
HashMap原始碼及多執行緒併發問題深度分析
以前只知道HashMap是執行緒不安全的,拿來就用,也不會考慮會出現什麼後果,直到最近在學習中終於暴露出了HashMap的短板出來,可又百思不得其解,於是在網上拜讀了若干大牛有關HashMap的分析文章,發現他們其實寫於很早之前,而HashMap的原始碼都已作更新,所以乾脆抽空對HashMap的新版原始碼從頭到尾地梳理了一遍,並寫一篇分析博文幫助學習。 HashMap可以說是Java中最常用的集合類框架之一,是Java語言中非常典型的資料結構,我們總會在不經意間用到它,很大程度上方便了我們日常開發,因此我們更需要去把控好它的脈絡。本文基於Java7的原始碼做剖析,內容有點長,在瀏覽的時候建議通過目錄定位,文章若有不正之處歡迎指出。
好了開刀吧,在進入HashMap的世界之前,我們先來了解一下它的家庭成員:
成員變數
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16,預設初始容量為16,必須為2的冪;
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/ 靜態內部類Holder的原始碼:
/**
* holds values which can't be initialized until after VM is booted.
* 控制一些資料在VM啟動之前不能初始化
*/
private static class Holder {
/**
* Table capacity above which to switch to use alternative hashing.當表容量溢位時使用備用雜湊演算法。
*/
static final int ALTERNATIVE_HASHING_THRESHOLD;
static {
//獲取系統變數jdk.map.althashing.threshold,獲取備用雜湊演算法閾值,預設為-1
String altThreshold = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
"jdk.map.althashing.threshold"));
int threshold;
try {
//初始化閾值
threshold = (null != altThreshold)
? Integer.parseInt(altThreshold)
: ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;
// disable alternative hashing if -1
//如果閾值為-1,則禁用備用雜湊演算法
if (threshold == -1) {
threshold = Integer.MAX_VALUE;
}
if (threshold < 0) {
throw new IllegalArgumentException("value must be positive integer.");
}
} catch(IllegalArgumentException failed) {
throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed);
}
//初始化備用雜湊演算法閾值
ALTERNATIVE_HASHING_THRESHOLD = threshold;
}
}
為了理解Holder這個靜態內部類,可真是在翻了N久的資料,很多文章講到這裡都是直接跳過,本人也是看得雲裡霧裡,怎麼莫名其妙的蹦出這麼個東西,好像在原始碼中也沒多大用處,沒錯,它是沒多大用,至少對於目前的我們這種菜雞來說,因為它涉及到了一種JDK1.7新加入的雜湊演算法:sun.misc.Hashing.stringHash32((String) k),針對String型別的key,提供一個新的hash演算法處理hashcode分佈以減少衝突,這個演算法是不穩定的,還在實驗階段,預設情況下是關閉的,要想啟用這個新特性,需要手動設定jdk.map.althashing.threshold為非負數(預設為-1),這一點可以從Holder原始碼中看出。
There is another change introduced to String class in the same update: a new hashing algorithm. Oracle suggests that a new algorithm gives a better distribution of hash codes, which should improve performance of several hash-based collections: HashMap, Hashtable, HashSet, LinkedHashMap, LinkedHashSet,WeakHashMap and ConcurrentHashMap. Unlike changes from the first part of this article, these changes are experimental and turned off by default.
這有另一個關於String類更新的介紹:一個新的雜湊演算法。Oracle聲稱這個新的雜湊演算法會提供更好的雜湊碼分佈,這將會改善一些基於雜湊碼集合的效能:HashMap,Hashtable,HashSet,LinkedHashMap,LinkedHashSet,WeakHashMap和ConcurrentHashMap。不像文章開頭所說的那個改變,這些改變是實驗性的,預設是關閉的。
As you may guess, these changes are only for String keys. If you want to turn them on, you’ll have to set a jdk.map.althashing.threshold system property to a non-negative value (it is equal to -1 by default). This value will be a collection size threshold, after which a new hashing method will be used. A small remark here: hashing method will be changed on rehashing only (when there is no more free space). So, if a collection was rehashed last time at size = 160 and jdk.map.althashing.threshold = 200, then a method will only be changed when your collection will grow to size of 320 (approximately).
