
Bi的ETL中怎麼做增量處理
1、觸發器方式
觸發器方式是普遍採取的一種增量抽取機制。該方式是根據抽取要求,在要被抽取的源表上建立插入、修改、刪除3個觸發器,每當源表中的資料發生變化,就被相應的觸發器將變化的資料寫入一個增量日誌表,ETL的增量抽取則是從增量日誌表中而不是直接在源表中抽取資料,同時增量日誌表中抽取過的資料要及時被標記或刪除。為了簡單起見,增量日誌表一般不儲存增量資料的所有欄位資訊,而只是儲存源表名稱、更新的關鍵字值和更新操作型別(KNSEN、UPDATE或DELETE),ETL增量抽取程序首先根據源表名稱和更新的關鍵字值,從源表中提取對應的完整記錄,再根據更新操作型別,對目標表進行相應的處理。
例如,對於源表為ORACLE型別的資料庫,採用觸發器方式進行增量資料捕獲的過程如下:
這樣,對錶T的所有DML操作就記錄在增量日誌表DML_LOG中,注意增量日誌表中並沒有完全記錄增量資料本身,只是記錄了增量資料的來源。進行增量ETL時,只需要根據增量日誌表中的記錄情況,反查源表得到真正的增量資料。
SQL程式碼
(1)建立增量日誌表DML_LOG:
CREATE TABLE DML_LOG(
ID NUMBER PRIMARY KEY, //自增主鍵
TABLE NAME VARCHAR2(200). //源表名稱
RECORD ID NUMBER, //源表增量記錄的主鍵值
DML TYPE CH根(1)。∥增量型別,I表示新增:U表示更新;D表示刪除
EXECUTE DATE DATE //發生時間
);
(2)為DML_LOG建立一個序列SEQ_DML_LOG上,以便觸發器寫增量日誌表時生成ID值。
(3)針對要監聽的每一張表,建立一個觸發器,例如對錶TEST建立觸發器如下:
CREATE OR REPLACE TRIGGER T BEFORE INSERT OR UPDATE
OR DELETE ON T FOR EACH ROW
DECLARE 1 DML TYPE VARCHAR2(1);
BEGIN
IF INSERTING THEN L_DML TYPE:= I’;
ELSIF UPDATING THEN I_DML_TYPE:=。TY;
ELSIF DELETING THEN L_DML_TYPE:= D’;
ENDIF;
IF DELETING THEN
INSERT INTO DML_LOG(ID,TABLE_NAME,RECORD—
ID,EXECUTE_DATE,DMLJYPE)
VALUES(SEQ_DML_LOG.NEXTVAL,’TEST ,:OLD.ID,SYSDATE,
L_DML_TYPE);
ELSE
INSERT INTO DML_LOG(ID,TABLE_NAME,RECORD_
ID,EXECUTE_DATE,DMLJYPE)
VALUES(SEQ_DML_LOG.NEXTVAL,。TEST ,:NEW.ID,SYSDATE,L
TIROL_TYPE);
ENDIF;
END;
2、時間戳方式
時間戳方式是指增量抽取時,抽取程序通過比較系統時間與抽取源表的時間戳欄位的值來決定抽取哪些資料。這種方式需要在源表上增加一個時間戳欄位,系統中更新修改表資料的時候,同時修改時間戳欄位的值。有的資料庫(例如SQL SERVER)的時間戳支援自動更新,即表的其它欄位的資料發生改變時,時間戳欄位的值會被自動更新為記錄改變的時刻。在這種情下,進行ETL實施時就只需要在源表加上時間戳欄位就可以了。對於不支援時間戳自動更新的資料庫,這就要求業務系統在更新業務資料時,通過程式設計的方式手工更新時間戳欄位。使用時間戳方式可以正常捕獲源表的插入和更新操作,但對於刪除操作則無能為力,需要結合其它機制才能完成。
