabbitMq、ActiveMq、ZeroMq、kafka。這幾種MQ到底應該選擇哪個?要根據自己專案的業務場景和需求。下面我列出這些MQ之間的對比資料和資料。
第一部分:RabbitMQ,ActiveMq,ZeroMq比較
1、 TPS比較 一
ZeroMq 最好,RabbitMq 次之, ActiveMq 最差。這個結論來自於以下這篇文章。
測試環境:
Model: Dell Studio 1749
CPU: Intel Core i3 @ 2.40 GHz
RAM: 4 Gb
OS: Windows 7 64 bits
其中包括持久化訊息和瞬時訊息的測試。注意這篇文章裡面提到的MQ,都是採用預設配置的,並無調優。
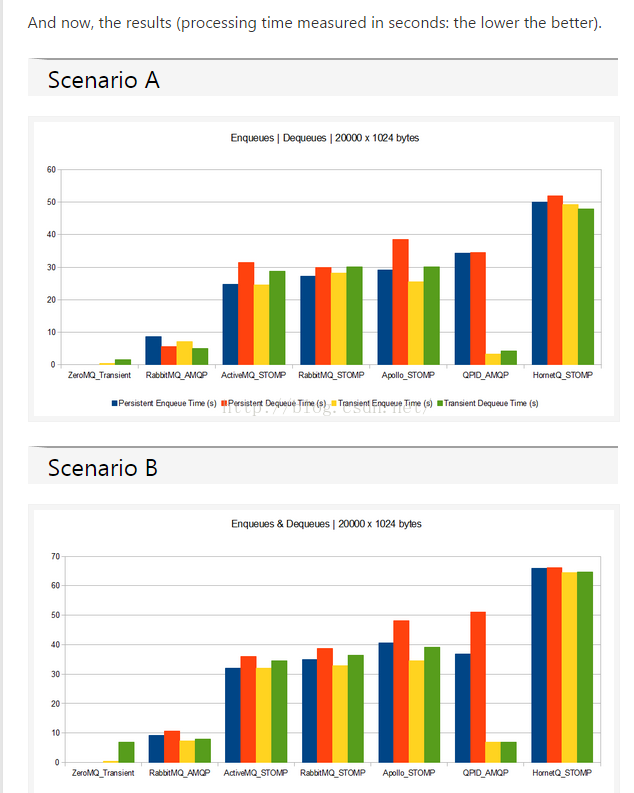
更多的統計圖請參看我提供的文章url。
2、TPS比較二
顯示的是傳送和接受的每秒鐘的訊息數。整個過程共產生1百萬條1K的訊息。測試的執行是在一個Windows Vista上進行的。
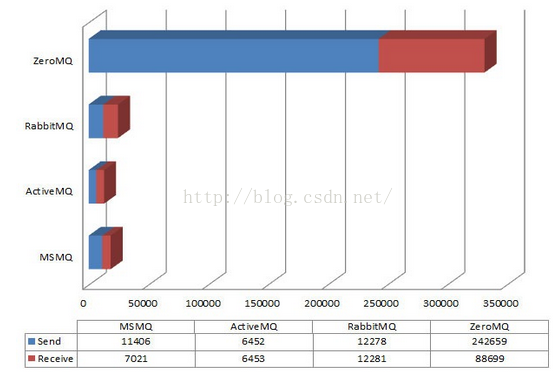
3、持久化訊息比較
zeroMq不支援,activeMq和rabbitMq都支援。持久化訊息主要是指:MQ down或者MQ所在的伺服器down了,訊息不會丟失的機制。
4、技術點:可靠性、靈活的路由、叢集、事務、高可用的佇列、訊息排序、問題追蹤、視覺化管理工具、外掛系統、社群
RabbitMq最好,ActiveMq次之,ZeroMq最差。當然ZeroMq也可以做到,不過自己必須手動寫程式碼實現,程式碼量不小。尤其是可靠性中的:永續性、投遞確認、釋出者證實和高可用性。
所以在可靠性和可用性上,RabbitMQ是首選,雖然ActiveMQ也具備,但是它效能不及RabbitMQ。
5、高併發
從實現語言來看,RabbitMQ最高,原因是它的實現語言是天生具備高併發高可用的erlang語言。
總結:
按照目前網路上的資料,RabbitMQ、activeM、zeroMQ三者中,綜合來看,RabbitMQ是首選。下面提供一篇文章,是淘寶使用RabbitMQ的心得,可以參看一些業務場景。
第二部分:kafka和RabbitMQ的比較
裡面提到的要點:
1、 RabbitMq比kafka成熟,在可用性上,穩定性上,可靠性上,RabbitMq超過kafka
2、 Kafka設計的初衷就是處理日誌的,可以看做是一個日誌系統,針對性很強,所以它並沒有具備一個成熟MQ應該具備的特性
3、 Kafka的效能(吞吐量、tps)比RabbitMq要強,這篇文章的作者認為,兩者在這方面沒有可比性。
這裡在附上兩篇文章,也是關於kafka和RabbitMq之間的比較的:
1、http://www.mrhaoting.com/?p=139
2、http://www.liaoqiqi.com/post/227
總結:
兩者對比後,我仍然是選擇RabbitMq,效能其實是很強勁的,同時具備了一個成熟的MQ應該具有的特性,我們無需重新發明輪子。