正如你所想那樣,這些新特性只用於String型別的Key。如果你想啟用這個特性,你可以將系統引數
jdk.map.althashing.threshold設定為非負數(預設為-1),這個值將會成為集合大小的閾值,新的雜湊演算法將會在超越閾值時使用。提醒一下:雜湊演算法的只會在重算hash時改變(當沒有多餘空間的時候)。所以,如果一個集合上一次rehash時的大小為160,而jdk.map.althashing.threshold = 200,則新的雜湊演算法將會在集合大小到達320(大概)時啟用。
是不是已經有點感覺了?新的hash演算法的使用只有在rehash中才會用到,而這個Holder靜態內部類,只是載入並初始化ALTERNATIVE_HASHING_THRESHOLD引數而已。有興趣的話可以仔細看一看這篇文章,另外在Stark Overflow裡面也有相關問答。如果還搞不懂,可以先放下以後再看,你只需知道一般情況下,我們不會用到它就是了,要是非要弄個一清二白,非常建議你重複一下我的求索過程,茫茫net中求知去吧~
構造方法:
| Constructor and Description |
|---|
HashMap()Constructs an empty HashMap with the default initial capacity (16) and the default load factor (0.75). 構造一個空的HashMap,預設初始容量為16,預設載入因子為0.75。 |
HashMap(int initialCapacity) Constructs an empty HashMap with the specified initial capacity and the default load factor (0.75).構造一個空的HashMap,指定初始容量,預設載入因子為0.75。 |
HashMap(int initialCapacity, float loadFactor)Constructs an empty HashMap with the specified initial capacity and load factor.構造一個空的HashMap,指定初始容量和載入因子。 |
HashMap(Map<? extends K,? extends V> m)Constructs a new HashMap with the same mappings as the specified Map.構造一個對映關係與指定 Map 相同的 HashMap。 |
在這四個構造方法中,其他三個構造方法都共同呼叫了第三個構造方法:
//其他三種構造方法最後都指向了該構造方法
public HashMap(int initialCapacity, float loadFactor) {
//檢查初始容量是否小於0,是則丟擲異常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//檢查初始容量是否大於預設最大容量值,是則重置為MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//檢查載入因子是否合法
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//指定載入因子
this.loadFactor = loadFactor;
//初始化閾值
threshold = initialCapacity;
//初始化函式,裡面是空的,供子類呼叫
init();
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m);
}下面開始分析HashMap的幾個常用方法的原始碼:
put方法
public V put(K key, V value) {
//檢查是否為空表,是則膨脹容量
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//檢查key是否為null,這個很熟悉吧
if (key == null)
return putForNullKey(value);
//計算key的hash值
int hash = hash(key);
//獲取bucketIndex,即在table中存放的位置
int i = indexFor(hash, table.length);
//取出該索引下的Entry,遍歷單鏈
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//檢查hash碼是否相同,key是否相等
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//該key已存在,取出對應的value並轉移
V oldValue = e.value;
//存入新的value
e.value = value;
//該方法內容為空,供子類重寫所用
e.recordAccess(this);
//返回對應的舊value
return oldValue;
}
}
//記錄表結構修改次數;到了這裡證明,該table中並不存在該key,向表中增加Entry
modCount++;
//增加Entry
addEntry(hash, key, value, i);
//返回空值
return null;
}從原始碼中我們可以看到,put方法進行了如下操作:
1. HashMap是在put操作的時候才開始膨脹的;
2. 然後判斷輸入的key是否為空值,如果為空則呼叫putForNullKey(V)設入空key(原理差不多,但需要注意,空Key都是放在table[0]裡面的);
3. hash(key)獲取雜湊碼;
4. indexFor(hash, table.length)獲取存放位置的索引;
5. 遍歷table[i],檢查是否存在,存在則覆蓋並返回舊值;
6. 不存在,準備修改表結構,先記錄次數;
7. 呼叫addEntry(hash, key, value, i)增加元素。
這裡面涉及到幾個函式,我們依次分析就明白了。
inflateTable :
/**
* Inflates the table.