更新時間戳:
3、全表刪除插入方式
全表刪除插入方式是指每次抽取前先刪除目標表資料,抽取時全新載入資料。該方式實際上將增量抽取等同於全量抽取。對於資料量不大,全量抽取的時間代價小於執行增量抽取的演算法和條件代價時,可以採用該方式。
4、全表比對方式
全表比對即在增量抽取時,ETL程序逐條比較源表和目標表的記錄,將新增和修改的記錄讀取出來。優化之後的全部比對方式是採用MD5校驗碼,需要事先為要抽取的表建立一個結構類似的MD5臨時表,該臨時表記錄源表的主鍵值以及根據源表所有欄位的資料計算出來的(BI)
MD5校驗碼,每次進行資料抽取時,對源表和MD5臨時表進行MD5校驗碼的比對,如有不同,進行UPDATE操作:如目標表沒有存在該主鍵值,表示該記錄還沒有,則進行INSERT操作。
然後,還需要對在源表中已不存在而目標表仍保留的主鍵值,執行DELETE操作。
5、日誌表方式
對於建立了業務系統的生產資料庫,可以在資料庫中建立業務日誌表,當特定需要監控的業務資料發生變化時,由相應的業務系統程式模組來更新維護日誌表內容。增量抽取時,
通過讀日誌表資料決定載入哪些資料及如何載入。日誌表的維護需要由業務系統程式用程式碼來完成。
6、系統日誌分析方式
該方式通過分析資料庫自身的日誌來判斷變化的資料。關係犁資料庫系統都會將所有的DML操作儲存在日誌檔案中,以實現資料庫的備份和還原功能。ETL增暈抽取程序通過對資料庫的日誌進行分析,提取對相關源表在特定時間後發生的DML操作資訊,就可以得知自上次抽取時刻以來該表的資料變化情況,從而指導增量抽取動作。有些資料庫系統提供了訪問日誌的專用的程式包(例如ORACLE的LOGMINDER),使資料庫日誌的分析工作得到大大簡化。
、特定資料庫方式(ORACLE)
以下介紹常見的針對特有資料庫系統的增景抽取方式。
7.1 ORACLE改變資料捕獲(CHANGEDDATACAPTURE,CDC)方式:ORACLECDC特性是在ORAELE9I資料庫中引入的。CDC能夠幫助識別從上次抽取之後發生變化的資料。
利用CDC,在對源表進行INSERT、UPCLATE或DELETE等操作的同時就可以提取資料,並且變化的資料被儲存在資料庫的變化表中。這樣就可以捕獲發生變化的資料,然後利用資料庫檢視以一種可控的方式提供給ETL抽取程序,作為增量抽取的依據。CDC方式對源表資料變化情況的捕獲有兩種方式:同步CDC和非同步CDC。同步CDC使用源資料庫觸發器來捕獲變更的資料。這種方式是實時的,沒有任何延遲。當DML操作提交後,變更表中就產生了變更資料。非同步CDC使用資料庫重做日誌(REDOLOG)檔案,在源資料庫發生變更以後,才進行資料捕獲。
7.2 ORACLE閃回查詢方式:ORACLE9I以上版本的資料庫系統提供了閃回查詢機制,允許使用者查詢過去某個時刻的資料庫狀態。這樣,抽取程序可以將源資料庫的(BI)
當前狀態和上次抽取時刻的狀態進行對比,快速得出源表資料記錄的變化情況。
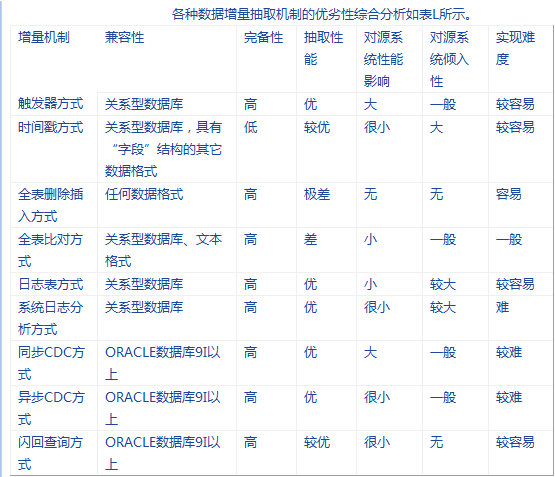
8、比較和分析