* 膨脹表容量
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
//將指定的表容量toSize傳入,獲取大於或等於toSize的2的冪值
int capacity = roundUpToPowerOf2(toSize);
//獲取下一次膨脹的閾值;
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//建立指定容量的新表
table = new Entry[capacity];
//初始化雜湊種子作為備用
initHashSeedAsNeeded(capacity);
}為了保證表容量為2的冪,必須將當初初始化threshold時指定的initialCapacity過濾一遍,那為什麼一定要保證容量為2的冪呢?那就是資源浪費和效率的二選一了,而顯然JDK開發人員選擇了後者,後文分析到相關函式時再作介紹。下面是roundUpToPowerOf2(toSize)的原始碼:
roundUpToPowerOf2 :
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
int rounded = number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (rounded = Integer.highestOneBit(number)) != 0
? (Integer.bitCount(number) > 1) ? rounded << 1 : rounded
: 1;
return rounded;
}先來理一下思路:
- 判斷number是否大於
MAXIMUM_CAPACITY,是則返回MAXIMUM_CAPACITY,否則進入第二步; - 獲取nubmer中的1出現的最高位(待會細講)賦給rounded,若rounded等於零,返回1,否則進入第三步;
- 獲取number的1位出現的次數,若大於1,則rounded左移一位 (保證為2的冪),否則rounded為1,返回rounded;
因此不管結果如何,最後該函式返回的都是2的冪值。下面介紹第二步和第三步涉及到的Integer相關函式。
Integer
(已經瞭解了?直接跳過。)
highestOneBit (int)
//該函式實現獲取指定int數的二進位制數中1出現的最高位
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}WTF?!又見位運算,高大上啊有沒有!但是有沒有一臉懵逼的感覺?好吧,快告訴我不是隻有我才這麼無聊去研究這個是怎麼實現的。先來個簡單的4bit運算,假設有個數 i=0110,我們來最笨的方法一位一位的移動:

有沒有看明白?它其實就是通過不斷的右移,再與原數i做或運算,重複以上步驟,得到一個自1的最高位到最低位都是1的數,如上面的0111,然後再拿它來和它的右移1位(無符號右移)得到的值做減運算,從而得到我們最終想要的結果:自1的最高位之後的所有低位都是0的數,如上面的0100。而我們的int的長度始終都是4個位元組,也就是32bit,所以上面要進行31位的右移操作。還有疑惑的話不妨動手試一試就明白了。
bitCount (int)
//該函式實現統計指定int數的二進位制數中1出現的的次數。
public static int bitCount(int i) {
// HD, Figure 5-2
i = i - ((i >>> 1) & 0x55555555);
i = (i & 0x33333333) + ((i >>> 2) & 0x33333333);
i = (i + (i >>> 4)) & 0x0f0f0f0f;
i = i + (i >>> 8);
i = i + (i >>> 16);
return i & 0x3f;
}
這又是什麼鬼?簡直喪心病狂!這裡面用到了“分治”思想(如果不想看的也可以直接跳過本段),要統計32位數中1出現的次數,需要逐步分組並組內求和得到對應位的數,每次分組的位數加倍,以2位一組作為起始統計:
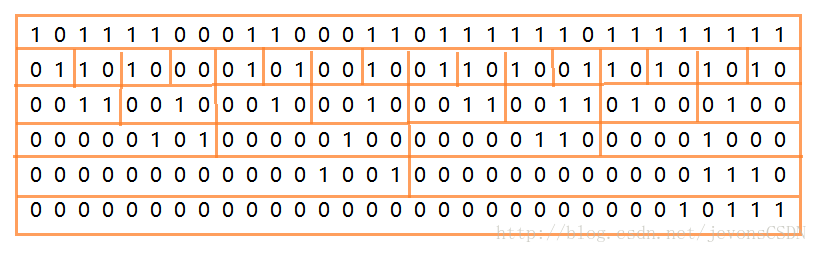
先來分析一下第一行程式碼:i = i - ((i >>> 1) & 0x55555555);
假設有個數 0xBC637EFF:1011 1100 0110 0011 0111 1110 1111 1111
進行第一次分組運算,每2位一組:

可以看出已經達到了我們想要的效果,那開發人員到底是怎麼想到的呢?我也不知道[尷尬],在這裡我就說說我的理解吧。請結合上圖理解下面分析
- (i >>> 1)先將i無符號右移,則每2位中的高位移向低位,我們的目的是在這基礎上再將每2位中的高位置0(此時的高位為原每2位中的低位);
- (i >>> 1)& 0x55555555:將每2位中的高位置0;
此時將出現以下結果:
1011 1100 0110 0011 0111 1110 1111 1111 [i]
0101 0100 0001 0001 0001 0101 0101 0101 [(i>>1)&0x55555555]
對比之下不難發現,上一行減下一行剛好是原數中每2位中1出現的次數。我們拿出最高的2位出來比較就很明顯了:
10
01 :此數的高位永遠為0,而低位則是上一行的高位,上下兩數之差必等於上一行中1出現的次數。
這其實等價於i = (i& 0x55555555) + ((i >>> 1) & 0x55555555),這樣更好理解,把原i和0x55555555相與過濾掉每2位中的高位,這樣就只剩下低位了,而(i >>> 1) & 0x55555555又把高位移到了低位,兩個數相加同樣等於1出現的次數。理解了這個,後面就不難理解了吧,原理都是一樣的。
下面了分析inflateTable(int)函式裡面涉及到的第二個函式:
initHashSeedAsNeeded
/**
* Initialize the hashing mask value. We defer initialization until we
* really need it.