可見,ETL在進行增量抽取操作時,有以上各種機制可以選擇。現從相容性、完備性、效能和侵入性3個方面對這些機制的優劣進行比較分析。資料抽取需要面對的源系統,並不一定都是關係型資料庫系統。某個ETL過程需要從若干年前的遺留系統中抽取EXCEL或者CSV文字資料的情形是經常發牛的。這時,所有基於關係型資料庫產品的增量機制都無法工作,時間戳方式和全表比對方式可能有一定的利用價值,在最壞的情況下,只有放棄增量抽取的思路,轉而採用全表刪除插入方式。完備性方面,時間戳方式不能捕獲DELETE操作,需要結合其它方式一起使用。增量抽取的效能因素表現在兩個方面,一是抽取程序本身的效能,二是對源系統性能的負面影響。觸發器方式、日誌表方式以及系統日誌分析方式由於不需要在抽取過程中執行比對步驟,所以增量抽取的效能較佳。全表比對方式需要經過複雜的比對過程才能識別出更改的記錄,抽取效能最差。在對源系統的效能影響方面,觸發器方式由於是直接在源系統業務表上建立觸發器,同時寫臨時表,對於頻繁操作的業務系統可能會有一定的效能損失,尤其是當業務表上執行批量操作時,行級觸發器將會對效能產生嚴重的影響;同步CDC方式內部採用觸發器的方式實現,也同樣存在效能影響的問題;全表比對方式和日誌表方式對資料來源系統資料庫的效能沒有任何影響,只是它們需要業務系統進行額外的運算和資料庫操作,會有少許的時間損耗;時間戳方式、系統日誌分析方式以及基於系統日誌分析的方式(非同步CDC和閃回查詢)對資料庫效能的影響也是非常小的。對資料來源系統的侵入性是指業務系統是否要為實現增抽取機制做功能修改和額外操作,在這一點上,時間戳方式值得特別關注該方式除了要修改資料來源系統表結構外,對於不支援時間戳欄位自動更新的關係型資料庫產品,還必須要修改業務系統的功能,讓它在源表T執行每次操作時都要顯式的更新表的時間戳欄位,這在ETL實施過程中必須得到資料來源系統高度的配合才能達到,並且在多數情況下這種要求在資料來源系統看來是比較“過分”的,這也是時間戳方式無法得到廣泛運用的主要原因。另外,觸發器方式需要在源表上建立觸發器,這種在某些場合中也遭到拒絕。還有一些需要建立臨時表的方式,例如全表比對和日誌表方式。可能因為開放給ETL程序的資料庫許可權的限制而無法實施。同樣的情況也可能發生在基於系統日誌分析的方式上,因為大多數的資料庫產品只允許特定組的使用者甚至只有DBA才能執行日誌分析。閃回查詢在侵入性方面的影響是最小的.
在我從事的ETL工作中,大部分都是採用時間戳方式進行增量抽取,如銀行業務,VT新開戶,使用時間戳方式,可以在固定時間內,組織人員進行資料抽取,進行整合後,載入到目標系統。而觸發器方式,雖然可以自動進行抽取,但是執行頻率過多,影響效率!第三種方式對於大資料量來說是非常不可取的,尤其是對於一些銀行、電信行業,因為資料全量比較大,所以進行增量校對是比較耗時的,總起來說,個人趨向使用時間戳方式進行增量抽取,當然具體情況要看工作的使用環境!
==============================================================================================================
時間戳方式的增量:
這個實驗主要思想是在建立資料庫表的時候,
通過增加一個額外的欄位,也就是時間戳欄位,
例如在同步表 tt1 和表 tt2 的時候,
通過檢查那個表是最新更新的,那個表就作為新表,而另外的表最為舊錶被新表中的資料進行更新。
實驗資料如下:
mysql database 5.1
test.tt1( id int primary key , name varchar(50) );
mysql.tt2( id int primary key, name varchar(50) );
快照表,可以將其存放在test資料庫中,
同樣可以為了簡便,可以將其建立為temporary 表型別。
資料如圖 kettle-1