* 初始化雜湊掩碼值。我們延遲初始化它直到我們需要它的時候。
*/
final boolean initHashSeedAsNeeded(int capacity) {
//檢查當前備用雜湊演算法狀態,hashSeed初始值為0
boolean currentAltHashing = hashSeed != 0;
//檢查是否需要啟用備用雜湊演算法
//一般情況下,capacity小於Holder.ALTERNATIVE_HASHING_THRESHOLD,因此該值為false
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
//進行異或判斷,一般情況下為switching為false
boolean switching = currentAltHashing ^ useAltHashing;
//若switching=true,則進行以下操作
if (switching) {
//若useAltHashing=true,返回隨機hashSeed,否則返回0;
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}這個方法用於決定是否啟用新的hash演算法,他被兩個方法所呼叫:
- inflateTable(int toSize)
- resize(int newCapacity)
hash
final int hash(Object k) {
int h = hashSeed;
//檢測hash種子的狀態,決定是否啟用新的hash演算法。
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
//使用舊的雜湊演算法
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
//保證hashCode 不同的演算法,看不懂就隨緣啦,太凶殘了
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}indexFor
/**
* Returns index for hash code h.
* 返回該hashcode在table中對應的索引
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";保證表容量必須為2的冪。
//hashcode在table中對應的索引
return h & (length-1);
}
這裡就是需要保證容量必須為2的冪的原因,因為length為2的冪的話,length-1剛好就是索引範圍:[0,length),形成左閉右開區間,而又恰巧每一個有效位都為1,例如:
Capacity=16
則length=16, 二進位制為0000 0000 0000 0000 0000 0000 0001 0000
lenght-1 =15,二進位制為0000 0000 0000 0000 0000 0000 0000 1111
那麼通過h & (length-1)得到的就是key在表中的索引位置。h & (length-1)與h%length等價不等效,位運算的速度和效率是非常高的,這就是容量必須為2的冪的原因。
接下來就是遍歷Entry單鏈了,這個應該很好理解,Entry是以單鏈的形式存在的,用於解決hash碰撞時的存放問題。最後就是addEntry(),向表中插入元素,內容拉的有點長,可以點下錨點跳至put原始碼整理一下思路,現在再去看應該一目瞭然了吧。接下來基本上沒什麼難度了,讀懂原始碼的表面意思就ok。
addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
//檢查存放元素的數量是否大於或等於閾值,該bucketIndex下的表位置是否不為空
if ((size >= threshold) && (null != table[bucketIndex])) {
//擴容至原來2倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
//重新計算索引
bucketIndex = indexFor(hash, table.length);
}
//容量充足,進入建立Entry操作
createEntry(hash, key, value, bucketIndex);
}resize
//重新調整表容量
void resize(int newCapacity) {
//備份表資料
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//檢查舊錶的容量是否已是最大值,是則終止擴容直接返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//建立空的新表
Entry[] newTable = new Entry[newCapacity];
//轉移表資料,第二個引數決定是否重算hash碼
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//新表覆蓋舊錶
table = newTable;
//計算下一次調整的閾值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}transfer
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍歷table中的Entry
for (Entry<K,V> e : table) {
//遍歷Entry單鏈