kettle-1
============================================================
主流程如圖 kettle-2

kettle-2
在prepare中,向 tt1,tt2 表中增加 時間戳欄位,
由於tt1,tt2所在的資料庫是不同的,所以分別建立兩個資料庫的連線。
prepare

kettle-3
在執行這個job之後,就會在資料庫查詢的時候看到下面的欄位:

kettle-4
然後, 我們來對tt1表做一個 insert 操作 一個update操作吧~

kettle-5
在原表上無論是insert操作還是update操作,對應的updateTime都會發生變更。
如果tt1 表 和 tt2 表中 updateTime 欄位為最新時間的話,則說明該表是新表 。
下面只要是對應main_thread的截圖:

kettle-6
在這裡介紹一下Main的層次:
Main
START
Main.prepare
Main.main_thread
{
START
main_thread.create_tempTable
main_thread.insert_tempTable
main_thread.tt1_tt2_syn
SUCCESS
}
Main.finish
SUCCESS
在main_thread中的過程是這樣的:
作為一個區域性的整體,使它每隔200s內進行一次迴圈,
這樣的話,如果在其中有指定的表 tt1 或是 tt2 對應被更新或是插入的話,
該表中的updateTime欄位就會被捕捉到,並且進行同步。
如果沒有更新出現,則會走switch的 default 路線對應的是write to log.
繼續迴圈。
首先建立一個快照表,然後將tt1,tt2表中的最大(最新)時間戳的值插入到快照表中。
然後,通過一個transformation來判斷那個表的updateTime值最新,
來選擇對應是 tt1表來更新 tt2 還是 tt2 表來更新 tt1 表;
main_thread.create_tempTable.JOB:

main_thread.insert_tempTable.Job:

PS: 對於第二個SQL 應該改成(不修改會出錯的)
set @var1 = ( select MAX(updatetime) from tt2);
insert into test.temp values ( 2 , @var1 ) ;
因為conn對應的是連線mysql(資料庫例項名稱),
但是我們把快照表和tt1 表都存到了test(資料庫例項名稱)裡面。
在上面這個圖中對應的語句是想實現,在temp表中插入兩行記錄元組。
其中id為1 的元組對應的temp.lastTime 欄位 是 從tt1 表中選出的 updateTime 值為最新的,
id 為2的元組對應的 temp.lastTime 欄位 是 從 tt2 表中選出的 updateTime 值為最新的 欄位。
當然 , id 是用來給後續 switch 操作提供參考的,用於標示最新 updateTime 是來自 tt1 還是 tt2,
同樣也可以使用 tableName varchar(50) 這種欄位 來存放 最新updateTime 對應的 資料庫.資料表的名稱也可以的。
main_thread.tt1_tt2_syn.Transformation:

首先,建立連線 test 資料庫的 temp 表的連線,
選擇 temp表中 對應 lastTime 值最新的所在的記錄
所對應的 id 號碼。
首先將temp中 lastTime 欄位進行 降序排列,
然後選擇id , 並且將選擇記錄僅限定成一行。

然後根據id的值進行 switch選擇。
在這裡LZ很想使用,SQL Executor,
但是它無法返回對應的id值。
但是表輸入可以返回對應的id值,
並被switch接收到。

下圖是對應 switch id = 1 的時候:即 tt1 更新 tt2
注意合併行比較 的新舊資料來源 的選擇
和Insert/Update 中的Target table的選擇

下圖是對應 switch id = 2 的時候:即 tt2 更新 tt1
注意合併行比較 的新舊資料來源 的選擇
和Insert/Update 中的Target table的選擇

但是考慮到增加一個 column 會浪費很多的空間,
所以咋最終結束同步之後使用 finish操作步驟來將該 updateTime這個欄位進行刪除操作即可。
這個與Main中的prepare的操作是相對應的。
Main.finish

這樣的話,實驗環境已經搭建好了,
接下來進行,實驗的資料測試了,寫到下一個部落格中。
當然,觸發器也是一種同步的好方法,寫到後續部落格中吧~
時間戳的方式相比於觸發器,較為簡單並且通用,
但是 資料庫表中的時間戳欄位,很費空間,並且無法對應刪除操作,
也就是說 表中刪除一行記錄, 該表應該作為新表來更新其餘表,但是由於記錄刪除 時間戳無所依附所以無法記錄到。