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//重新計算索引
int i = indexFor(e.hash, newCapacity);
//置空e.next。將table[i]的空引用賦值給e.next,此時Entry連結串列中只有一個e。
//也就是這裡,會觸發多執行緒併發問題
e.next = newTable[i];
//將e放入新table[i]中;
newTable[i] = e;
//將next連結串列賦值給e,繼續迴圈遍歷。
e = next;
}
}
}這裡的後半部分可能比較難以理解,其實就是先把Entry從一個拖家帶口的家庭裡抽出來,單獨放到新的table中的過程,目的就是想讓表中的元素儘量單獨存在於表中,而不是以多個單鏈的形式存在,從而提高HashMap的效能。畫了個圖助於理解,醜了點,湊合看吧。。。
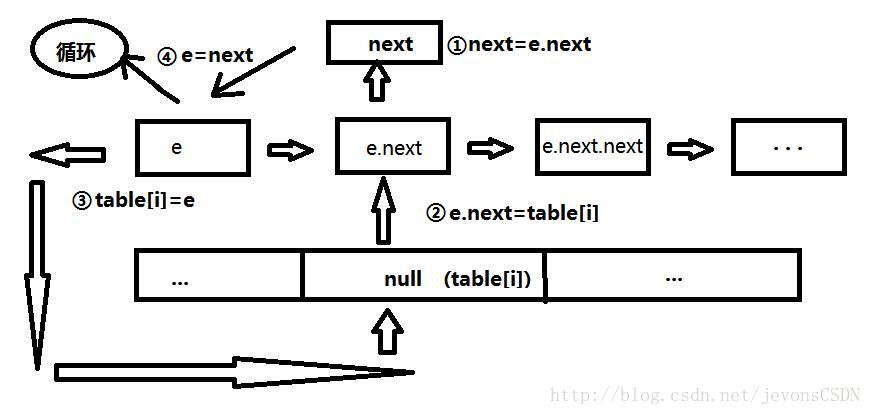
多執行緒併發問題
那麼這就牽扯到了多執行緒併發問題了,我在原始碼註釋中也提到,
e.next =,就是問題所在,這裡將該索引下的Entry元素單鏈處理成單個元素,那麼連結串列之後的元素就是null
newTable[i]
了,而恰巧你在此刻又進行了get操作,又很恰巧你的Entry元素在被處理掉的連結串列中,那麼他get到的還是原table中的資料,自然也就拿不到資料了,就會報空指標異常。最後一句e也是,假如你get的元素恰巧是之前這個e,而此刻e又被next頂掉了,同樣也會報空指標異常。
= next
createEntry
void createEntry(int hash, K key, V value, int bucketIndex) {
//初始化索引為bucketIndex的表位置
Entry<K,V> e = table[bucketIndex];
//初始化Entry,可能會引發多執行緒併發問題
table[bucketIndex] = new Entry<>(hash, key, value, e);
//元素加1
size++;
}多執行緒併發問題
Entry是一個連結串列結構,如果在
new Entry<>(hash, key, value, e)操作中,有兩個執行緒同時在此刻拿到相同的e,那麼這兩個執行緒就會競爭作為e的鏈頭的所有權,勢必會有一個會被覆蓋掉,而在你進行get操作想取被覆蓋掉的entry,那自然也是取不到的,返回空值。
瞭解一下Entry的內部結構:
Entry
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
//體現了entry的連結串列特性
Entry<K,V> next;
int hash;
/**
* Creates new entry.
* 將新new的entry插入到舊entry的鏈頭
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
//省略展示部分方法
}
好了,到這裡我們put方法所涉及到的所有操作都分析完了。下面來分析get方法。
get
public V get(Object key) {
//檢測是否為空key
if (key == null)
return getForNullKey();
//獲取相應的Entry
Entry<K,V> entry = getEntry(key);
//檢查entry是否為空,是則返回null;否則返回對應的value
return null == entry ? null : entry.getValue();
}
getEntry
final Entry<K,V> getEntry(Object key) {
//檢查表中元素數量
if (size == 0) {
return null;
}
//檢測key是否為空,是則返回0;否則返回key的hash碼
int hash = (key == null) ? 0 : hash(key);
//根據hash碼和表長度獲取索引,從table中取出entry
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//檢測hash是否相同,key的記憶體地址是否相等,key是否為null,key的equals方法返回值是否為true(之所以要比較這個是因為可以通過重寫equals實現兩個不同記憶體地址的物件返回true值)。
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//返回entry
return e;
}
return null;
}總結
本文重在梳理HashMap內部實現原理,至於HashMap的多執行緒問題,可以通過以下方式解決:
- 在包含HashMap的方法中實現同步機制,效率太低
- 外部包裝:
Map<K,V> map = Collections.synchronizedMap(new HashMap<K,V>()); - HashTable,效率太低
- 使用JDK1.5中引進的
Concurrent包下的ConcurrentHashMap,相對安全高效,建議使用。我在另一篇文章中也有介紹。
寫在最後
到這裡HashMap的一些常用方法原始碼就分析完了,其中也提到了有關可能引發多執行緒併發問題的所在,摸清了這個資料結構,以後用起來也就胸有成竹了,當然,有興趣的同學也可以嘗試去寫自己的Map結構,在這裡就不再贅述了。相信如果已經理解了上面的內容,那麼閱讀HashMap的其他原始碼並不是什麼難事,加油吧少年!